基于 Apollo 的配置中心 Matrix 2.0 实践总结
作者 | 夏梓耀

杏仁后端工程师,励志成为计算机艺术家
配置中心
首先简单介绍一下什么是配置中心,我们为什么需要它,为什么要花力气去完善它。
微服务化的挑战
传统单体应用( monolithic apps )因种种潜在缺陷,如:随着规模的扩大,部署效率逐渐降低,团队协作效率差,系统可靠性变差,维护困难,新功能上线周期长等,迫切需要一种新的架构去解决这些问题,而微服务( microservices )架构正是当下一种正确的解法。
不过,解决一个问题的同时,往往会诞生出很多新的问题,故:微服务化的过程中伴随着很多的挑战,其中一个挑战就是有关服务(应用)配置的。
当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须更着迁移(分割),这样配置就分散了,不仅如此,分散中还包含着冗余,冗余分两方面:服务与服务之间(如:有 A,B,C 三个服务调用 D 服务,那么 D 服务的地址会被复制三份,因为 A,B,C 三个服务是 share nothing 的),同服务实例之间(如:A服务的所有实例都是一样的配置,且它们在物理上很有可能是分散的,即:不在一台机器上)。
在单体应用时期,我们管理配置只需要考虑环境(develop,test,staging,producting...)这一个维度,那么现在就多了服务(应用)这个维度。
再明确一下上面说的问题:配置文件分散且冗余,映射到配置管理上就是:分散意味着需要一个个处理,冗余意味着重复操作。
为了解决这个问题,配置必须集中管理(逻辑上分散,物理上集中),而实现这个功能的系统组件(或基础设置)就是配置中心。
配置中心核心需求
既然集中管理,那么就是要将应用的配置作为一个单独的服务抽离出来了(配置不再和应用一起进代码仓库),同理也需要解决新的问题,比如:版本管理(为了支持回滚),权限管理,灰度发布等
以上讨论的还都停留在静态配置的层面上,而应用除了静态的配置(如:数据库配置,一些云服务的参数配置,服务启动后一般不会变动),还会有一些动态的配置(如:灰度开关,一些常量参数:超时时间,限流阈值等),还有理论上:
在一个大型的分布式系统中,你没有办法把整个分布式系统停下来,去做一个软件的、硬件的或者系统的升级
业务需求的一些天然动态行为(如:一些运营活动,会动态调整一些参数),加之理论上必须要支持这个特性,所以,配置中心服务还得支持动态特性,即:配置热更新。
简单总结一下,在传统巨型单体应用纷纷转向细粒度微服务架构的历史进程中,服务配置中心是微服务化不可缺少的一个系统组件,其解决的就是:分布式系统的动态配置问题。
那么我们是怎么解决的呢?那就是 Matrix 1.0 的故事了。
Matrix 1.x
Matrix 是我们自研的服务配置中心,它完成了第一步,即:配置集中管理,所有应用的配置文件都交给 Matrix 管理,拥有环境隔离,版本控制,权限管理等功能。
配置文件是在 CI 构建阶段静态注入的,不同环境注入相应的配置文件,对不同的 build 工具(如:maven,sbt)都实现了配置注入的插件,来从 Matrix 上拉取配置文件
那么为什么还要进行 Matrix 2.0 的工作呢?Matrix1.x 有什么缺陷吗?
