java多线程那点事儿
前段时间应隔壁部门大佬的邀约,简单地帮他们部门的童靴梳理了下多线程相关的内容,客串了一把讲师【因为部门内有不少是c#转java的童鞋,所以讲的稍微浅显了些】
ok,按照个人习惯先来大纲
知识点:
1)进程 多线程的相关概念 涉及到CPU调度 稍微谈下JVM内存模型 程序计数器
2)多线程的三种实现手段及其代码实现 这边可以谈下futurtask的底层源码
3)常用锁概念及实现说明 隐式锁 显式锁 乐观锁 悲观锁 CAS 可重入锁 不可重入锁 读写锁 线程安全 引申的谈下分布式锁 及分布式锁的原理,常用的三种实现手段 volatile关键字及其底层源码
4)线程池的概念,线程池的使用 扒一扒线程池的源码 缓存队列 核心线程池 线程池创建任务的过程 线程池的生命周期等
多线程: 多线程是什么? 多线程是一个程序(进程)运行时产生了不止一个线程。
进程和线程区别 一个正在执行的程序,进程是控制程序的执行顺序。这个顺序又被称为一个控制单元。
并行和并发的概念: 并行:多个CPU实例或者多台机器同时执行一段处理逻辑 并发:通过CPU调度算法,让用户看上去是同时执行的,在CPU层面不是同时。
这边衍生的可以谈下JVM中内存模型的程序计数器 就是记录java执行字节码的行号指示器。
jvm内存模型: 线程私有:
程序计数器:记录程序执行过程中的字节码的行号指示器
java虚拟机栈: 主要是是被调用的java方法代表的是一个个栈帧 局部变量表 操作数栈 动态链接 方法出口等等 java.lang.StackOverflowError
本地方法栈: 主要是是被调用的native方法代表的是一个个栈帧
线程公有
堆 : 对象实例
方法区:最重要的就是运行时常量池 gc
为什么要是用多线程:
1)充分的利用CPU资源,如果只有一个线程的话,第二个任务必须等第一个任务完成之后才能进行。
2)进程之间无法共享数据,但是线程可以
3)创建进程需要为这个进程分配系统资源,创建线程的代价小
多线程的实现手段【3种手段】
1)Thread
package com.Allen.test;
import java.util.concurrent.TimeUnit;
public class testThread extends Thread{
public static void main(String[] args) {
testThread t1=new testThread();
testThread t2=new testThread();
t1.start();
t2.start();
}
public void run(){
System.out.println("start");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end");
}
}
复制代码
2)runnable
package com.Allen.test;
import java.util.concurrent.TimeUnit;
public class testRunnable {
public static void main(String[] args) {
testAllen th1=new testAllen();
for(int i=0;i<5;i++){
Thread t1=new Thread(th1);
t1.start();
}
}
}
class testAllen implements Runnable{
@Override
public void run() {
System.out.println("start");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end");
}
}
复制代码
3)future callable
package com.Allen.test;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;
public class testFuture {
public static void main(String[] args) throws InterruptedException, ExecutionException {
