随行付微服务之数据同步Porter
Porter是一款数据同步中间件,主要用于解决同构/异构数据库之间的表级别数据同步问题。
背景
在微服务架构模式下深刻的影响了应用和数据库之间的关系,不像传统多个服务共享一个数据库,微服务架构下每个服务都要有自己的数据库。如果你想获得微服务带来的好处,每个服务独有一个数据库是必须的,因为微服务强调的就是松耦合。我们希望数据库就和服务一样,要有充分的独立性、可以和服务一起部署、一起扩展、一起重构。同时,还需要兼顾数据中心的数据聚合、DBA的多种数据库备份、报表中心的业务报表等等矛盾问题。因此便产生了「Porter」项目。
微服务改造过程中,无法避免的一个坎,那就是垂直拆库,根据不同的子服务,把过去的「一库多服」拆分成「一库一服」。
一库一服还是一库多服?
不管是否是微服务架构,应用的各个模块之间都需要频繁的通信、协作、共享数据,实现系统的整体价值。区别点在于单体应用是通过本地方法调用来完成;在微服务中是通过远程API调用完成。
而共享数据最贱的方式就是采用共享数据库模式,也就是单体应用中最常用的方式,一般只有一个数据库,如图一库多服和一库一服的方式:
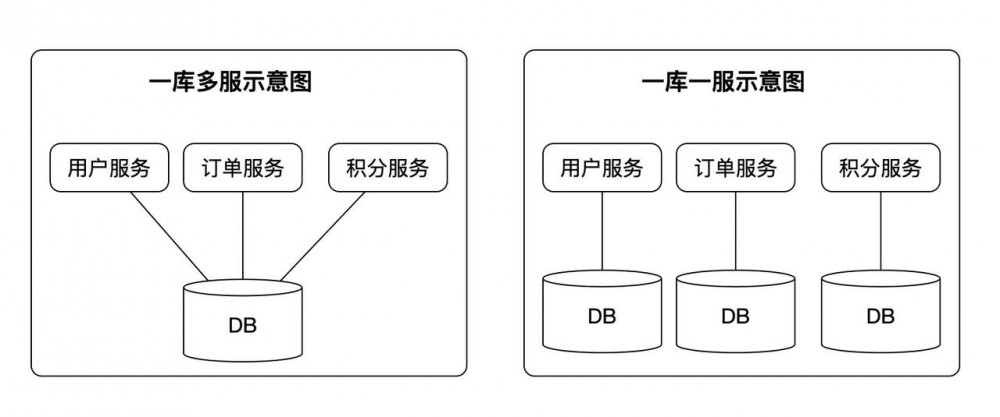
一库多服的架构模式通常会被认为是微服务架构下的反范式,它的问题在于:
-
稳定性:单点故障,一个数据库挂掉,整批服务全部停止。服务独立性被扼杀?
-
耦合性:数据在一起,会给贪图方便的开发或者DBA工程师编写很多数据间高度依赖的程序或者工具;
-
扩展性:无法针对某一个服务进行精准优化或扩展,服务会大体分为两个读多写少、写多读少,数据库优化是根据服务而来的,不是一篇而论。
所以随行付内部一般推荐的做法:是为每一个微服务准备一个单独的数据库,即一库一服模式。这种模式更加适合微服务架构,它满足每一个服务是独立开发、独立部署、独立扩展的特性。当需要对一个服务进行升级或者数据架构改动的时候,无须影响到其他的服务。需要对某个服务进行扩展的时候,也可以手术式的对某一个服务进行局部扩容。
那么问题来了,在改造中我们发现,以下问题,诞生了该项目:
- 报表中心和前端详细页都存在SQL Join方式,经历我们一库一服的拆分后,无法在继续使用SQL Join方式了...
- 数据中心,做得是数据聚合,数据拆分后,给数据中心带来了很大的麻烦...
- 微服务之后,各个应用模块对数据库的要求出现了分歧,数据库类型多元化自主选择还是统一...
- 等等...
