高并发编程:HashMap 深入解析
底层实现原理
在JDK1.8以前版本中,HashMap的实现是数组+链表,它的缺点是即使哈希函数选择的再好,也很难达到元素百分百均匀分布,而且当HashMap中有大量元素都存到同一个桶中时,这个桶会有一个很长的链表,此时遍历的时间复杂度就是O(n),当然这是最糟糕的情况。
在JDK1.8及以后的版本中引入了红黑树结构,HashMap的实现就变成了数组+链表或数组+红黑树。添加元素时,若桶中链表个数超过8,链表会转换成红黑树;删除元素、扩容时,若桶中结构为红黑树并且树中元素个数较少时会进行修剪或直接还原成链表结构,以提高后续操作性能;遍历、查找时,由于使用红黑树结构,红黑树遍历的时间复杂度为 O(logn),所以性能得到提升。
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
死循环分析
在JDK1.8之前的版本中,HashMap的底层实现是数组+链表。当调用HashMap的put方法添加元素时,如果新元素的hash值或key在原Map中不存在,会检查容量size有没有超过设定的threshold,如果超过则需要进行扩容,扩容的容量是原数组的两倍,具体代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
//检查容量是否超过threshold
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
扩容就是新建Entry数组,并将原Map中元素重新计算hash值,然后存到新数组中,具体代码如下:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//新数组
Entry[] newTable = new Entry[newCapacity];
//原数组元素转存到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//指向新数组
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
假设一个HashMap的初始容量是4,使用默认负载因子0.75,有三个元素通过Hash算法计算出的数组下标都是2,但是key值都不同,分别是a1、a2、a3,HashMap内部存储如下图:
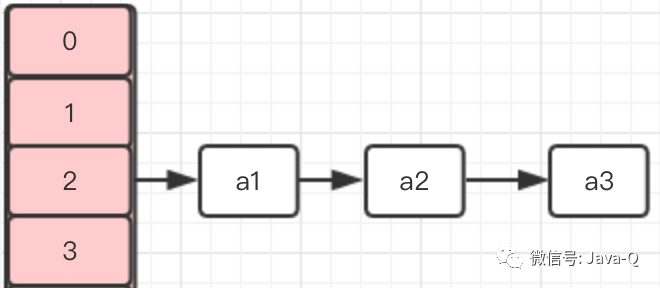
假设插入的第四个元素a4,通过Hash算法计算出的数组下标也是2,当插入时则需要扩容,此时有两个线程T1、T2同时插入a4,则T1、T2同时进行扩容操作,它们各自新建了一个Entry数组newTable。
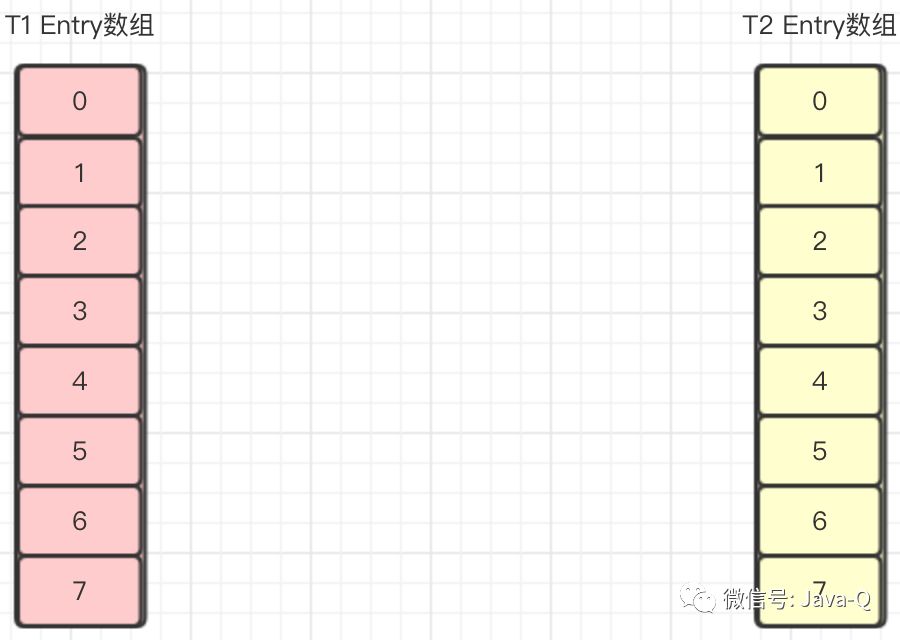
T2线程执行到transfer方法的Entry<K,V> next = e.next;时被挂起,T1线程执行transfer方法后Entry数组如下图:
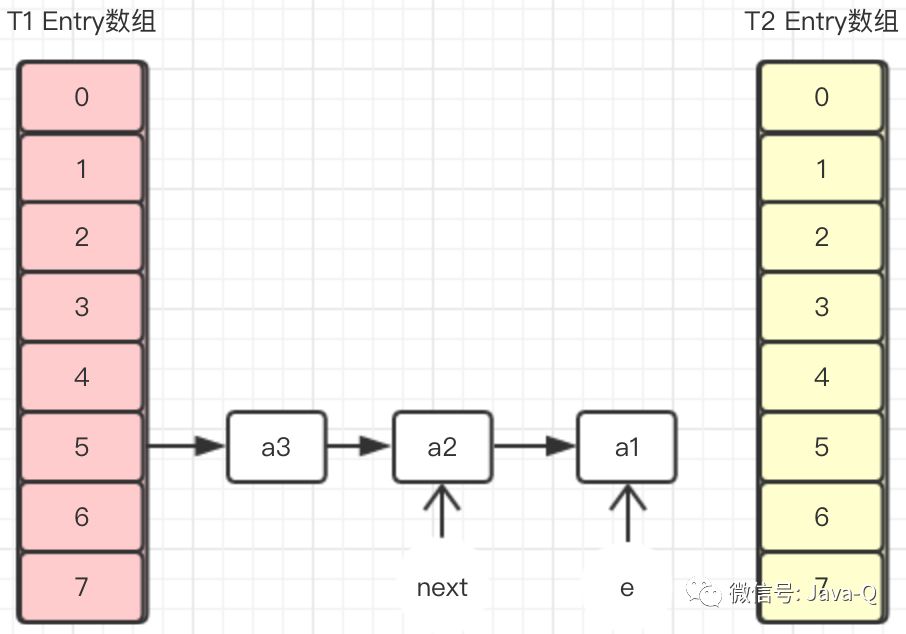
在T1线程没返回新建Entry数组之前,T2线程恢复,因为在T2挂起时,变量e指向的是a1,变量next指向的是a2,所以在T2恢复执行完transfer之后,Entry数组如下图:
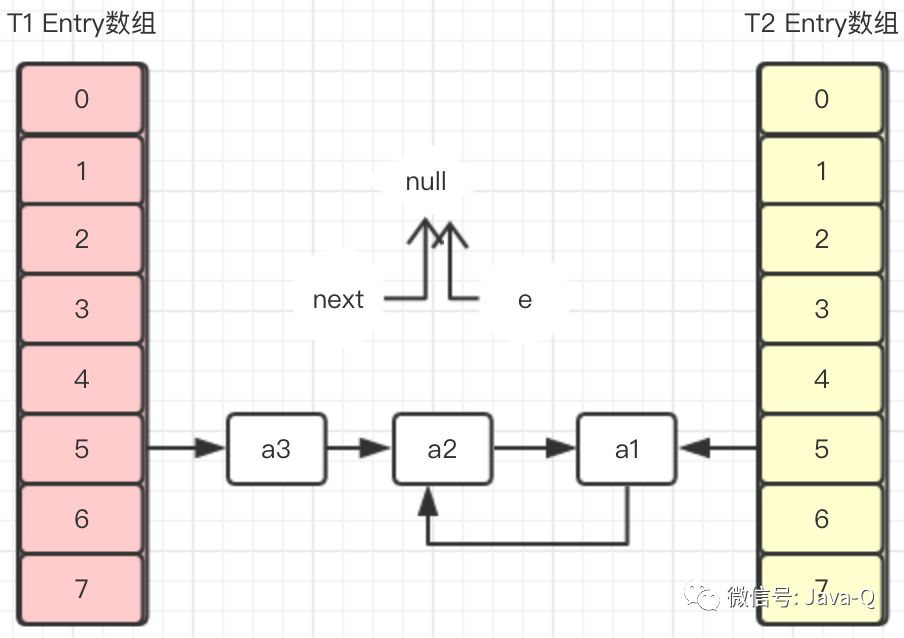
可以看到在T2执行完transfer方法后,a1元素和a2元素形成了循环引用,此时无论将T1的Entry数组还是T2的Entry数组返回作为扩容后的新数组,都会存在这个环形链表,当调用get方法获取该位置的元素时就会发生死循环,更严重会导致CPU占用100%故障。