futureTask task=new futureTask();
// //线程池 单线程的线程池
// ExecutorService service=Executors.newCachedThreadPool();
// Future<Integer> future=service.submit(task);
// //说到下面这个方法就要说起线程池的状态 四个种状态
// service.shutdown();
FutureTask<Integer>future=new FutureTask<>(task);
Thread t1=new Thread(future);
t1.start();
System.out.println("run task ....");
TimeUnit.SECONDS.sleep(1);
System.out.println("result : "+future.get());
}
}
class futureTask implements Callable<Integer>{
@Override
public Integer call() throws Exception {
TimeUnit.SECONDS.sleep(2);
int result=0;
//模拟一个庞大的计算
for(int i=0;i<100;i++){
for(int j=0;j<i;j++){
result+=j;
}
}
return result;
}
}
复制代码
扒一扒futureTask的源码
首先我们看run方法
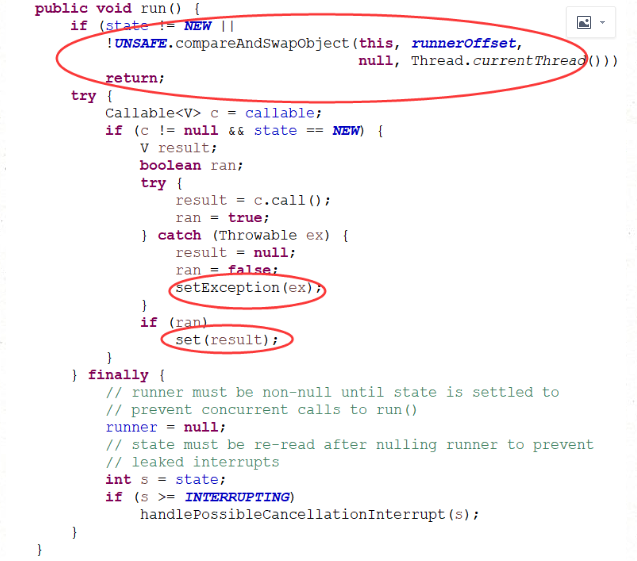
1)run方法中state不是new或者线程再次给他设置启动出错直接让他return掉
2)完后方法后调用set方法 把结果赋值给outcome
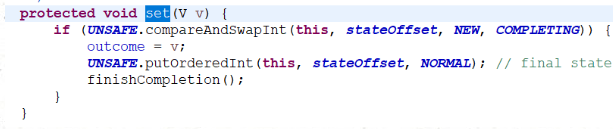
这边用了CAS方式来设置stat状态
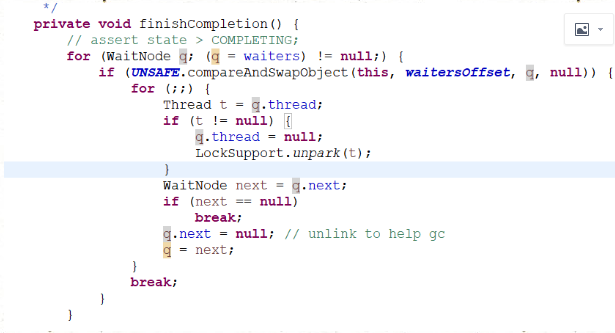
拿到栈顶的元素一个个去唤醒

报错的话返回异常信息
接下来我们谈下多线程操作中比较核心的东西
多线程操作共享变量的问题
锁机制
最常用的锁机制 synchronized及lock
隐式锁 synchronized 谈下底层原理
显示锁 lock
重入锁
我设计了一个实例来直观的观察多线程操作共享变量的线程安全问题
package com.Allen.test;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
public class TestSynchronized {
public static void main(String[] args) throws InterruptedException {
for (int s = 0; s < 10; s++) {
Person person = new Person();
person.setAge(0);
ReentrantLock lock = new ReentrantLock();
for (int i = 0; i < 100; i++) {
Thread t1 = new Thread(new test111(person,lock));
t1.start();
}
TimeUnit.SECONDS.sleep(3);
System.out.println(person.getAge());
}
}
}
class test111 implements Runnable {
Person person;
ReentrantLock lock;
public test111(Person person,ReentrantLock lock) {
this.person = person;
this.lock=lock;
}
public void run() {
// synchronized (person) {
// person.setAge(person.getAge() + 1);
// }
lock.lock();
person.setAge(person.getAge() + 1);