Proter介绍
Porter是一个集中式的数据处理通道,所有的数据都在这个数据处理平台汇聚、分发。Porter是一个无中心、插件友好型分布式数据同步中间件。默认注册中心插件实现为zookeeper, 当然,你也可以基于注册中心接口实现自定义注册中心模块。在Porter的主流程外分布着集群插件、源端消费插件、源端消息转换器插件、目标端写入插件、告警插件、自定义数据定义插件等插件模块,除了集群插件、告警插件是Porter任务节点全局作用域外,其余插件模块都随着同步任务的不同而相应组合。得益于良好的设计模式,Porter才能为大家呈现如此灵活的扩展性与易用性。
功能
Porter始于2017年,提供数据同步功能,但并不仅仅局限于数据同步,在随行付内部广泛使用。主要提供一下功能:
- 原生支持Oracle|Mysql到Jdbc关系型数据库最终一致同步
- 插件友好化,支持自定义源端消费插件、目标端载入插件、告警插件等插件二次开发。
- 支持自定义源端、目标端表、字段映射
- 支持节点基于配置文件的同步任务配置。
- 支持管理后台同步任务推送,节点、任务管理。提供任务运行指标监控,节点运行日志、任务异常告警。
- 支持节点资源限流、分配。
- 基于Zookeeper集群插件的分布式架构。支持自定义集群插件。
架构设计
Porter节点通过注册中心实现分布式集群,并根据资源需求动态扩缩容。Portert与注册中心协商了一套任务、节点、统计接口,Porter节点通过监听注册中心接口数据的变化实现任务的分配管理。配置管理后台遵守并实现注册中心的接口规范,实现对Porter节点远程管理。注册中心同样有一套分布式锁机制,用于任务资源的分配。
在这个机制外,Porter节点可以通过本地配置文件的方式实现任务的定义。
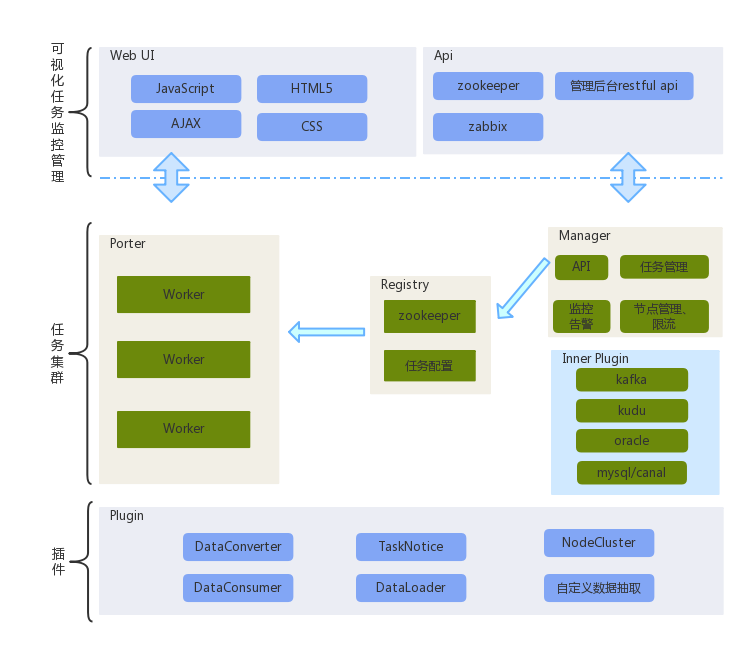
原理介绍:
- 1、基于Canal开源产品,获取MySql数据库增量日志数据。
- 2、管理系统架构。管理节点(web manager)管理工作节点任务编排、数据工作节点(TaskWork)汇报工作进度
- 3、基于Zookeeper集群插件的分布式架构。支持自定义集群插件
- 4、基于Kafka消息组件,每张表对应一个Topic,数据节点分Topic消费工作
处理流程
为了保证数据的一致性,源端数据提取与目标端插入采用单线程顺序执行,中间阶段通过多线程执行提高数据处理速度。对照上图就是SelectJob与LoadJob单线程执行,ExtractJob、TransformJob线程并行执行,然后在LoadJob阶段对数据包进行排序,顺序写入目标端。
正如文章开头所说,告警插件与注册中心插件在多个任务间共享,每个任务根据源端与目标端的类型、源端数据格式选择与之相匹配的处理插件。也就是说告警插件、注册中心插件与Porter节点配置相关,数据消费插件、目标端插件、自定义数据处理插件等插件与任务配置相关。
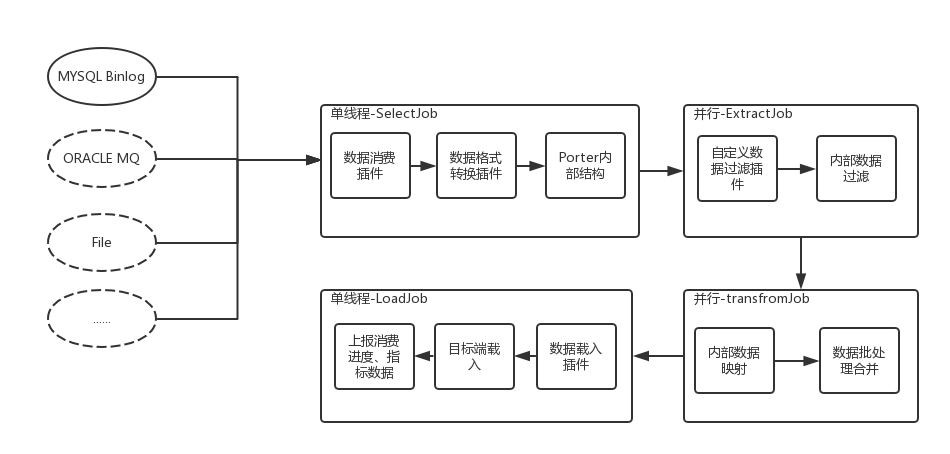
插件化设计
Porter通过SPI规范结合单例、工厂、监听者模式等设计模式,实现了极大的灵活性与松耦合,满足不同场景的二次开发。具体涵盖如下四个方面的插件化设计:
- 注册中心插件
- 源端消费插件
- 目标端载入插件
- 自定义数据处理插件
注册中心插件
在common包META-INF/spring.factories有如下内容:
cn.vbill.middleware.porter.common.cluster.ClusterProvider= cn.vbill.middleware.porter.common.cluster.impl.zookeeper.ZookeeperClusterProvider 复制代码
摘抄ClusterProvider接口定义:
/**
* 匹配配置文件指定的注册中心实现
* @param type
* @return
*/
boolean matches(ClusterPlugin type);
复制代码
porter-boot的配置文件对注册中心的配置如下:
#集群配置 porter.cluster.strategy=ZOOKEEPER porter.cluster.client.url=127.0.0.1:2181 porter.cluster.client.sessionTimeout=100000 复制代码
看到这里,有了配置文件和插件定义,我们还差使配置生效的代码。代码在Porter-boot的启动类NodeBootApplication中:
//初始化集群提供者中间件,spring spi插件
try {
//获取集群配置信息
ClusterProviderProxy.INSTANCE.initialize(config.getCluster());
} catch (Exception e) {
ClusterProviderProxy.INSTANCE.stop();
throw new RuntimeException("集群配置参数ClusterConfig初始化失败, 数据同步节点退出!error:" + e.getMessage());
