分布式系统中的缓存架构
| 编辑推荐: |
| 本文来自于51cto,本文主要介绍大型分布式系统中缓存的相关理论,常见的缓存组件以及应用场景。 |
缓存概述
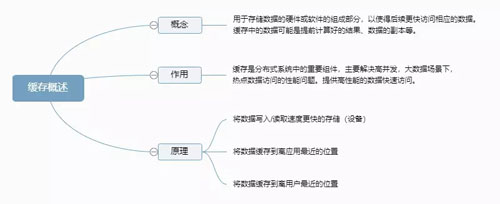
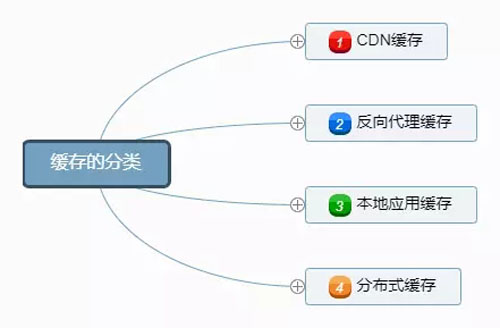
缓存的分类
缓存主要分为四类,如下图:
CDN 缓存
CDN(Content Delivery Network 内容分发网络)的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中。
在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。
应用场景:主要缓存静态资源,例如图片,视频。
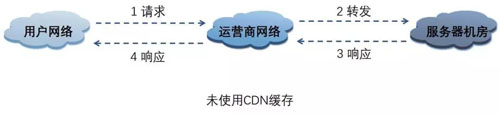
CDN 缓存应用如下图:
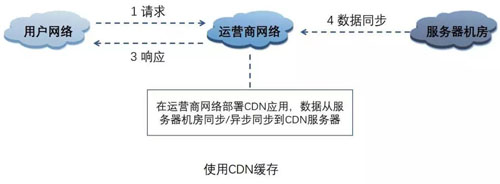
使用 CDN 缓存
CDN 缓存优点如下图:
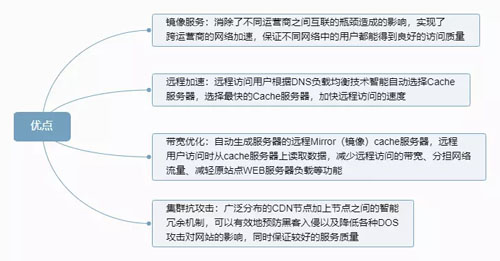
反向代理缓存
反向代理位于应用服务器机房,处理所有对 Web 服务器的请求。
如果用户请求的页面在代理服务器上有缓冲的话,代理服务器直接将缓冲内容发送给用户。
如果没有缓冲则先向 Web 服务器发出请求,取回数据,本地缓存后再发送给用户。通过降低向 Web 服务器的请求数,从而降低了 Web 服务器的负载。
应用场景:一般只缓存体积较小静态文件资源,如 css、js、图片。
反向代理缓存应用如下图:

开源实现如下图:
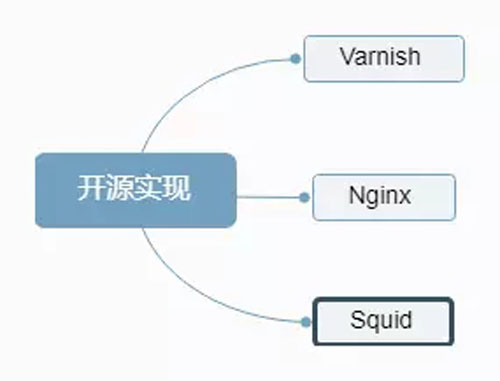
开源实现
本地应用缓存
指的是在应用中的缓存组件,其最大的优点是应用和 Cache 是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等。
