要玩转这个星际争霸II开源AI,你只需要i5+GTX1050
DeepMind、OpenAI 和暴雪对于星际争霸 2 人工智能的研究仍在进行中,面对复杂的即时战略游戏,人们目前还鲜有进展。尽管近期 腾讯 、南大、 伯克利 等均在星际 II 上攻克了全场游戏,但其训练规模并不是个体研究者所能 handle 的。最近,来自 University of Tartu 的 Roman Ring 开源了首个星际争霸 2 的智能体项目,我们也可以在这个前沿领域里展开自己的研究了。

Reaver 是一个模块化的深度强化学习框架,可提供比大多数开源解决方案更快的单机并行化能力,支持星际争霸 2、OpenAI Gym、Atari、MuJoCo 等常见环境,其网络被定义为简单的 Keras 模型,易于配置和共享设置。在示例中,Reaver 在不到 10 秒钟内通过了 CartPole-v0 游戏,在 4 核 CPU 笔记本上每秒采样率为 5000 左右。
Reaver 可以在 30 分钟内攻克星际争霸 2 的 MoveToBeacon 小游戏,和 DeepMind 得到的结果相当,仅使用了配置 Intel i5-7300HQ CPU (4 核) 和 GTX 1050 GPU 的笔记本,你也可以在 Google Colab 上在线跑跑对比一下。
-
项目链接: https://github.com/inoryy/reaver-pysc2
-
Reaver 的 Google Colab 地址: https://colab.research.google.com/drive/1DvyCUdymqgjk85FB5DrTtAwTFbI494x7
具体来说,Reaver 具备以下特征:
性能:现有研究的多数强化学习基线通常针对进程之间基于消息的通信(如 MPI)进行调整。这对于 DeepMind、OpenAI 等拥有大规模分布式 RL 设置的公司来说是有意义的,但对于只拥有一个计算机/HPC 节点的研究人员或发烧友来说,这似乎是一个很大的瓶颈。因此,Reaver 采用了共享内存,与之前基于消息的并行化的项目相比,速度提升了 2 倍。具体来说,Reaver 通过 lock-free 的方式利用共享内存,可以专门针对这种情况优化。这种方法可以在星际争霸 II 采样率上速度提升了 2 倍(在一般情况下可以实现 100 倍的加速),其最主要的瓶颈在于 GPU 的输入/输出管道。
模块化:许多 RL 基线或多或少都是模块化的,但经常紧紧地与作者使用的模型/环境耦合。以我个人经验来看,当我只专注于星际争霸 2 游戏时,每一次实验或调试都是一个令人沮丧的长期过程。而有了 Reaver 之后,我就能够在一行代码中交换环境(即使是从 SC2 到雅达利或 CartPole)。对于模型来说也是如此——任何 Keras 模型都可以,只要它遵守基本 API 契约(inputs = agent obs, outputs = logits + value)。Reaver 的三个核心模块 envs、models、 和 agents 基本上是完全独立的。这保证了在一个模块上的功能扩展可以无缝地连接到其它模块上。
