微服务熔断隔离机制及注意事项
导读:本文重点分析微服务化过程中熔断机制及应用注意事项,包括微服务调用与“雪崩效应”及解决方案、熔断机制及考虑因素、隔离机制及实现方式考量等内容。
随着企业微服务化战略的实施,业务功能细分,越来越多的服务从原有的单体应用中分解成一系列独立开发、部署、运维的微小服务,服务之间则依赖于各种RPC框架互相通信。纵然,微服务化有着很多优势,但与之伴随而来的是各种复杂性,对开发人员来说,除了业务领域本身外,还需要考虑由于服务拆分之后诸如分布式事务、服务部署及运维、rpc调用等系列问题,本文将重点分析微服务化过程中熔断机制及应用注意事项。
微服务调用与“雪崩效应”:
微服务化之后服务之间调用关系复杂,调用层级深,服务之间依靠rpc框架进行通信,如下图1,实线是同步rpc调用,虚
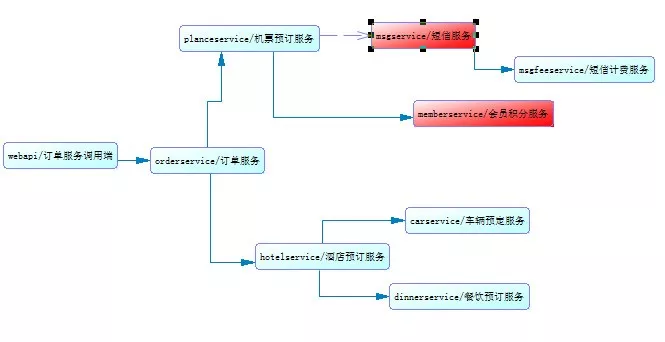
图1 服务调用关系
线则是异步rpc调用,整个调用链路从webapi开始到dinnerservice结束,红色节点则表示该服务不可用或高延迟,异步调用msgservice异常对链路返回结果并无影响,而同步调用(memberservice服务)的性能对链路则有很大影响,其会造成链路上planeservice、orderservice及webapi服务堵住,堵着的请求会耗费线程及io资源,随着此类请求越来越多,特别是在流量高峰时,如果不能及时解决memberservice的问题,最终将把整条链路堵死,造成webapi不能对外提供服务,提供崩溃,这就是所谓的雪崩效应。
雪崩效应解决方案:
针对雪崩效应的情况,通常我们可以有如下几中方案来解决。
一、同步调用异步化方案。如图所示,异步调用对于调用方来说,不会造成堵塞,从而将调用方保护起来。因此,可从业务层面设计入手,将不需要及时返回结果的业务调用设计成异步来调用。典型场景,注册验证码发送,消息通知等。
二、限流方案。通过限制入口流量,将并发限制在一定范围内,能在一定程度上避免雪崩效应,如果不可用服务是部分不可用或超时时。 以上方案都不能彻底解决问题症结,那真正比较可行的则是第三种,应用熔断隔离机制的方案。熔断,就像电路短路,当电压过高,负载加重时,保险丝就会自动断开,避免事故发生。在微服务中,当链路上某个服务不可用或延迟严重,达到熔断器设定指标阈值时,则触发熔断机制,对于后续请求直接返回默认结果或抛出异常,避免整个链路因为部分服务不可用而雪崩。隔离则是服务调用方将耗时的方法或rpc调用与业务代码隔离开来,避免耗时方法或rpc调用造成服务堵塞。
熔断机制及考虑因素:
熔断机制具体实现体现为一个熔断器,如何实现熔断器,主要考虑以下几个方面。