在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适。
同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
应用场景:缓存字典等常用数据。
缓存介质如下图所示:
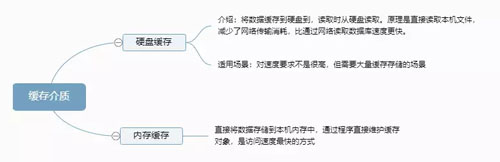
缓存介质
编程直接实现如下图:
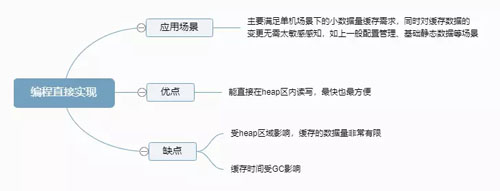
编程直接实现
Ehcache
基本介绍:Ehcache 是一种基于标准的开源缓存,可提高性能,卸载数据库并简化可伸缩性。
它是使用最广泛的基于 Java 的缓存,因为它功能强大,经过验证,功能齐全,并与其他流行的库和框架集成。
Ehcache 可以从进程内缓存扩展到使用 TB 级缓存的混合进程内/进程外部署。
Ehcache 应用场景如下图:
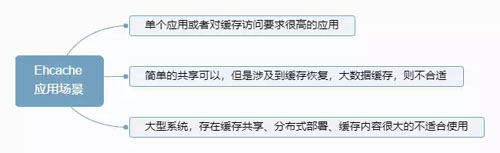
Ehcache 应用场景
Ehcache 的架构如下图:
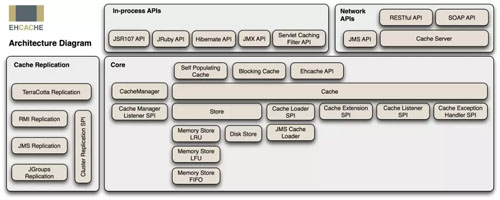
Ehcache 架构图
Ehcache 的主要特征如下图:

Ehcache 主要特征
Ehcache 缓存数据过期策略如下图:
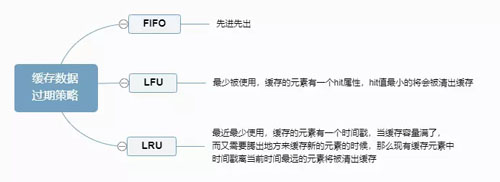
缓存数据过期策略
Ehcache 过期数据淘汰机制:即懒淘汰机制,每次往缓存放入数据的时候,都会存一个时间,在读取的时候要和设置的时间做 TTL 比较来判断是否过期。
Guava Cache
基本介绍:Guava Cache 是 Google 开源的 Java 重用工具集库 Guava 里的一款缓存工具。
Guava Cache 特点与功能如下图:
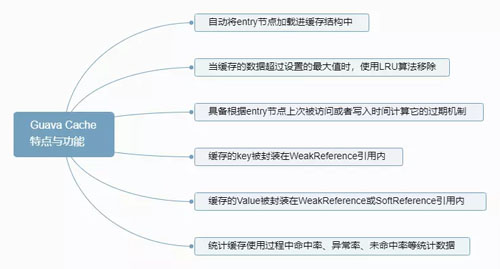
Guava Cache 特点与功能
Guava Cache 的应用场景如下图:
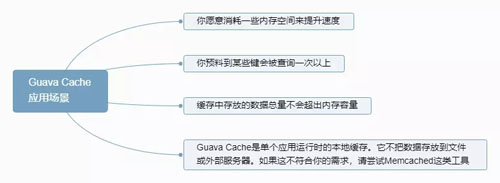
