【备战春招/秋招系列】美团Java面经总结进阶篇 (附详解答案)

-
- 1.1 介绍一下消息队列MQ的应用场景/使用消息队列的好处
- ①.通过异步处理提高系统性能
- 1.2 那么使用消息队列会带来什么问题?考虑过这个问题吗?
- 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
- 1.4 关于消息队列其他一些常见的问题展望
- 1.1 介绍一下消息队列MQ的应用场景/使用消息队列的好处
- 二 谈谈 InnoDB 和 MyIsam 两者的区别
- 三 聊聊 Java 中的集合吧!
- 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
- 3.2 HashMap的底层实现
- 3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解
- 3.4 红黑树这么优秀,为何不直接使用红黑树得了?
- 3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别
该文已加入开源文档:JavaGuide(一份涵盖大部分Java程序员所需要掌握的核心知识)。地址: github.com/Snailclimb/… .
系列文章:
- 【备战春招/秋招系列1】程序员的简历就该这样写
- 【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?
- 【备战春招/秋招系列3】Java程序员必备书单
- 【备战春招/秋招系列4】美团面经总结基础篇 (附详解答案)
这是我总结的美团面经的进阶篇,后面还有终结篇哦!下面只是我从很多份美团面经中总结的在美团面试中一些常见的问题。不同于个人面经,这份面经具有普适性。每次面试必备的自我介绍、项目介绍这些东西,大家可以自己私下好好思考。我在前面的文章中也提到了应该怎么做自我介绍与项目介绍,详情可以查看这篇文章: 【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试? 。
有人私信我让我对美团面试难度做一个评级,我觉得如果有10级的话,美团面试的难度大概在6级左右吧!部分情况可能因人而异了。
消息队列/消息中间件应该是Java程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花2个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java工程师面试突击第1季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
一 消息队列MQ的套路
面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列MQ的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
1.1 介绍一下消息队列MQ的应用场景/使用消息队列的好处
《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
①.通过异步处理提高系统性能
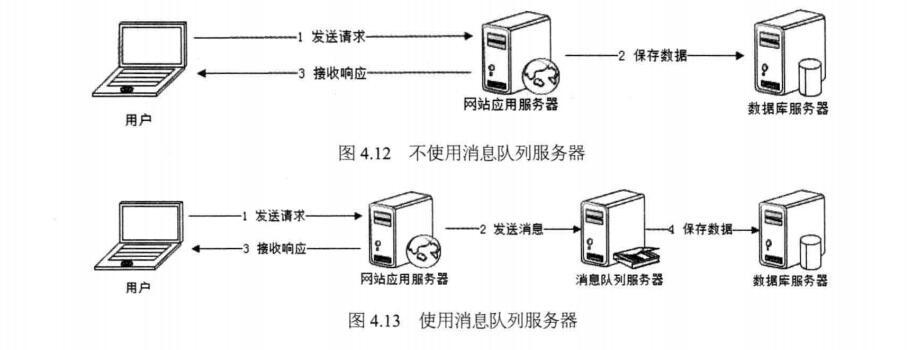
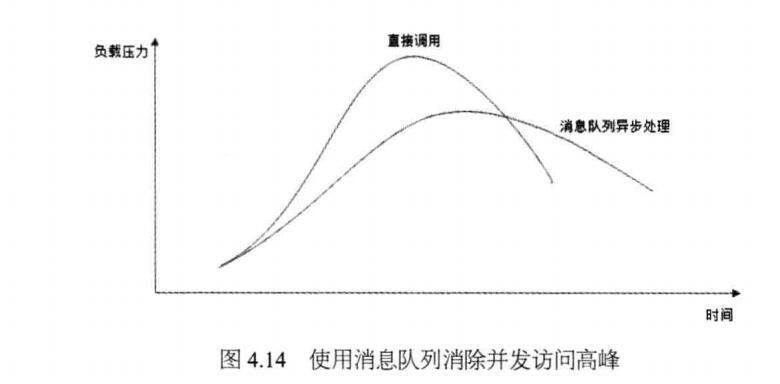
通过以上分析我们可以得出 消息队列具有很好的削峰作用的功能 ——即 通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
②.降低系统耦合性
我们知道模块分布式部署以后聚合方式通常有两种:1. 分布式消息队列 和2. 分布式服务 。
先来简单说一下分布式服务:
目前使用比较多的用来构建 SOA(Service Oriented Architecture面向服务体系结构) 的 分布式服务框架 是阿里巴巴开源的 Dubbo .如果想深入了解Dubbo的可以看我写的关于Dubbo的这一篇文章: 《高性能优秀的服务框架-dubbo介绍》 : juejin.im/post/5acade…
再来谈我们的分布式消息队列:
我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
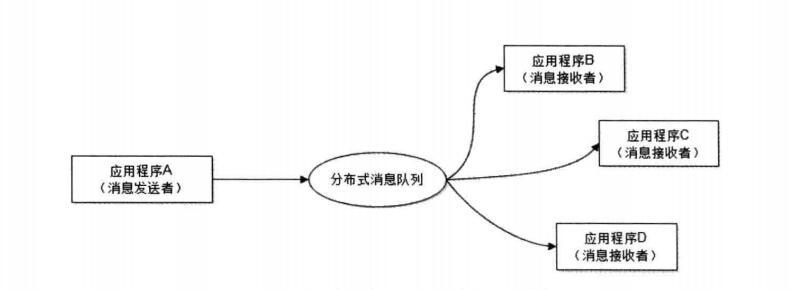
我们最常见的 事件驱动架构 类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
。
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
备注:不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的, 比如在我们的ActiveMQ消息队列中还有点对点工作模式 ,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
1.2 那么使用消息队列会带来什么问题?考虑过这个问题吗?