可配置性:现有的智能体通常具有几十个不同的配置参数,共享这些参数似乎让每一个参与其中的人都很头疼。我最近偶然发现了这个问题的一个有趣的解决方案——gin-config,它支持将任意 Python 可调用函数配置为类似 Python 的配置文件和命令行参数。试验后发现 gin-config 可以实现仅用一个文件共享全部训练流程环境配置。所有的配置都能轻松地以.gin 文件的形式进行分享,包括所有超参数、环境变量和模块定义。
不过时:DL 中充满变数,即使只有一年历史的代码库也会过时。我使用即将面世的 TensorFlow 2.0 API 写 Reaver(大多使用 tf.keras,避开 tf.contrib),希望 Reaver 不会遭此厄运。
Reaver 的用途并不局限于星际争霸 II 智能体的深度强化学习训练,如果有任何扩展的想法欢迎分享给我。我计划近期添加 VizDoom 环境到这个项目中去。
python -m reaver.run --env MoveToBeacon --agent a2c --envs 4 2> stderr.log
只需通过一行代码,Reaver 就可以直接配置一个训练任务,如上所示。Reaver 的奖励函数可以很快收敛到大约 25-26RMe(mean episode rewards),这和 DeepMind 在该环境(MoveToBeacon)中得到的结果相当。具体的训练时间取决于你自己的硬件。以下日志数据是通过配置了 Intel i5-7300HQ CPU (4 核) 和 GTX 1050 GPU 的笔记本训练了 30 分钟得到的。
| T 118 | Fr 51200 | Ep 212 | Up 100 | RMe 0.14 | RSd 0.49 | RMa 3.00 | RMi 0.00 | Pl 0.017 | Vl 0.008 | El 0.0225 | Gr 3.493 | Fps 433 | | T 238 | Fr 102400 | Ep 424 | Up 200 | RMe 0.92 | RSd 0.97 | RMa 4.00 | RMi 0.00 | Pl -0.196 | Vl 0.012 | El 0.0249 | Gr 1.791 | Fps 430 | | T 359 | Fr 153600 | Ep 640 | Up 300 | RMe 1.80 | RSd 1.30 | RMa 6.00 | RMi 0.00 | Pl -0.035 | Vl 0.041 | El 0.0253 | Gr 1.832 | Fps 427 | ... | T 