Guava Cache 应用场景
Guava Cache 的数据结构如下图:
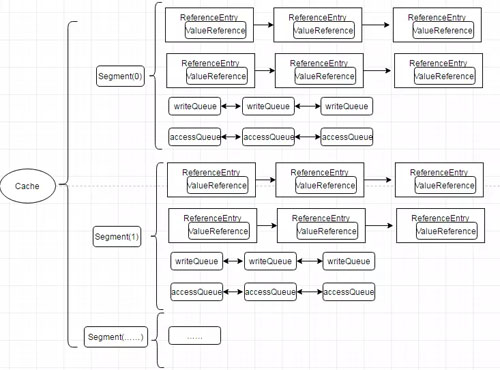
Guava Cache 数据结构图

Guava Cache 结构特点
Guava Cache 的缓存更新策略如下图:
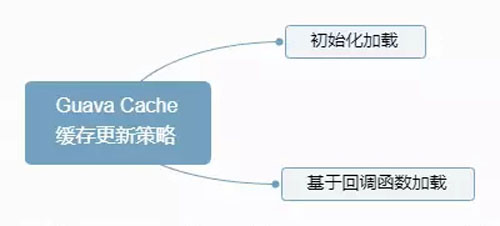
Guava Cache 缓存更新策略
Guava Cache 的缓存回收策略如下图:
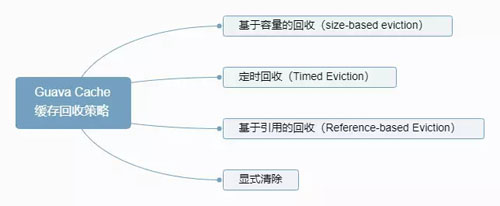
Guava Cache 缓存回收策略
分布式缓存
指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
分布式缓存的主要应用场景如下图:

分布式缓存应用场景
分布式缓存的主要接入方式如下图:
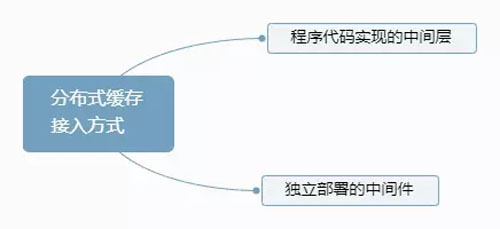
分布式缓存接入方式
下面介绍分布式缓存常见的 2 大开源实现 Memcached 和 Redis。
Memcached
Memcached 是一个高性能,分布式内存对象缓存系统,通过在内存里维护一个统一的巨大的 Hash 表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。
简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。
Memcached 的特点如下图:
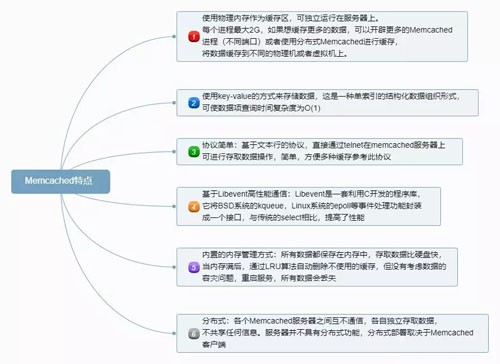
Memcached 特点
Memcached 的基本架构如下图:
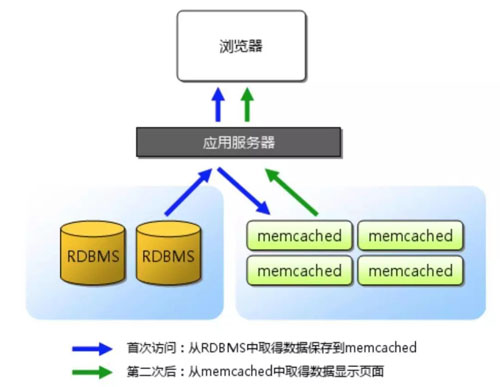
Memcached 基本架构
缓存数据过期策略:LRU(最近最少使用)到期失效策略,在 Memcached 内存储数据项时,可以指定它在缓存的失效时间,默认为永久。