- **系统可用性降低:**系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
- 系统复杂性提高: 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java工程师面试突击第1季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafaka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ | 10万级别,这是kafka最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | ||
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,消息可以做到0丢失 | |
| 时效性 | ms级 | 微秒级,这是rabbitmq的一大特点,延迟是最低的 | ms级 | 延迟在ms级以内 |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ 5.x维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang语言开发,性能极其好,延时很低;吞吐量到万级,MQ功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用rabbitmq也比较多一些但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景。而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的 | kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量。而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java工程师面试突击第1季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java面试通关手册”后台回复关键字“1”即可!
1.4 关于消息队列其他一些常见的问题展望
- 引入消息队列之后如何保证高可用性
- 如何保证消息不被重复消费呢?
- 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
- 我该怎么保证从消息队列里拿到的数据按顺序执行?
- 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
- 如果让你来开发一个消息队列中间件,你会怎么设计架构?
二 谈谈 InnoDB 和 MyIsam 两者的区别
2.1 两者的对比
-
count运算上的区别:因为MyISAM缓存有表meta-data(行数等),因此在做COUNT(*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于InnoDB来说,则没有这种缓存。
-
是否支持事务和崩溃后的安全恢复:MyISAM 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3) 是否支持外键: MyISAM不支持,而InnoDB支持。
2.2 关于两者的总结
MyISAM更适合读密集的表,而InnoDB更适合写密集的的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。
一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB是不错的选择。如果你的数据量很大(MyISAM支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM是最好的选择。
三 聊聊 Java 中的集合吧!
3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
- 1. 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 2. 底层数据结构: Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
- 3. 插入和删除是否受元素位置的影响: ① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行
add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。 - 4. 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于
get(int index)方法)。 - 5. 内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
补充内容:RandomAccess接口
public interface RandomAccess {
}
复制代码
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
复制代码
ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
下面再总结一下 list 的遍历方式选择:
- 实现了RadmoAcces接口的list,优先选择普通for循环 ,其次foreach,
- 未实现RadmoAcces接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
Java 中的集合这类问题几乎是面试必问的,问到这类问题的时候,HashMap 又是几乎必问的问题,所以大家一定要引起重视!
3.2 HashMap的底层实现
####① JDK1.8之前
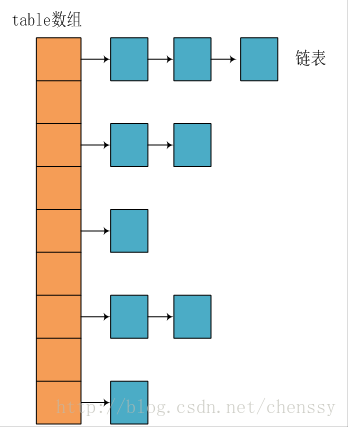
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列 。 HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
复制代码
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
###② JDK1.8之后
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
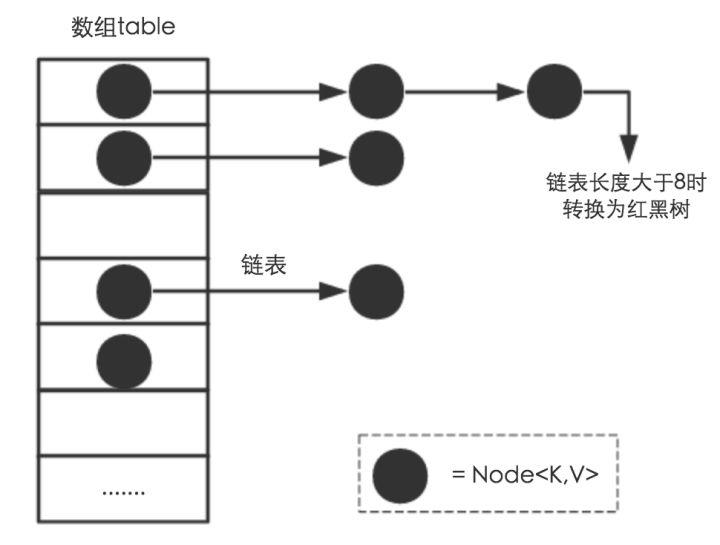
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
问完 HashMap 的底层原理之后,面试官可能就会紧接着问你 HashMap 底层数据结构相关的问题!