lock.unlock();
//person.setAge(person.getAge()+1);
}
}
复制代码
悲观锁 乐观锁 CAS
一 悲观锁
在关系型数据库管理系统中,悲观并发控制(悲观锁)是一种并发控制的方法。 简单而言,就是它“悲观”地默认每次拿数据都认为别人会修改,所以在每次拿之前去上锁,这样别人想拿这个数据就会block直到它拿到锁。传统悲观锁实现机制大多利用数据库提供的锁机制(也只有数据库层面提供的锁机制才能真正保证了数据访问的排他性)。
悲观锁流程如下:
1 对任意记录进行修改之前,尝试给它加排它锁。
2 若是加锁失败,说明该记录正在修改,那么当前需要等待或者抛出异常。
3 如果成功加锁,那么就可以对记录进行修改,事务完成之后解锁。
4 期间其他人需要对该记录进行修改或者加排查锁操作,就不许等待我们解锁或者直接抛出异常。
以mysql为例
使用悲观锁,先关闭mysql的自动提交属性。
set autocommit=0
begin;
select status from t_goods where id=1 for update;
insert into t_orders(id,goods_id)values(null,1);
update t_goods set status=2;
commit;
发起事务 操作 提交事务
select for update 开启排它锁方式实现悲观锁,mysql InnoDB默认行级锁【ps:注意一点,行级锁都是基于索引,如果用不到索引会使用表级锁吧整张表锁住】
优点与缺点:
悲观并发控制实现上是“先取锁再访问”的保守策略,为数据安全提供保障,但是牺牲了效率,处理加锁会让数据库产生额外的开销,还增加了死锁的机会,降低了并行性,如果一个实物锁定了某行数据,其他事物必须等待改事务处理完才能处理那一行。适用于状态修改非常高,冲突非常严重的系统。
二 乐观锁
假设了多用户并发事务处理下不会彼此影响,各事务在不产生锁的情况下处理各自的那部分数据,
每次去拿数据都认为别人不会修改,所以不会上锁,只会在更新的时候判断一下此期间别人有没有更新这个数据。如果有其他事务更新的话,正在提交的事务会回滚。
一般来说乐观锁不会使用数据库提供的机制,我们通常采用记录数据版本来实现乐观锁 记录的方式有版本号或者时间戳。
在数据初始化的时候指定一个版本号,每次对数据更新在对版本号做+1操作,并判断当前的版本号是不是该数据的最新版本。
优点与缺点;
乐观并发控制事务之间数据竞争概率较小,可以一直做下去知道提交才会锁定,有点类似于svn
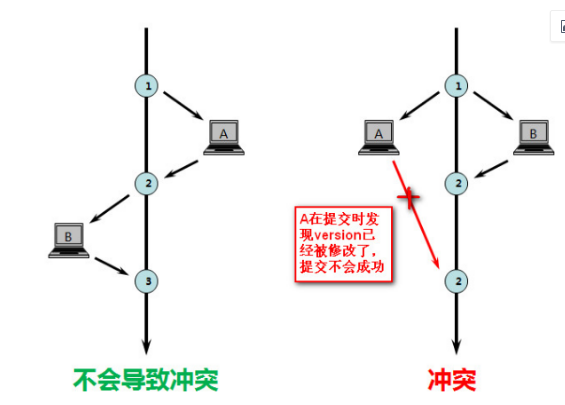
当俩个事务都读到某一行修改回传数据库就会遇到问题。
三 CAS 无锁化编程
java.util.concurrent包中借助CAS实现了区别于synchronouse同步锁的一种乐观锁。 无锁化编程
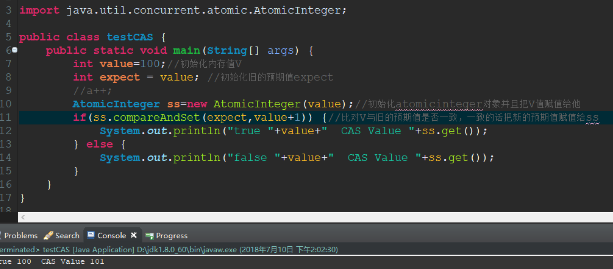
CAS有三个操作数,内存值V,旧的预期值A,修改的新值B。当且仅当预期值A与内存值V相同时,将内存值V修改为B,否则什么都不做。
优点与缺点: 可以用CAS在无锁的情况下实现原子操作,但要明确应用场合,非常简单的操作且又不想引入锁可以考虑使用CAS操作,当想要非阻塞地完成某一操作也可以考虑CAS。 CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作
-
ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。 从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。 关于ABA问题参考文档: blog.hesey.net/2011/09/res…
-
循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
compareAndSet有点类似于如下
if (this == expect) {
this = update
return true;
} else {
return false;
}
如下附上CAS实例
volatile关键字 但是我们要思考下并发编程下的俩个关键问题?