当 Memcached 服务器用完分配的内存时,失效的数据被首先替换,然后是最近未使用的数据。
数据淘汰内部实现:懒淘汰机制为每次往缓存放入数据的时候,都会存一个时间,在读取的时候要和设置的时间做 TTL 比较来判断是否过期。
分布式集群实现:服务端并没有 “ 分布式 ” 功能。每个服务器都是完全独立和隔离的服务。 Memcached 的分布式,是由客户端程序实现的。
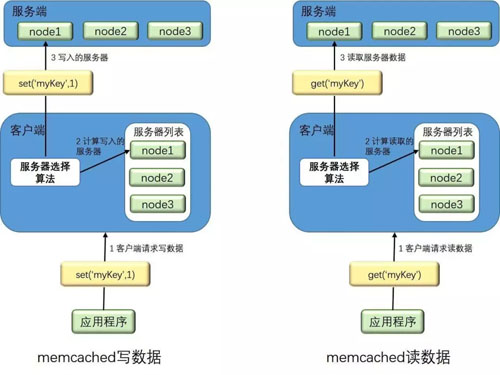
数据读写流程图
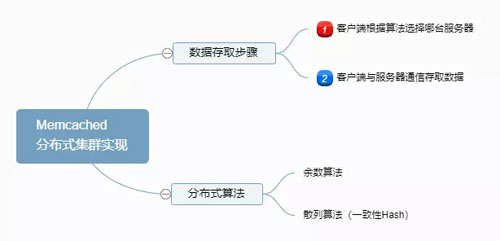
Memcached 分布式集群实现
Redis
Redis 是一个远程内存数据库(非关系型数据库),性能强劲,具有复制特性以及解决问题而生的独一无二的数据模型。
它可以存储键值对与 5 种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘,可以使用复制特性来扩展读性能。
Redis 还可以使用客户端分片来扩展写性能,内置了 复制(replication),LUA 脚本(Lua scripting),LRU 驱动事件(LRU eviction),事务(transactions) 和不同级别的磁盘持久化(persistence)。
并通过 Redis 哨兵(Sentinel)和自动分区(Cluster)提供高可用性(High Availability)。
Redis 的数据模型如下图:

Redis 数据模型
Redis 的数据淘汰策略如下图:
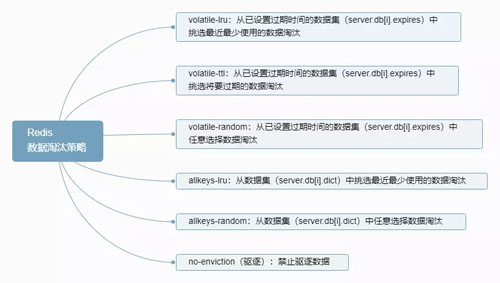
Redis 数据淘汰策略
Redis 的数据淘汰内部实现如下图:
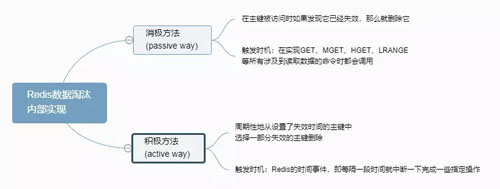
Redis 数据淘汰内部实现
Redis 的持久化方式如下图:
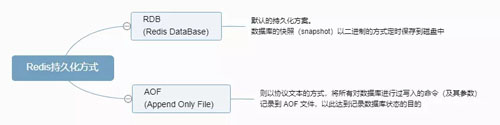
Redis 持久化方式
Redis 底层实现部分解析如下图:
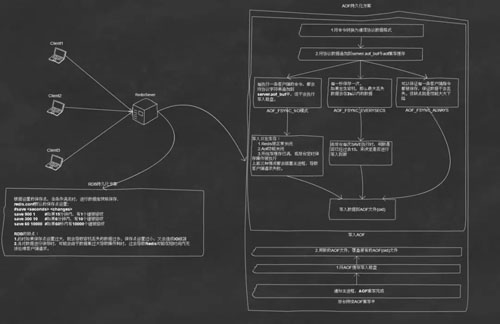
启动的部分过程图解
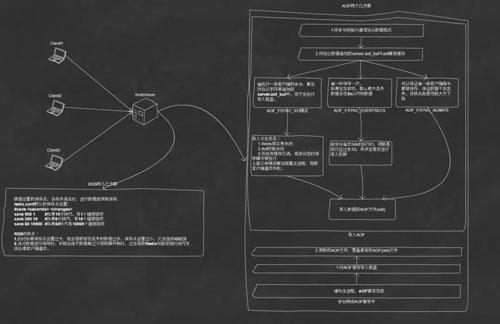
Server 端持久化的部分操作图解
底层哈希表实现(渐进式Rehash)如下图:

初始化字典
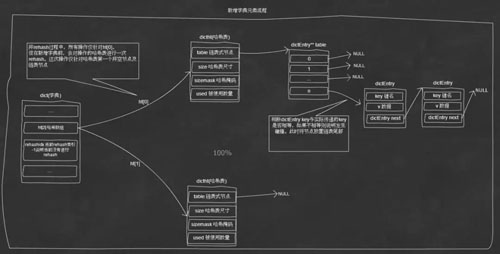
新增字典元素图解
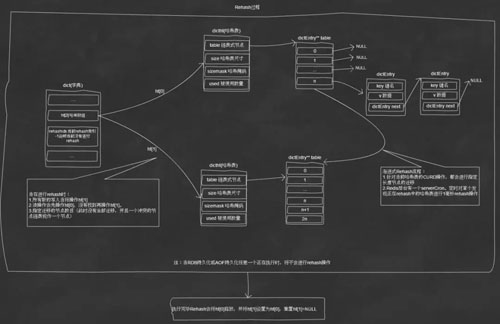
Rehash 执行流程
Redis 的缓存设计原则如下图所示:
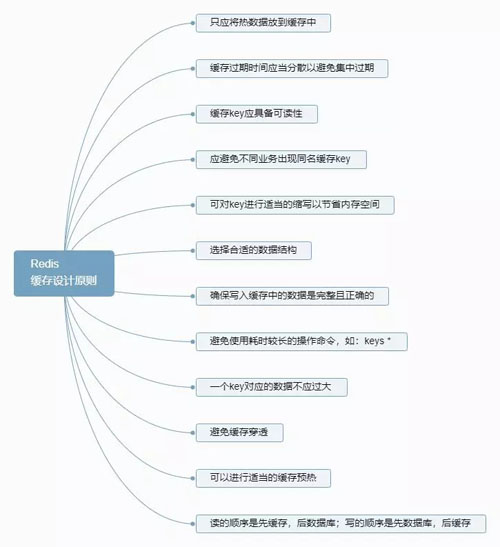
Redis 缓存设计原则
Redis 与 Memcached 的比较如下图:
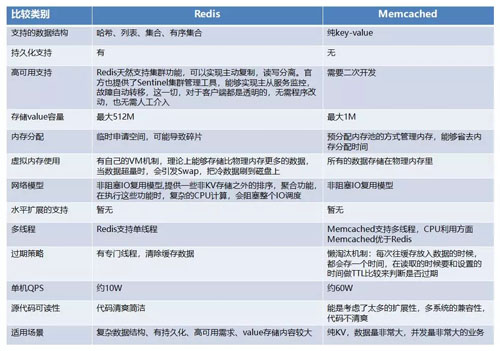
Redis 与 Memcached 比较
下面主要介绍缓存架构设计常见问题以及解决方案,业界案例。
分层缓存架构设计

缓存带来的复杂度问题
常见的问题主要包括如下几点:
1.数据一致性
2.缓存穿透
3.缓存雪崩
4.缓存高可用
5.缓存热点
下面逐一介绍分析这些问题以及相应的解决方案。
数据一致性
因为缓存属于持久化数据的一个副本,因此不可避免的会出现数据不一致问题,导致脏读或读不到数据的情况。
数据不一致,一般是因为网络不稳定或节点故障导致问题出现的常见 3 个场景以及解决方案:
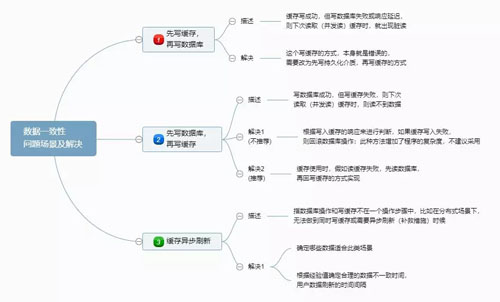
缓存穿透
缓存一般是 Key-Value 方式存在,当某一个 Key 不存在时会查询数据库,假如这个 Key,一直不存在,则会频繁的请求数据库,对数据库造成访问压力。
主要解决方案:
对结果为空的数据也进行缓存,当此 Key 有数据后,清理缓存。
一定不存在的 Key,采用布隆过滤器,建立一个大的 Bitmap 中,查询时通过该 Bitmap 过滤。
缓存雪崩
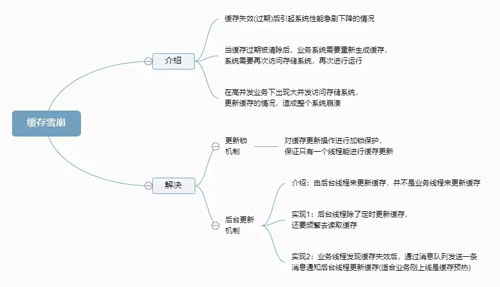
缓存高可用