在服务(应用)数不多的情况下,Matrix1.x 是完全够用的,但是随着业务规模的发展,问题会渐渐暴露出来。
配置冗余
Matrix 并没有解决配置冗余的问题,我们需要类似模版的东西,将冗余部分抽取成一份并共享,降低配置维护成本。
打包耦合
其次,CI 打包与配置注入耦合,意味着打包与环境耦合,一个环境对应一个包(镜像),这其实违背了容器的"一份镜像到处运行"的理念,即:镜像与环境无关,应用需要什么环境的配置,在启动阶段确定(注入)就可以了。
不支持动态更新
最后是没有配置动态(热)更新能力,前面已说过这个也是必须要支持的;只有我们的基础设施是完美的,其之上的业务才能是完美的。
所有问题,在服务规模小(管理/运维复杂度低)时,都不是问题。
随着业务复杂度的不断提高,和微服务架构的不断深化,现有的 Matrix 1.x 版本暴露出很多缺失的关键能力(比如权限管理,配置模板,热发布等),逐渐成为产品快速迭代的瓶颈之一,我们亟需对 Matrix 进行升级改造,打造一个更强大、更易用的微服务配置中心。
所以我们需要 Matrix 2.0。
Matrix 2.0
不过开始做之前,还是得先静下心来评估一下,是继续走自研,还是选择别人开源的进行二次开发?我做了一段时间的调研,显然继续自研的开发 cost 是巨大的,核心功能如:配置热更新,灰度发布,配置模版(去冗余)都得从零开始开发, 其次还要保证高性能,高可用等非功能性需求。
二次开发的选择其实也不多(这并不是什么坏事),参考网络上已有的对比与讨论,可得出以下结论:
| 注册中心 | 配置存储 | 时效性 | 数据模型 | 维护性 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| disconf | zookpeer | 实时推送 | 支持传统的配置文件模式,亦支持 KV 结构数据 | 提供界面操作 | 基于分布式的 Zookeeper 来实时推送稳定性、实效性、易用性上均优于其他 | 代码复杂, 2016 年 12 月之后没有更新,功能不够强大,不能完全满足我们的需求 |
| zookpeer | zookpeer | 实时推送 | 支持传统的配置文件模式,亦支持 KV 结构数 | 命令操作 | 实时推送稳定性、实效性 | 太底层,开发量大 |
| diamond | mysql | 每隔15s拉一次全量数据 | 只支持 KV 结构的数据 | 提供界面操 | 简单、可靠、易用 | 数据模型不支持文件,使用不方便 |
| Spring Cloud Config | git | 人工批量刷新 | 文件模式 | Git 操作 | 简单、可靠、易用 | 需要依赖 GIT,并且更新 GIT |
| Apollo | mysql | 实时推送 + 定时拉取 | 支持传统的配置文件模式,亦支持 KV 结构数 | 提供界面操 | 架构设计和稳定性考虑比较完善,不少大厂在用,Portal 的体验不错, 更新活跃 | 整体架构略显复杂,和我们容器环境不太一致 |
就目前看来"真正能打的"就 Apollo 了,由于自研成本较大,并且 Apollo 的代码也并不复杂(是标准的 Spring Boot 项目),其功能也基本上能覆盖我们的需求,所以我们最后选择基于 Apollo 进行二次开发。
对于不了解 Apollo 的同学,下面简单介绍一下,详情可参考官方文档