1 线程之间是如何通信
1.1 共享内存
隐式通信
1.2 消息传递
显式通信
2 线程之间是如何同步
在共享内存的并发模型中,同步是显示做的,synchronized
在消息传递的并发模型,由于消息的发送必须要在消息的接受之前,所以同步是隐式的。
2 定位内存可见性问题:
什么对象是内存共享的,什么不是。
主内存:共享变量
私有本地内存:存储共享变量的副本
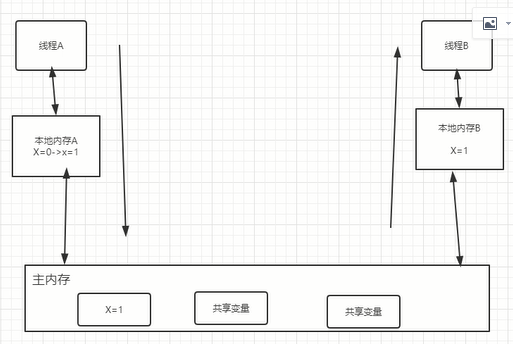
可见性原理
1 volatile声明的变量进行写操作的时候,jvm会向处理器发送一条lock前缀的指令,会把这个变量所在缓存行的数据回到系统内存。
2 在多处理器的情况下,保证各个处理器缓存一致性的特点,就会实现缓存一致性协议。
synchronized :可重入锁,互斥性,可见性。
volatile:原子性,可见性。不能做到复合操作的原子性。性能开销更小。
synchronized 线程A释放锁之后会把本地内存的变量同步到主内存
线程B获取锁的时候会把主内存的共享变量同步到本地内存中。
调用monitorenter monitorexit
对象同步方法调用的时候必须要获取到它的监视器,用完之后会释放。
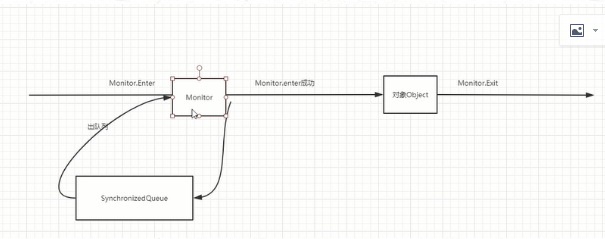
获取不到监听器会放在队列中。
多进程下访问共享变量
分布式锁 包括三种常用的使用手段
1 ) 通过数据库的方式
create table lock(
ID
Method_Name 唯一约束
)
每次去操作文件的是否,都去插入表,获取锁是否才能去操作文件,
等锁释放【删除这个记录】才能insert
缺点:
删除失败 【等待程序不可用】
重入锁【可以对进程进行编号,来判断重入】
2) 使用zookeeper
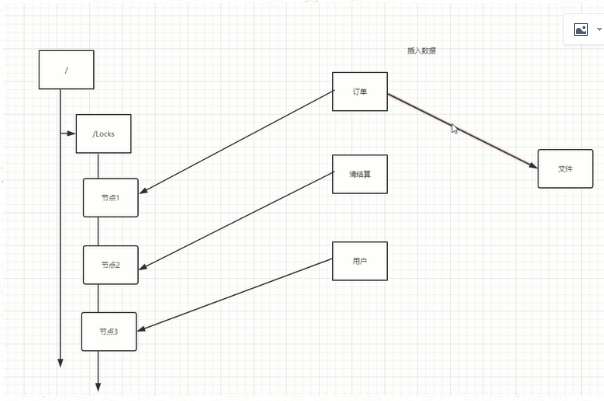
临时有序节点
谁先写到节点上,获取锁
有个watch机制,会判断节点是否失效,失效之后会读取下一个节点
3) redis
setnx
谁先set这个值,谁就现获取锁
后续set失败的就是没有获取锁
等待锁释放之后你才能set这个值。
线程池
线程池种类及区别:
运行executors类给我们提供静态方法调用不同的线程池
newsingleThreadExecutor:
返回一个单线程的executor,将多个任务交给这个Executor时,这个线程处理完一个任务之后接着处理下一个任务,若该线程出现异常,将会有一个新的线程替代。
newFixedThreadPool
返回一个包含指定数目线程的线程池,任务数量多于线程数目,则没有执行的任务必须等待,直到任务完成。
newCahedThreadPool
根据用户的任务数创建相应的线程数来处理,该线程池不会对线程数加以限制,完全依赖于JVM能创建的线程数量,可能引起内存不足。
用法如下:
package com.Allen.TestPoolSize;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
