工作中的坑——dom4j解析含有命名空间的XML的坑
虽然网上有很多类似的文章,可都描述的不是特别清楚且都是很老的文章了,让人走很多弯路,这里完整记录下。
说在前面
网上大多数分析的帖子都说dom4j解析xml性能最好,所以在碰到实际业务场景中就着手使用dom4j来解析xml了。
在业务场景中解析xml基本上两种,一种是配置,另一种是调用外部项目接口反馈的xml。前者这里不多说,自己的配置随心所欲,通常xml的结构也相对比较简单。而后者就比较糟心了,比如我遇到的,一边接对应的接口一边不停的吐槽,泪崩中啊。
至于dom4j如何使用和一些基本概念,这里就不过多描述,网上随便一搜就是一大堆。
这里主要说下解析含有命名空间的XML。
具体实现
先看要我要解析的XML格式,如下截图,其实也不是很复杂:
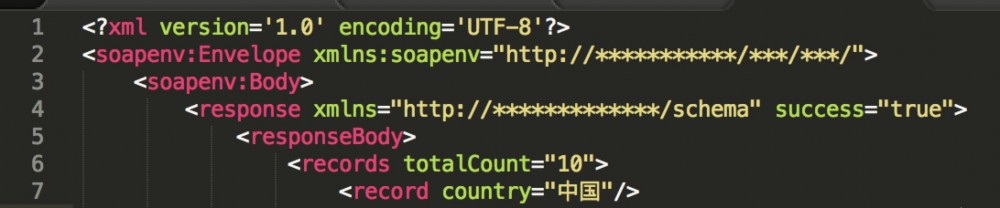
在了解完dom4j基本概念之后,我就开始着手开发了,发现在获取完根节点之后,我需要递归几次才能获取我需要的 record 这个节点,显然比较麻烦。
于是继续google发现可以使用 selectNode(xpath) 的方式来直接获取,这个才是我想要的。
原以为几行代码轻松搞定,可最后发现 selectNode 始终获取不到对应的节点,起初还以为是我的路径有问题,后来才知道dom4j不能识别带命名空间的节点,所以在读取带命名空间的XML时,要在每个节点前加上命名空间。
好吧,我只想安安静静地解析个XML,居然这么绕,顿时心里又在吐槽这个接口本身了,非要用什么webservice返回个xml,http+json多好呀。
吐槽归吐槽,接还是得接啊,网上找些资料之后也大致明白,只要在节点前加上命名空间即可。
可好事多磨啊,我接的那个接口居然有两个命名空间, soapenv 和 response 两个节点上都有,好吧,我忍。
大体思路就是,先获取根节点,取到对应的命名空间,然后selectSingleNode到 response 这个节点取第二个命名空间,最后再组装xpath取到自己想要的节点。核心代码如下:
Document doc = XmlUtil.strToDocument(responseStr);
Map map = new HashMap();
// 获得命名空间
String firstUrl = doc.getRootElement().getNamespaceURI();
map.put("firstUrl", firstUrl);
XPath x = doc.createXPath("//firstUrl:Body");
x.setNamespaceURIs(map);
//获取第二层xml的命名空间
String secendUrl = ((Element) x.selectSingleNode(doc)).element("response").getNamespaceURI();
map.put("secendUrl", secendUrl);
x = doc.createXPath("//firstUrl:Body/secendUrl:response/"
+ "secendUrl:responseBody/secendUrl:records/secendUrl:record");
x.setNamespaceURIs(map);
List<Element> nodes = x.selectNodes(doc);
说在后面
在开发一段时间的java之后,突然开始怀念起 .net了,尤其在处理一些细节方面的时候,总感觉java有点啰嗦,明明可以一行代码搞定的事情,需要写个三四行。
java10终于支持var关键字了,java11要开始收费了,不懂是福还是祸啊~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