}
复制代码
ClusterProviderProxy是一个单例枚举类,在initialize中根据spring.factories配置的实现类顺序通过实现类的matches方法匹配配置文件的配置:
List<ClusterProvider> providers = SpringFactoriesLoader.loadFactories(
ClusterProvider.class, JavaFileCompiler.getInstance());
for (ClusterProvider tmp : providers) {
if (tmp.matches(config.getStrategy())) {
tmp.start(config);
provider = tmp;
break;
}
}
复制代码
Porter节点通过注册ClusterListener监听感知注册中心的通知事件,Porter的zookeeper实现在包porter-cluster里,通过ZookeeperClusterMonitor激活:
cn.vbill.middleware.porter.common.cluster.impl.zookeeper.ZookeeperClusterListener=/ cn.vbill.middleware.porter.cluster.zookeeper.ZKClusterTaskListener,/ cn.vbill.middleware.porter.cluster.zookeeper.ZKClusterNodeListener,/ cn.vbill.middleware.porter.cluster.zookeeper.ZKClusterStatisticListener,/ cn.vbill.middleware.porter.cluster.zookeeper.ZKClusterConfigListener 复制代码
源端消费插件
本地配置文件任务配置参数如下,指定了源端消费插件,源端连接信息,数据转换插件,目标端插件等:
node.task[0].taskId=任务ID node.task[0].consumer.consumerName=KafkaFetch #源端消费插件 node.task[0].consumer.converter=oggJson #数据转换插件 node.task[0].consumer.source.sourceType=KAFKA node.task[0].consumer.source.servers=127.0.0.1:9200 node.task[0].consumer.source.topics=kafka主题 node.task[0].consumer.source.group=消费组 node.task[0].consumer.source.oncePollSize=单次消费数据条数 node.task[0].consumer.source.pollTimeOut=100 node.task[0].loader.loaderName=JdbcBatch #目标端插件 node.task[0].loader.source.sourceName=全局目标端数据源名字 复制代码
kafka消费插件“KafkaFetch”定义在porter-plugin/kafka-consumer包,通过META-INF/spring.factories暴露实现:
cn.vbill.middleware.porter.core.consumer.DataConsumer = cn.vbill.middleware.porter.plugin.consumer.kafka.KafkaConsumer 复制代码
通过消费器工厂类DataConsumerFactory查找并激活,这里的consumerName就是在配置文件中配置的“KafkaFetch”
public DataConsumer newConsumer(String consumerName) throws DataConsumerBuildException {
for (DataConsumer t : consumerTemplate) {
if (t.isMatch(consumerName)) {
try {
return t.getClass().newInstance();
} catch (Exception e) {
LOGGER.error("%s", e);
throw new DataConsumerBuildException(e.getMessage());
}
}
}
return null;
}
复制代码
目标端载入插件
要实现目标端载入插件需要继承cn.vbill.middleware.porter.core.consumer.AbstractDataConsumer
//为该插件指定的插件名称,用于在任务配置中指定目标端插件类型
protected String getPluginName();
//LoadJob阶段执单线程执行,实际的目标端插入逻辑,插入对象通过mouldRow()在TransformJob构造