//单线程化的线程池
ExecutorService service1=Executors.newSingleThreadExecutor();
service1.execute(new Runnable() {
@Override
public void run() {
System.out.println("aaa");
}
});
//可缓存线程池
ExecutorService service2=Executors.newCachedThreadPool();
service2.execute(new Runnable() {
public void run() {
System.out.println("bbb");
}
});
//定长线程池
ExecutorService service3=Executors.newFixedThreadPool(3);
service3.execute(new Runnable() {
public void run() {
System.out.println("ccc");
}
});
//定长线程池支持定时和周期任务
ScheduledExecutorService service4=Executors.newScheduledThreadPool(5);
service4.schedule(new Runnable() {
@Override
public void run() {
System.out.println("ddd");
}
}, 3, TimeUnit.SECONDS);
}
}
复制代码
过程 原理
扒一扒源码
首先我们写一个test类
package com.Allen.studyThread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class test {
public static void main(String[] args) {
ExecutorService threadpool=Executors.newFixedThreadPool(3);
for(int i=0;i<10;i++){
threadpool.submit(new testrunnable("allen_"+i));
}
threadpool.shutdown();
}
}
class testrunnable implements Runnable{
private String name;
public testrunnable(String name){
this.name=name;
}
public void run() {
System.out.println(name+" start...");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(name+" end...");
