订单贡献率10%,京东个性化推荐系统持续优化的奥秘
在信息过剩的互联网时代,个性化推荐技术对于互联网公司运营的重要性自不待言。本文要谈的是京东商城最新的推荐系统。京东已经在新版首页上线了“今日推荐”和“猜你喜欢”两项功能,基于大数据和个性化推荐算法,实现了向不同用户展示不同的内容的效果(俗称“千人千面”),该系统目前在PC端和移动端都已经为京东贡献了10%的订单。为了探索京东全品类平台“千人千面”背后的算法奥妙,CSDN记者采访了推荐搜索部总监刘尚堃。
京东推荐系统三部曲
总体而言,京东推荐算法的步骤并不神秘,无非是建立召回模型——召回模型效率分析——排序模型三步。但这并不意味着每一步的具体实现都是简单的事情。刘尚堃对此做了详细的解析。
召回模型
召回模型,即候选集的获取,大体从基于用户历史行为的召回、基于用户偏好的召回、基于地域的召回三个维度来实现。
基于行为的召回 ,根据用户购买行为推荐相关/相似的商品。大家都知道根据用户的浏览记录推荐相似商品,但京东更进一步地把购买行为视为一个重要的分界线,当用户已购买某个商品,京东会根据商品种类和用途选择推荐相关/相似的商品,而不是没玩没了地重复推荐,比如为Kindle买家推荐Kindle保护套而不是Kindle。当然,对于如肥皂、洗发水之类的日用品,会根据一个购买周期来再次推荐。
基于用户偏好的召回 包括了两个重要的元素:用户画像和多屏互通。结合商品品牌、适用人群、价格指数以及用户对商品的点击、购买、关注和收藏等行为,京东对用户进行画像,从而确定可以长期推荐的品类。针对移动时代的购物新习惯,京东还注意到了根据用户ID及MEI等信息融合不同的终端的数据,包括PC端、移动APP、微信和手Q,从而做到更加精准的画像。当然,在最终的内容展示上,会根据终端的差异选择不同的展示结果。
基于地域的召回 ,把整个地图划分多个网格运用数据统计结果。以北京为例,三里屯地区用户更感兴趣的商品是扑克牌、水等,中低端小学校的数据主要集中在袜子、晾衣架等等。基于地域的召回主要用于在京东用户行为比较时候少的新用户。
召回模型效率分析
具体的技术实现,三类模型当然会包含多个子模型,例如在线相关,在线相似,离线相关,离线相似,近期热销品牌品类等,都加入到模型当中。那么问题来了:对某个具体的用户,到底要使用哪个模型?这就涉及到模型效率分析。评判某个模型效率的高低,主要是看该模型带来的点击率、转发率、 GMV等。
刘尚堃给出了一个重要的结论:基于用户实时行为建立的模型,它的效率更高一些,比如说在线相关的产品和在线相似的推荐。为了达到更好的效果,京东采用了多个模型融合的算法,而不是使用单一模型去做。刘尚堃表示,合适的模型组合在一起,总体效率可以达到最高。如果某个模型效率较低,它就会只占据较小的流量,实现总体流量价值最大化。当然,是针对不同的人采用不同的模型组合。
效率提升主要来自最近尝试的两个模型:最近点击和最近关注的商品模型,和加入购物车的商品模型。前者是指将最近浏览过的商品推荐到首页,后者是将放入购物车未购买的商品推荐给用户,实验的结果,转化率的提升分别达到了100%和5%-10%。
排序模型
在模型融合的基础上,京东还进行排序学习,推荐排序的问题转化为分类的问题去实现,即从用户的交互日志中通过模型训练特征权重,再通过L2R排序学习算法来改进,转化率又获得了20%的提升。
刘尚堃透露,京东推荐搜索部也有过包括逻辑回归在内的多种尝试,包括Vowpal Wabbit(VW)、排序学习、PMI等等,但逻辑回归算法只有1%的提升,而排序学习有20%的提升。
每周迭代7 个新算法的架构
不管是模型本身优化的需求,抑或因为用户偏好随着时间或条件变化,持续的迭代都是必不可少的,也就是说特征的增加、修改或者不同的组合,这些工作几乎都是常态。事实上,京东平均每周就有7个新的算法实验上线。这需要一个很好的推荐架构来支持算法的高速迭代。基于HBase、Storm、Spark以及MapReduce等,京东搭建了自己的推荐架构,具体如下图所示:
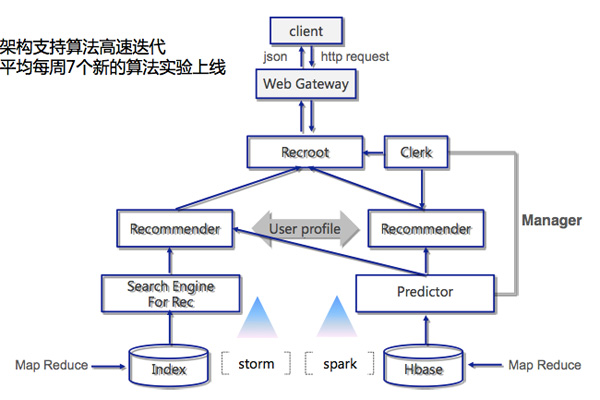
刘尚堃认为,Spark分布式计算框架对大数据的支持好,效率高,同时提供了不断改进的MLlib机器学习库,对协同过滤等常用于推荐系统的机器学习算法支持很好,使用起来很方便。
经验与未来优化
由于个性化首页产品上线还不到一个月,刘尚堃相信,当前推荐位的情况下,还有提升 40%-50%的提升空间。
整体来看,京东推荐系统的主要经验如下:
积累更多、更新的数据支持迭代。 京东具有庞大的用户量和全品类的商品,能够根据用户浏览、点击、购买、评论数据以及品牌、品类、描述等商品自身的数据的积累,分别做基于用户和基于商品的协同过滤,更精确地进行个性化推荐。为了与时俱进,京东不仅做多屏互通,还正在规划与腾讯合作获取一些关系数据,包括针对微信朋友圈数据挖掘出不同用户的偏好,并将其作用到推荐结果中来。
开源工具的利用。 比如实时行为模型的利用、排序算法的实现,都离不开Spark的支持。此外,京东也会基于一些开源算法针对自身业务场景做一些修改,来实现更好的推荐效果。
效率是评判推荐模型的标准。 例如逻辑回归,本来被寄予厚望,却效果不佳;本来不屑一顾的最近点击和最近关注模型,反而能实现100%的转化提升。这里补充说明:京东评判模型效率采用了先验和后验结合的方式,先验是用一些排序预测算法去预测模型,得到一个最佳模型组合的方案,配备给每个用户,后验即基于更精细化的模型效率分析,找出能够提升效率的最佳模型。
深度学习是未来推荐的方向。 特征的选择仍然是难点。特征选择、特征提取对机器学习而言都是大课题,而机器学习又是模型排序与融合从而持续提升转化率的关键。很自然地,排序特征的丰富是京东未来迭代优化的一个主要方向。
刘尚堃表示,将京东正在研发的DNN深度学习技术应用于排序是未来要做的事情,当然,还有用于线性低维空间模型的逻辑回归,预计提升5%转化率。据我们了解,京东DNN Lab的研究成果已经目前应用于京东智能客服机器人。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