扩容解说
JDK8中HashMap扩容涉及到的加载因子和链表转红黑树的知识点经常被作为面试问答题,下面对这两个知识点进行小结。
链表转红黑树为什么选择数字8
在JDK8及以后的版本中,HashMap引入了红黑树结构,其底层的数据结构变成了数组+链表或数组+红黑树。添加元素时,若桶中链表个数超过8,链表会转换成红黑树。之前有写过篇幅分析选择数字8的原因,内容不够严谨。最近重新翻了一下HashMap的源码,发现其源码中有这样一段注释:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFYTHRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poissondistribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-pow(0.5, k) / factorial(k)). The first values are: 0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
翻译过来大概的意思是:理想情况下使用随机的哈希码,容器中节点分布在hash桶中的频率遵循泊松分布,具体可以查看泊松分布,按照泊松分布的计算公式计算出了桶中元素个数和概率的对照表,可以看到链表中元素个数为8时的概率已经非常小,再多的就更少了,所以原作者在选择链表元素个数时选择了8,是根据概率统计而选择的。
默认加载因子为什么选择0.75
HashMap有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行扩容、rehash操作(即重建内部数据结构),扩容后的哈希表将具有两倍的原容量。
通常,加载因子需要在时间和空间成本上寻求一种折衷。加载因子过高,例如为1,虽然减少了空间开销,提高了空间利用率,但同时也增加了查询时间成本;加载因子过低,例如0.5,虽然可以减少查询时间成本,但是空间利用率很低,同时提高了rehash操作的次数。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,减少扩容操作。
选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择,至于为什么不选择0.5或0.8,笔者没有找到官方的直接说明,在HashMap的源码注释中也只是说是一种折中的选择。
往期精彩内容
-
高并发编程-AQS深入解析
-
高并发编程-CountDownLatch深入解析
-
高并发编程-CAS深入解析
-
高并发编程-CyclicBarrier深入解析
-
高并发编程-Semaphore深入解析
-
高并发编程-ReentrantLock公平锁深入解析
-
高并发编程-ReentrantLock非公平锁深入解析
-
高并发编程-ReentrantReadWriteLock深入解析
-
高并发编程-Condition深入解析
-
高并发编程-synchronized深入解析
-
高并发编程-synchronized深入解析深挖
-
高并发编程-锁优化详解
-
高并发编程-volatile详解
-
高并发编程-happens-before
觉得有收获,诚邀 关注、点赞、转发 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