}
}
复制代码
看线程池源码,我们入口从newFixedThreadPool入口入,我们看看他初始化做了什么 进入到Executors类的newFixedThreadPool方法传入一个参数
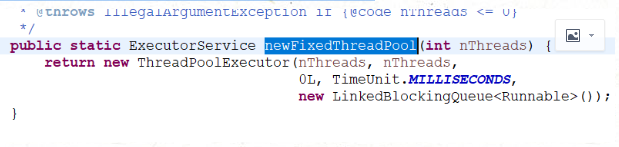
这个参数是线程池并发执行的线程数量
例如50个任务,10个多线程,分五次执行,传入的参数就是10。
由上面的方法可以看到,它是实例化了ThreadPoolExecutor类
继承关系 Executor---Executorservice--abstractExecutorservice--Threadpoolexecutor 注意这个就是我们需要学习线程池的核心类,这里面传入了5个参数。
我们进去看下:

这边涉及到几个核心的参数:
1)corepoolsize
2)maximumpoolsize
3)keepalivetime
4)workqueue
5)threadfactory
重要参数及其作用
corepoolsize:核心池大小,默认情况下,创建了线程池之后,线程池中数量为0,当任务进来之后会创建一个线程去执行任务,当线程池中的线程数到达corepoolsize之后会把任务添加到缓存队列中。
maximumpoolsize:线程池中最多可以创建多少线程。
keepalivetime:线程没有任务执行,最多保存多久会终止。当线程池中线程数大于corepoolsize,这个机制才会生效。
workqueue:阻塞队列,用来存放等待被执行的任务。
threadfactory:线程工厂,用来创建线程。
线程池状态
1 当线程池被创建后,初始状态为running
2 调用shutdown方法之后,处于shutdown状态,不接受新的任务,等待已有任务完成。
3 调用shutdownnow方法之后,进入stop状态,不接受新任务,并且尝试终止正在执行的任务。
4 处于shutdown或者stop状态,并且所有工作线程均被销毁,任务缓存队列被清空,线程池就被设置为terminated状态。
任务提交到线程池的具体操作
1 当前线程池中的线程数小于corepoolsize,则把任务创建为线程执行。
2 当前线程池中的线程数大于等于corepoolsize,则尝试把任务添加到缓存队列,添加成功之后,则此任务会等待空闲线程来执行此任务,如果添加失败,则尝试创建线程去执行这个任务。
3 当前线程池中线程数大于等于macimumpoolsize,则采取拒绝策略(4种拒绝策略)
3.1 abortpolicy丢弃任务,抛出rejectedExecutionExceptipon
3.2 discardpolicy 拒绝执行,不抛出异常
3.3 discardoldpolicy 丢弃任务缓存队列中最老的任务,并且尝试重新提交新任务
3.4 callerrunspolicy 有反馈机制,让任务提交的速度变慢
然后我们看下他的submit方法