public Pair<Boolean, List<SubmitStatObject>> load(ETLBucket bucket) throws TaskStopTriggerException, InterruptedException;
//transform阶段多线程并行执行,用于自定义处理数据行
public void mouldRow(ETLRow row) throws TaskDataException;
复制代码
完成自定义目标端插件开发后,通过spring SPI机制发布插件
cn.vbill.middleware.porter.core.loader.DataLoader=/ cn.vbill.middleware.porter.plugin.loader.DemoLoader 复制代码
通过载入器工厂类DataLoaderFactory查找并激活,这里的loaderName就是在getPluginName()指定的插件名称
public DataLoader newLoader(String loaderName) throws DataLoaderBuildException {
for (DataLoader t : loaderTemplate) {
if (t.isMatch(loaderName)) {
try {
return t.getClass().newInstance();
} catch (Exception e) {
LOGGER.error("%s", e);
throw new DataLoaderBuildException(e.getMessage());
}
}
}
复制代码
那么在任务配置时如何指定呢?看这里:
porter.task[0].loader.loaderName=目标端插件名称 复制代码
实现细节参考porter-plugin包下的kafka-loader、jdbc-loader、kudu-loader三个目标端
自定义数据处理插件
假设我们要将mysql表T_USER同步到目标端Oracle T_USER_2,源端表T_USER表结构与目标端表T_USER_2一致。我们的需求是只保留FLAG字段等于0的用户数据。
需求有了,接下来我们就要实现EventProcessor接口做自定义数据过滤
package cn.vbill.middleware.porter.plugin;
public class UserFilter implements cn.vbill.middleware.porter.core.event.s.EventProcessor {
@Override
public void process(ETLBucket etlBucket) {
List<ETLRow> rows = etlBucket.getRows().stream().filter(r -> {
//第一步 找到表名为T_USER的记录
boolean tableMatch = r.getFinalTable().equalsIgnoreCase("T_USER");
if (!tableMatch) return tableMatch;
//第二步 找到字段FLAG的值不等于0的记录
boolean columnMatch = r.getColumns().stream().filter(c -> c.getFinalName().equalsIgnoreCase("FLAG")
&& (null == c.getFinalValue() || !c.getFinalValue().equals("0"))).count() > 0;
return tableMatch && columnMatch;
}).collect(Collectors.toList());
//第三步 清除不符合条件的集合
etlBucket.getRows().removeAll(rows);
}
}
复制代码
在任务中指定自定义数据处理插件:
porter.task[0].taskId=任务ID porter.task[0].consumer.consumerName=CanalFetch porter.task[0].consumer.converter=canalRow porter.task[0].consumer.source.sourceType=CANAL porter.task[0].consumer.source.slaveId=0 porter.task[0].consumer.source.address=127.0.0.1:3306 porter.task[0].consumer.source.database=数据库 porter.task[0].consumer.source.username=账号 porter.task[0].consumer.source.password=密码 porter.task[0].consumer.source.filter=*./.t_user