1578 | Fr 665600 | Ep 2772 | Up 1300 | RMe 24.26 | RSd 3.19 | RMa 29.00 | RMi 0.00 | Pl 0.050 | Vl 1.242 | El 0.0174 | Gr 4.814 | Fps 421 | | T 1695 | Fr 716800 | Ep 2984 | Up 1400 | RMe 24.31 | RSd 2.55 | RMa 30.00 | RMi 16.00 | Pl 0.005 | Vl 0.202 | El 0.0178 | Gr 56.385 | Fps 422 | | T 1812 | Fr 768000 | Ep 3200 | Up 1500 | RMe 24.97 | RSd 1.89 | RMa 31.00 | RMi 21.00 | Pl -0.075 | Vl 1.385 | El 0.0176 | Gr 17.619 | Fps 423 |
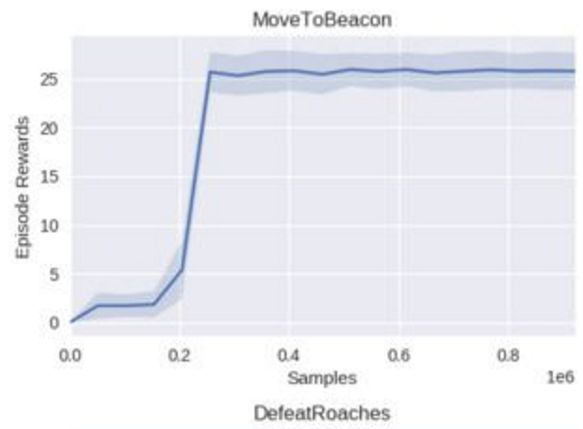
在 MoveToBeacon 环境上的 RMe 学习曲线。
基准评测分数
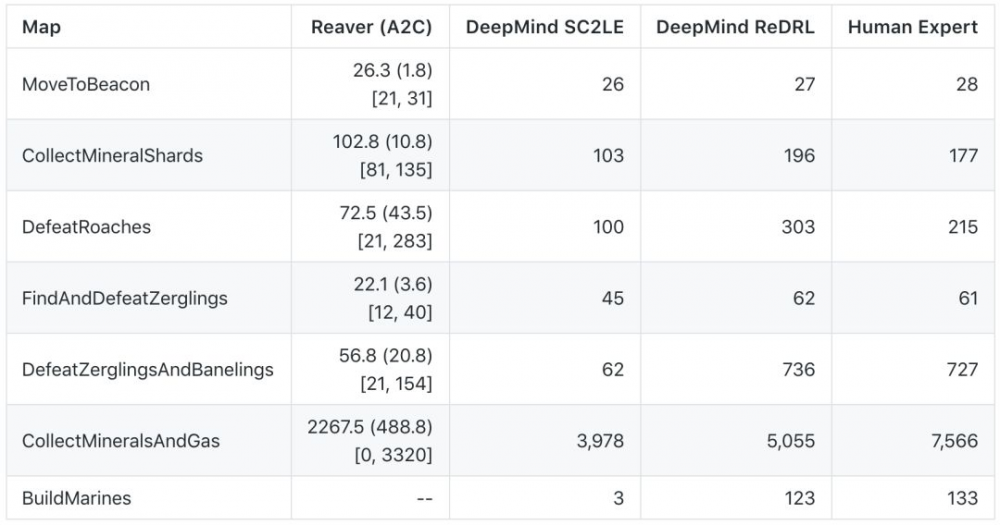
其中:
-
Human Expert 是由 DeepMind 从战网天梯的大师级玩家中收集的数据
-
DeepMind ReDRL 是当前业内最佳结果,出自 DeepMind 2018 年 6 月的论文《 Relational Deep Reinforcement Learning 》
-
DeepMind SC2LE 成绩出自 DeepMind 和暴雪 2017 年 8 月的论文《StarCraft II: A New Challenge for Reinforcement Learning》
-
Reaver(A2C)是通过训练 reaver.agents.A2C 智能体获得的结果,其在硬件上尽可能复制 SC2LE 的架构。通过训练智能体 --test 模组 100 个迭代,计算总奖励值,收集结果。表中列出的是平均值、标准差(在括号中),以及最小&最大值(在方括号中)。
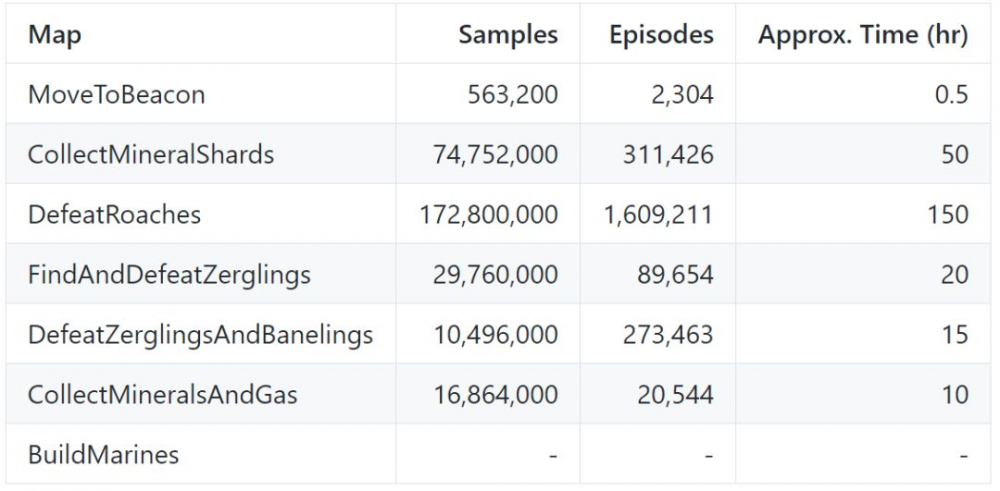
训练细节,注意这些训练时间都是在配置了 Intel i5-7300HQ CPU (4 核) 和 GTX 1050 GPU 的笔记本上得到的。我并没有花费太多时间来调超参数,而是先展示其可学习性,但至少在 MoveToBeacon 环境中,我已经显著地降低了训练样本数。
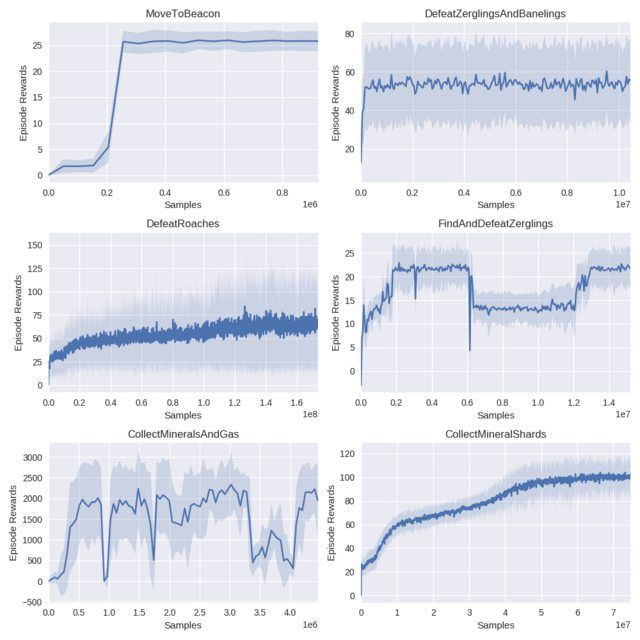
不同环境下的 RMe 学习曲线和标准差。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