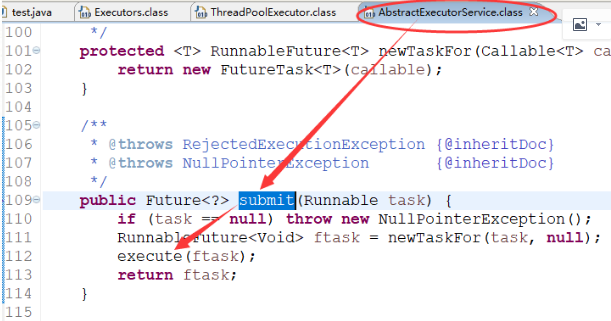
它其实调用的是execute方法
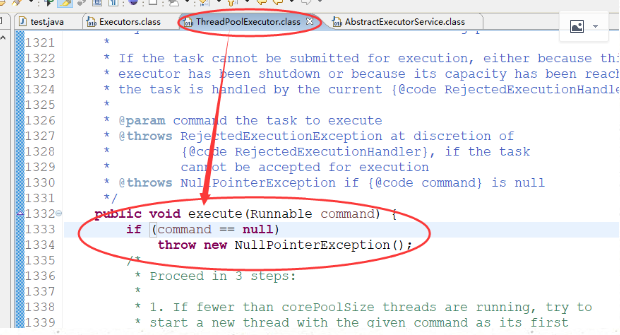
核心方法如下:
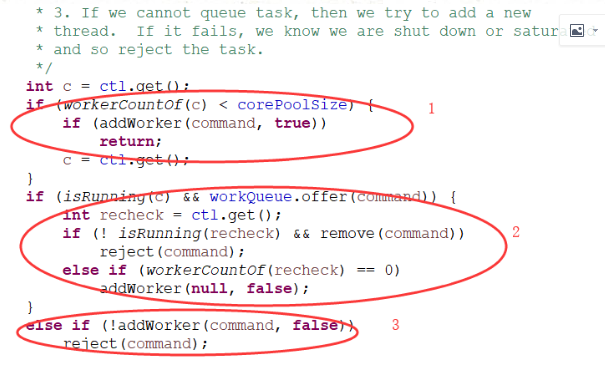
1)判断运行的线程数量小于核心线程数,小于的话直接加入worker启动
2)判断运行线程数量大于核心线程数,上面if分支针对大于corepoolsize,并且缓存队列加入任务操作成功的情况,运行中并且把任务加入缓冲队列成功,正常而言这样就完成了处理逻辑
为了保险起见,增加了状态出现异常的判断,如果异常,就会继续remove操作,结果为true的话,就按照拒绝策来拒绝
3)运行线程数大于corepoolsize并且缓冲队列也已经满了
这边addworker传递的是false,意味着它会去判断maximumpoolsize
使用拒绝策略
我们主要看增加工作线程的流程
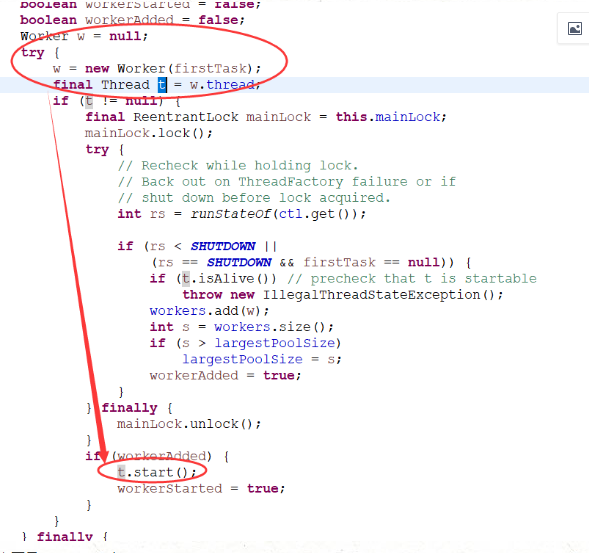
主要是runworker 中
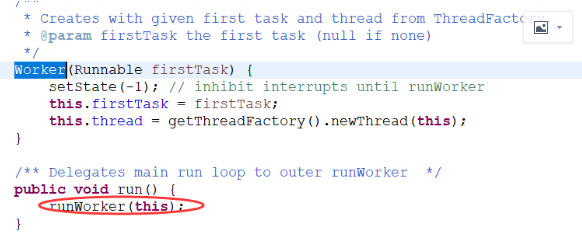
执行任务,并且当执行完毕之后再去获取新的task继续执行,gettask方法是有ThreadPoolExecutor这个方法提供
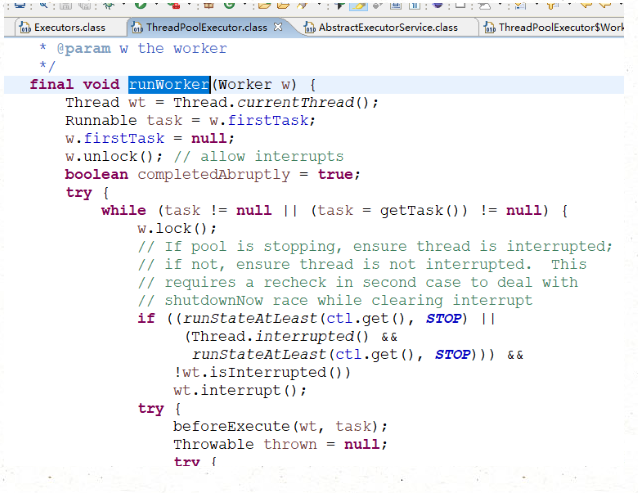
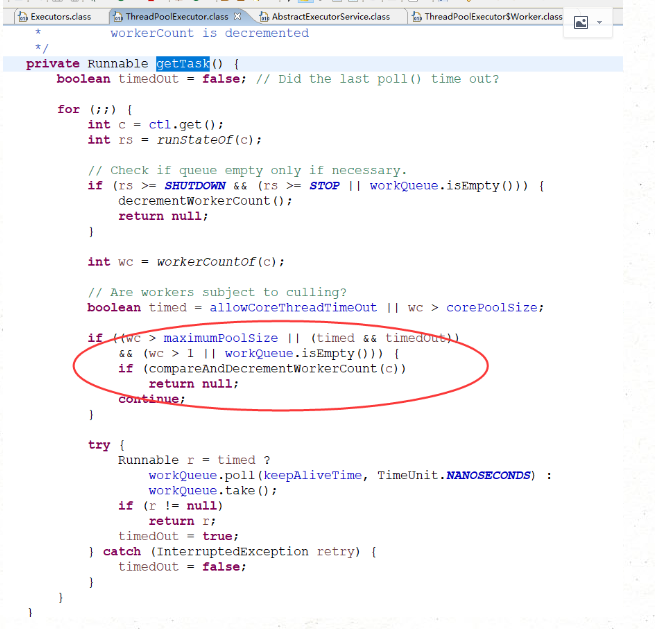
线程调用runWoker,会while循环调用getTask方法从workerQueue里读取任务,然后执行任务。只要getTask方法不返回null,此线程就不会退出。我们去看下getTask方法
如果运行线程数超过客最大的线程数,但是缓冲队列已经空了,此时递减worker的数量
如果设置允许线程超时或者线程数量超过了核心线程数,并且线程在规定的时间内都没有poll到任务队列为空,则递减worker数量
正文到此结束
- 本文标签: https 安全 多线程 参数 ask queue 分布式 synchronized update ip cat 管理 value core 监听器 id 静态方法 java 进程 IDE 实例 src 线程池 IO 字节码 UTC rmi SVN 线程 redis Select ThreadPoolExecutor autocommit executor JVM CST mysql mina 数据库 数据 CTO 同步 ACE cache 索引 tag db Ipo UI 时间 锁 生命 Service 分布式锁 并发 tab tar sql 代码 volatile 删除 处理器 一致性 缓存 源码 zookeeper 内存模型 并发编程 http Atom 模型 拒绝策略 协议
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