Apollo
Apollo(阿波罗)是携程框架部门研发的开源配置管理中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性。
其 Portal 界面的截图如下:
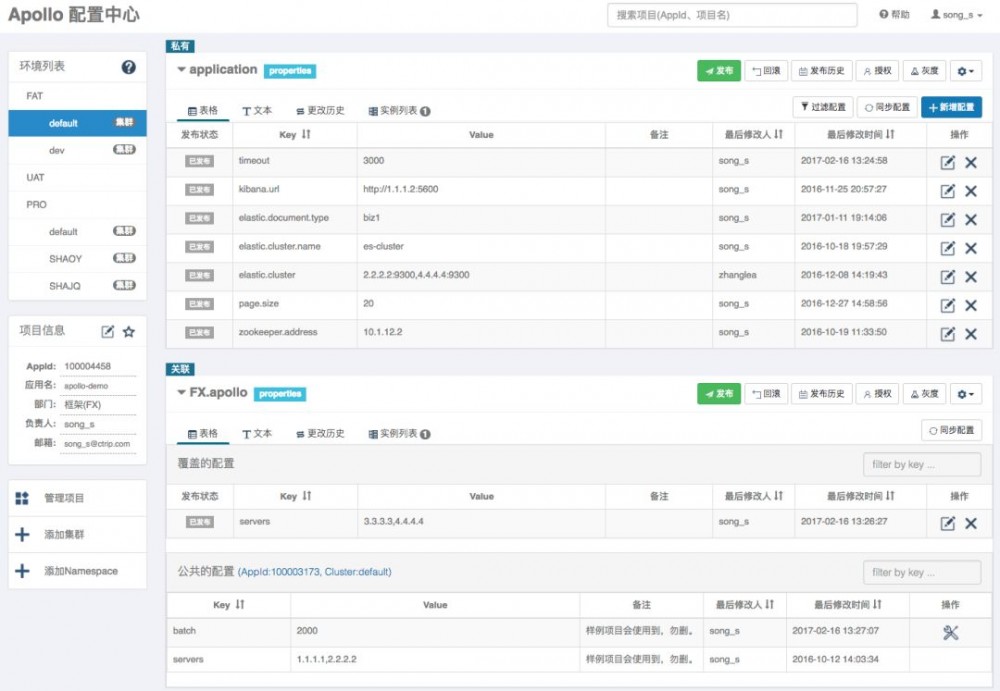
目前其最新版本(1.0.0)主要提供的功能有:
-
多环境配置管理
-
多集群配置管理
-
支持热发布
-
版本发布管理(支持配置回滚)
-
灰度发布
-
权限管理、发布审核、操作审计
-
客户端配置信息监控
可以看到 Apollo 提供了很多强大的功能,解决了 Matrix 1.0 待解决的问题;锦上添花的是其对 Spring 项目的支持非常好,这又能大大节省开发时间。
二次开发
部署模式改造
二次开发主要是做适应我们环境的定制改造,而非添加大的新功能(至少这个阶段不会),首当其冲的就是部署模式的改变,下图是 Apollo 的架构图:
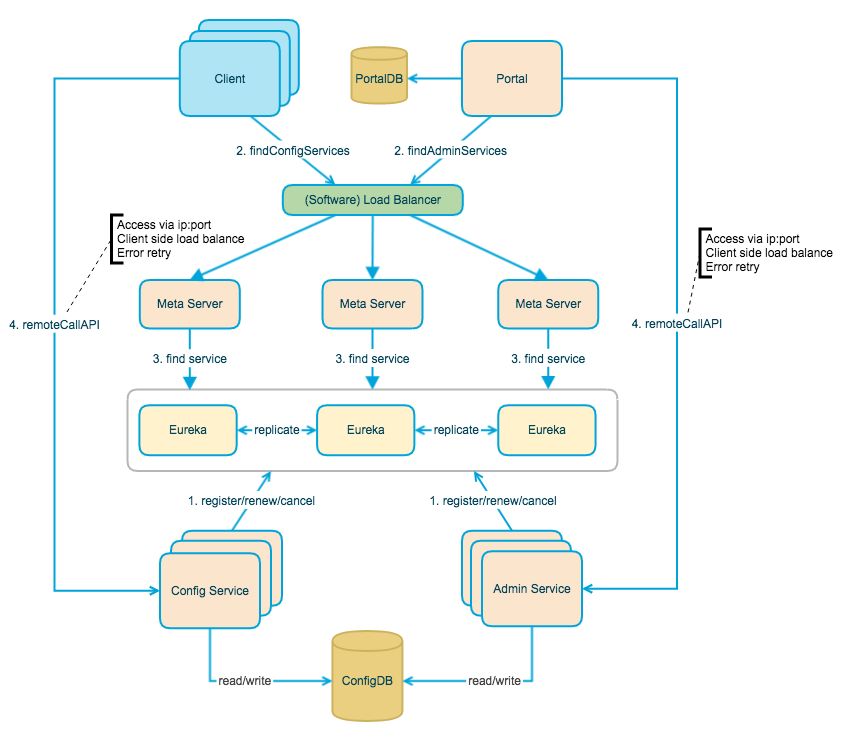
这个图是从上往下看的,第一层是 client,也就是与应用集成的 SDK,还有 Protal(包括自己的 server 和 db),它们通过一层 SLB 访问到 Meta Server,而Meta Server 是 Eureka(服务注册中心)的一层封装,用于发现 Config Service 和 Admin Service(它们启动时会向 Eureka 注册自己),也就是最后一层,这两个服务共同管理着我们的配置,配置则存储在 ConfigDB 中。
外面还有一条 Client 到 Config Service 的箭头,就是其实时推送机制的实现原理:Client 通过(HTTP)Long Polling的方式,不停的询问 Config Service,如果配置有更新(发布)则会立即返回,无更新则返回 HTTP 状态码 304。
而我们的服务都是部署在 Kubernetes 集群上的,Kubernetes 有自己的服务发现功能,包括 LB 功能,所以与 Eureka 重复了,需要将 Eureka 剥离出来,将 Meta Server 去掉,我们的部署方式如下图:
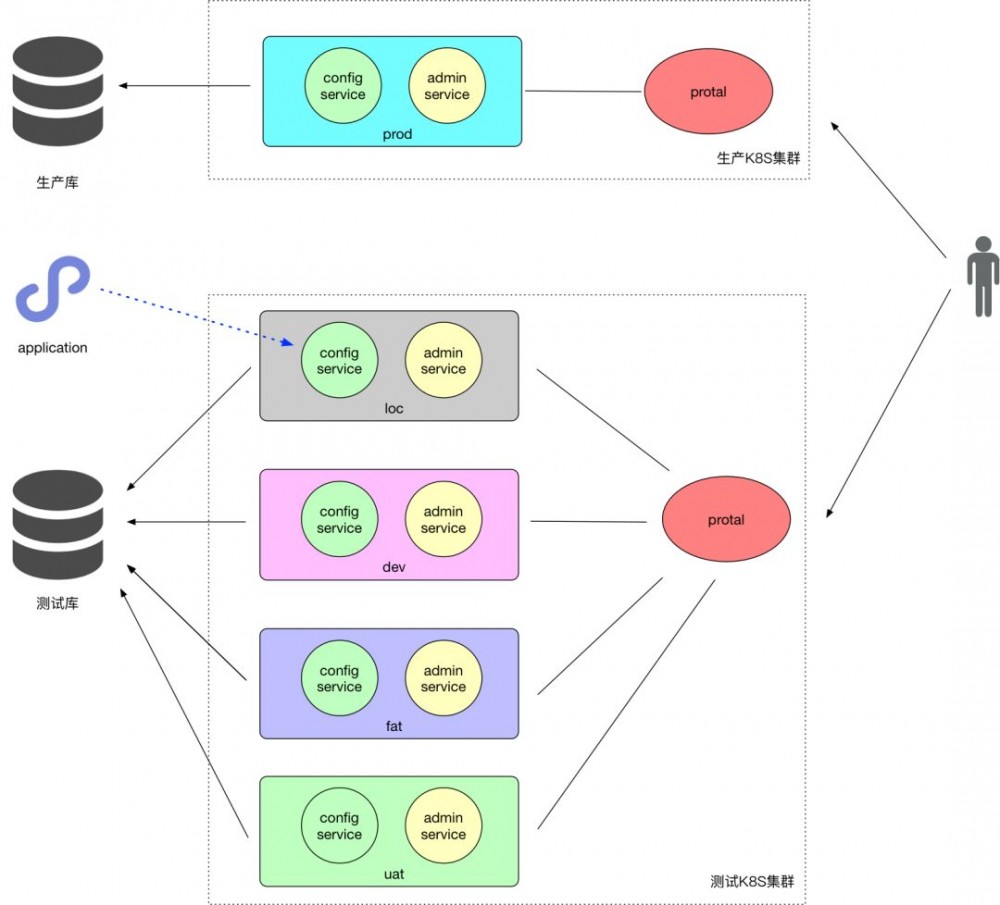
所有非生产环境对应一个 portal,每个环境独立部署 config service 和 admin service,其中生产环境在单独的 k8s 集群中(单独对生产环境做了隔离,是因为 Apollo 的权限管理还不够强大,不支持区分环境的访问权限)。
这个改造分三部分,第一部分和第二部分是分别去除 Protal 和 Client 对 Meta Server 对依赖,即:去除在 Client 和 Protal 中配置的 Meta server 地址,而是直接使用 Kubernetes 暴露的服务域名(开发和 local 环境因为需要本地访问,有公网地址)。
第三部分是去除 Config Service 上的 Eureka Server,Admin Service 上的 Eureka Client,因为 Eureka 非常成熟易用,且是个声明式(基于注解和配置)的框架,所以改动起来并不麻烦,我们只是将 Eureka 的注解去掉了而已,没有把依赖去掉(如果要去掉依赖,那么工作量会很大,因为依赖的地方多,整个 Meta Server 都是对其 Client API 的封装)。