3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解
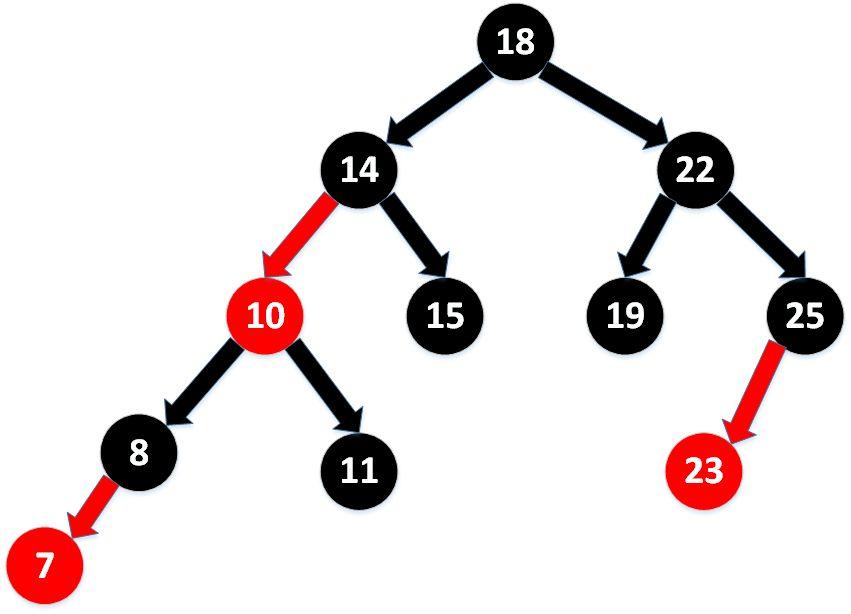
红黑树特点:
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
红黑树的应用:
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
为什么要用红黑树
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
3.4 红黑树这么优秀,为何不直接使用红黑树得了?
说一下自己对于这个问题的看法:我们知道红黑树属于(自)平衡二叉树,但是为了保持“平衡”是需要付出代价的,红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,这费事啊。你说说我们引入红黑树就是为了查找数据快,如果链表长度很短的话,根本不需要引入红黑树的,你引入之后还要付出代价维持它的平衡。但是链表过长就不一样了。至于为什么选 8 这个值呢?通过概率统计所得,这个值是综合查询成本和新增元素成本得出的最好的一个值。
3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别
HashMap 和 Hashtable 的区别
- 线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过
synchronized修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!); - 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的
tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。 - 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashSet 和 HashMap 区别
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)

你若盛开,清风自来。 欢迎关注我的微信公众号:“Java面试通关手册”,一个有温度的微信公众号。公众号后台回复关键字“1”,可以免费获取一份我精心准备的小礼物哦!

正文到此结束
- 本文标签: 服务器 阿里巴巴 大数据 空间 消息队列 锁 统计 JMS MQ bug 存储引擎 https 集群 NSA 火车票 实例 开发 src 微信公众号 主从架构 一致性 synchronized java git 网站 IDE 时间 DOM 参数 同步 免费 Collection rabbitmq ArrayList ip 互联网 数据 代码 遍历 美团 dubbo 文章 IO 高可用 LinkedList db 压力 UI 电子商务 程序员 list 开源 Architect constant 高并发 ConcurrentHashMap HashSet tab 进程 配置 GitHub App value 百度 ACE Service RocketMQ HashTable 并发 源码 线程 map SOA CTO key 总结 删除 Action 分布式 HashMap 缓存 定制 数据库 安全 管理 CEO Collections final http ActiveMQ id 工程师
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