缓存是否高可用,需要根据实际的场景而定,并不是所有业务都要求缓存高可用,需要结合具体业务,具体情况进行方案设计,例如临界点是否对后端的数据库造成影响。
主要解决方案:
分布式:实现数据的海量缓存。
复制:实现缓存数据节点的高可用。
缓存热点
一些特别热点的数据,高并发访问同一份缓存数据,导致缓存服务器压力过大。
解决:复制多份缓存副本,把请求分散到多个缓存服务器上,减轻缓存热点导致的单台缓存服务器压力
业界案例
案例主要参考新浪微博陈波的技术分享,可以查看原文《百亿级日访问量的应用如何做缓存架构设计?
技术挑战
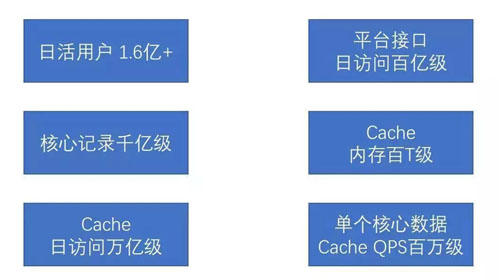
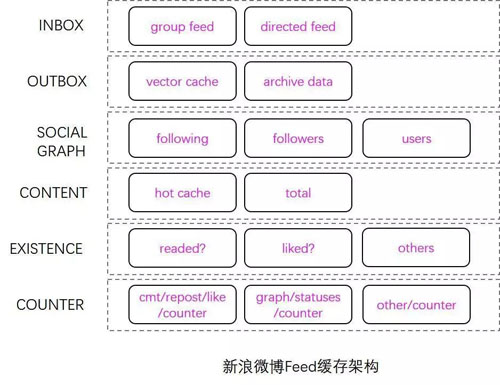
Feed 缓存架构图
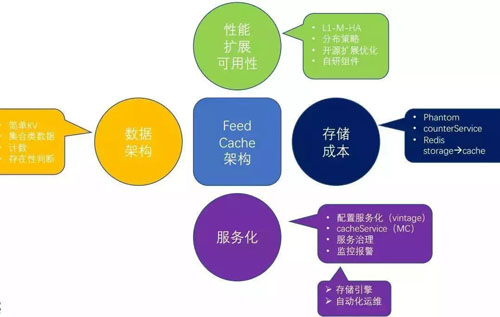
架构特点
新浪微博把 SSD 应用在分布式缓存场景中,将传统的 Redis/MC + MySQL 方式,扩展为 Redis/MC + SSD Cache + MySQL 方式。
SSD Cache 作为 L2 缓存使用,第一降低了 MC/Redis 成本过高,容量小的问题,也解决了穿透 DB 带来的数据库访问压力。
主要在数据架构、性能、储存成本、服务化等不同方面进行了优化增强。

正文到此结束
- 本文标签: src MQ 一致性 java CDN sql 时间 微博 IO 模型 并发 mysql js 集群 Google 图片 分布式系统 反向代理 https 网站 NSA 开源 cache 高可用 缓存 ip cat CSS value Action 高并发 架构设计 db 压力 redis Persistence 分布式 Lua tab 进程 数据 key 数据模型 id Sentinel 服务器 数据库 UI 解析 http 服务端 数据库访问 web map CTO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