唯一的坑就是记得在配置文件中把 spring.cloud.discovery.enabled 设置为 false,因为 Protal 对 Admin Service 的健康检查是基于spring boot actuator,而它是自动的,检测到有 Eureka 的依赖,就会启动相关健康检查的 Endpoint。
如果想做的好一点,可以做个配置开关,启动时配置是否启用 Eureka,当然这样工作量会很大,或许官方会考虑(毕竟容器编排系统是趋势,大中小厂都会用)。
本地开发
其次我们还添加了 LOC 环境(针对本地开发),UT 环境(针对单元测试),这方面 Apollo 有方便自定义环境的方法提供。不过我们并不满意官方推荐的本地开发模式,我们希望配置中心对本地开发是透明的,对于 Spring Boot 项目,原来是基于profile 覆盖的,那么现在还是 profile 覆盖的方式,这是最好的。然而 SDK 是将 Apollo 上拉取的配置覆盖在 Spring 的配置上的,即 Spring 的 profile 机制会失效,经讨论后决定在 Client 启动时:如果检测到当前是 LOC 环境,则将 Apollo 和 Spring 的配置覆盖顺序倒置。
这里简单的说一下实现原理,SDK 对 Spring 项目的集成是通过往 Environment 的 propertySourceList 中以 addFirst 的方式添加自己的配置,放在了查找链的最前面,故达到了覆盖一切的目的,而我们在检测到是 LOC 环境时以 addLast 的方式添加 Apollo 上的配置,就不会覆盖任何配置了,原来的 profile 机制依然有效。
封装SDK
还有一个坑,就是 SDK 的初始化时间问题,或者说是 Client 拉取配置的时间点问题;任何应用都有框架级别的配置,而有些配置是在一个非常早的时间点生效的,这是"应用启动时读取配置"这种方式必须考虑的问题,Spring Boot 项目的 Logging System 就是初始化早于 Apollo 的配置初始化(覆盖)的例子,也就是说:关于 log 的配置,不会生效。
我们解决的方式就是在 Apollo 配置初始化之后,重新初始化这些模块,使得 Apollo 的配置生效,这种解法的副产物是:我们使得这些模块的配置具有了动态性(我们可以安全的在运行期去重新初始化这些模块)
为此我们封装了自己的 SDK:vapollo(依赖于 apollo-client 的 SDK),提供定制功能。
配置迁移
二次开发结束后,接着面对的问题就是配置迁移问题,因为我们选择了对 Apollo 进行二次开发,而不是对 Matrix1.x 进行扩展,故:我们需要将配置迁移过去。
我们编写了详细的配置迁移操作手册(主要涵盖了操作流程和配置规范),并设定了迁移计划,之后项目的配置会慢慢全部迁移过去,为了更安全的实施这个过程,我们在实际迁移一个简单项目后,发现还可以编写工具来帮助我们,比如配置的 diff(检查是否遗漏项,不同项)。
跳出眼前,展望未来
Matrix2.0 的工作暂时告一段落,本文虽然是总结工作内容的,但是最后我希望跳出眼前的工作,看一看未来,从而了解我们现在的不足之处。