porter.task[0].consumer.eventProcessor.className=cn.vbill.middleware.porter.plugin.UserFilter porter.task[0].consumer.eventProcessor.content=/path/UserFilter.class porter.task[0].loader.loaderName=JdbcBatch #目标端插件 porter.task[0].loader.source.sourceType=JDBC porter.task[0].loader.source.dbType=ORACLE porter.task[0].loader.source.url=jdbc:oracle:thin:@//127.0.0.1:1521/oracledb porter.task[0].loader.source.userName=demo porter.task[0].loader.source.password=demo porter.task[0].mapper[0].auto=false porter.task[0].mapper[0].table=T_USER,T_USER_2 复制代码
集群机制
Porter的集群模式依赖集群插件,默认的集群插件基于zookeeper实现。Porter任务节点和管理节点并不是强制绑定关系,任务部署可以通过任务配置文件,也可以通过管理节点推送。管理节点还可以管理节点、收集、展示监控指标信息等,是一个不错的、简化运维的管理平台。同样的,可以基于zookeeper数据结构协议实现你自己的管理平台。
集群模式下的系统结构:
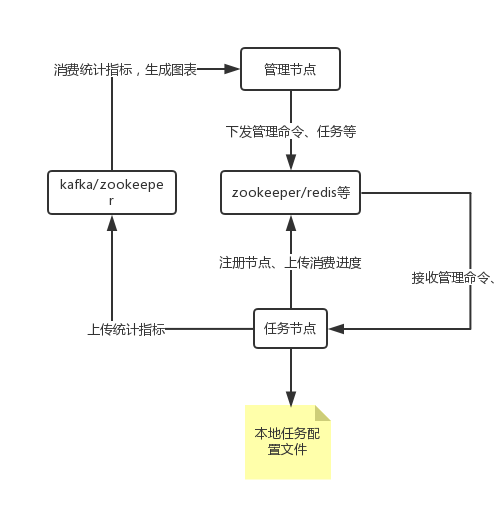
zookeeper集群模式插件
zookeeper数据结构协议: {% asset_img zk_data_schema.png zk_data_schema.png %}
Porter的集群机制主要有以下功能:
- 实现节点任务的负载,当前任务节点失效后自动漂移到其他任务节点
- 实现任务节点与管理节点的通信
- 实现任务处理进度的存储与拉取
- 实现统计指标数据的上传(最新的开发版本支持自定义统计指标上传客户端,原生支持kafka)
- 用于节点、任务抢占的分布式锁实现
基于文件系统的单机模式插件
最新开发版支持Porter任务节点以单机模式运行,不依赖管理后台和zookeeper,通过配置文件配置任务。单机模式是一种特殊的集群模式,仅支持部分集群功能,但简化了任务部署的复杂性,灵活多变。
- 实现任务处理进度的存储与拉取
- 实现统计指标数据的上传
Porter任务节点运行模式的配置方式
#zookeeper集群配置 porter.cluster.strategy=ZOOKEEPER porter.cluster.client.url=127.0.0.1:2181 porter.cluster.client.sessionTimeout=100000 #单机模式配置 porter.cluster.strategy=STANDALONE porter.cluster.client.home=/path/.porter 复制代码
最后
笔者在开源Porter之前有幸参与apache skywalking社区并受其感召,随后参与sharding-sphere等多个开源项目。我们竭尽所能提供优质的开源软件,为中国的开源社区贡献一份力量。但受限于技术能力及开源社区的运营经验,不足之处,恳求大家的批评指正。
Porter的更多实现细节,请移步开源网站。
开源中国: gitee.com/sxfad/porte…
GitHub: github.com/sxfad/porte…
Porter插件开发demo: github.com/sxfad/porte…
Porter开源:835209101

本分类文章,与「随行付研究院」微信号文章同步,第一时间接收公众号推送,请关注「随行付研究院」公众号。 复制代码

正文到此结束
- 本文标签: 网站 开源软件 代码 value 开源 src 文章 文件系统 sharding 微服务 备份 js cat UI GitHub json final client Word IO 分布式锁 限流 web https 产品 系统架构 多线程 Select 锁 build http plugin Mysql数据库 Proxy apache git 线程 配置 API App 开发 schema ask mapper 工程师 JDBC java db 数据库 map 管理 CTO 参数 同步 运营 ORM 一致性 equals spring node Oracle sql 开源项目 设计模式 软件 consumer DDL message 分布式 session mysql tab zookeeper IDE 时间 插件 provider 统计 trigger id 注册中心 插件开发 tar 集群 数据 需求 list core Job 希望 架构设计 stream 协议
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