主要分两部分:Matrix2.x 和 Matrix3.0
Matrix2.x 指现阶段工作的延续,就目前来说(实际使用一段时间后),还有很多操作上的可优化点(比如:添加更多的默认设置,让开发人员对 Apollo 更加无感知),其次是关于配置的规范也会不断的完善(什么环境必须要有那些配置,namespace 的创建和关联),甚至会有完善的配置发布流程,有了规范,就会有 review,config review(就像代码 review 那样)
世界是变化的,现阶段的工作只是符合了我们现在的环境,之后会怎样?我们的微服务架构还在发展,我们还没上 service mesh,如今基础设置都在不断的下沉,我们的配置中心需要怎样?我想也是一样的,对开发来说:我们对配置的存在会越来越无感知,我不关心这个配置项是哪来的,不关心当前是何种部署环境,不关心配置项是变化还是不变的,我只关心用到它的业务是怎样的;另一方面对配置的管理和维护也应该越来越智能,越来越自动。希望 Matrix3.0 能实现这些目标。
参考资料
-
微服务架构为什么需要配置中心?
-
阿里巴巴微服务与配置中心技术实践之道
-
Apollo配置中心Wiki
-
Apollo Client Spring项目集成原理
-
Apollo源码解析
全文完
以下文章您可能也会感兴趣:
-
浅析 InnoDB 存储引擎的工作流程
-
使用 RabbitMQ 实现 RPC
-
原来你是这样的 Stream —— 浅析 Java Stream 实现原理
-
分布式锁实践之一:基于 Redis 的实现
-
数据介绍一个 MySQL 自动化运维利器 - Inception
-
OpenResty 不完全指南
-
如何进行系统分析与设计
-
ConcurrentHashMap 的 size 方法原理分析
-
从 ThreadLocal 的实现看散列算法
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 rd-hr@xingren.com 。

杏仁技术站
长按左侧二维码关注我们,这里有一群热血青年期待着与您相会。
正文到此结束
- 本文标签: zookeeper API 解析 参数 client 招聘 id 分布式锁 服务注册 tag 测试 https 安全 管理 Kubernetes REST build 文章 希望 工程师 注册中心 stream 定制 git 阿里巴巴 redis App Eureka Uber 数据模型 MQ 模型 配置中心 微服务 java 集群 数据 智能 软件 OpenResty ACE IO 分布式系统 Spring Cloud Config 限流 spring maven 产品 UI 域名 插件 开源 http Service rabbitmq Spring cloud 单元测试 云 自动化 进程 配置 时间 二维码 总结 运营 Property 高可用 架构设计 存储引擎 mysql db 数据库 map 需求 list 锁 DDL 操作手册 分布式 原理分析 ConcurrentHashMap tab 励志 sql 代码 实例 开发 src Logging Spring Boot 灰度发布 HashMap 源码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