第一,熔断请求判断算法即熔断在什么条件处于开启状态,什么条件处于关闭或半关闭状态。使用滑动时间窗口来记录每个时间片内相关熔断计数指标及熔断器状态,这个时间片段称作为一个bucket,默认维护10个bucket,每1秒一个bucket,随着时间的滚动,最早的bucket抛弃,创建新的bucket到滑动窗口右边。每个blucket记录请求总数、成功数、超时数、拒绝数及熔断器状态,默认错误超过50%且10秒内超过20个请求进行中断拦截。
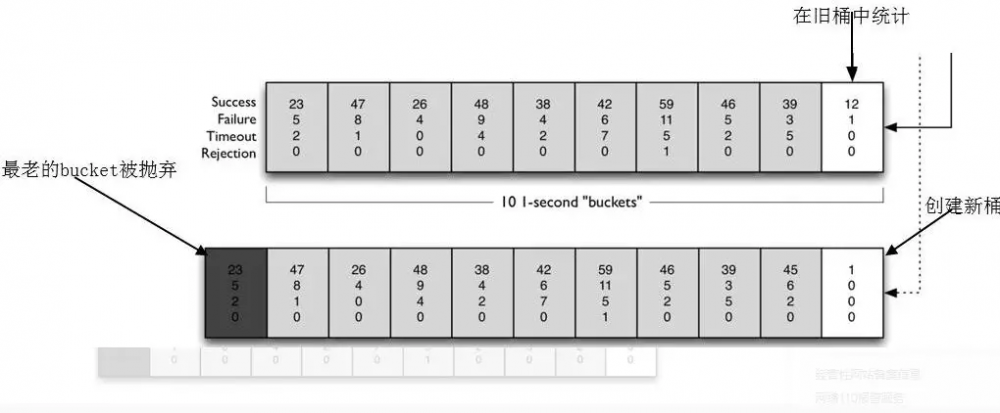
图2 滑动窗口
第二、熔断恢复。默认情况下,熔断器处于闭合状态,当熔断指标达到阈值时,熔断器状态变为打开状态,此时,所有请求直接返回或抛出异常。过了一段时间后,后端异常服务经过开发运维人员及时解决了问题,熔断器如何知晓呢?如果没有一定的熔断恢复机制,那一旦熔断器打开,就不能再闭合上,显然不合情理。因此,熔断器需要有放行规则,对于熔断器开启状态超5s以内的请求,直接熔断,如果熔断器开启超过5s,则进入半开启状态,可以按一定规则,允许部分请求通过,试探性的调用被隔离的服务,若请求如是健康状态,则恢复关闭熔断器,如下图3是熔断器状态转换关系。
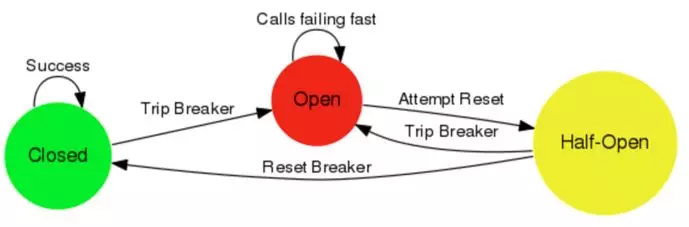
图3熔断器状态转换
第三、熔断后如何处理请求。当熔断器处于打开状态时,请求直接返回,业务如何知道当前发生了状况?可向业务层抛出特定异常,用于标识当前熔断器打开,但熔断器通常通过降级措施来处理,提供提供降级接口或实现,由熔断器自行处理降级措施,开发人员只需要实现降级逻辑即可,其它事情就交给熔断器来处理。
隔离机制及实现方式考量:
隔离机制也是为了保护微服务链路调用中避免雪崩效应的一种策略,与熔断配合使用,隔离机制可以有两种实现。
一、线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)。 二、信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1.这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)。 线程池隔和限号量隔离机制各有利弊,在使用信号量隔离时,最大的弊端是不能实现超时返回,这有时对业务是致命的,一旦后端服务超时时间过长,已经发起的调用无法及时返回,导致资源堵塞,调用方长时间等待。而线程池隔离机制可以解决超时返回的问题,线程池隔离机制问题在于在微服务之间通过rpc调用,无论是我们自研的rpc框架,还是开源的rpc框架如dububo等,都可能会使用Threadlocal来缓存本地线程变量来传递上下文信息,服务端接收到调用的传过来请求时,需要将请求中附带的上下文信息保存到当前线程的Threadlocal变量中,当服务端调用其它其它服务时,需要将上下文信息从Threadlocal取出来再传递给下游服务,在tomcat线程模型下工作正常,但此时如果将对rpc的调用进行线程隔离后,由于线程复用问题,导致在隔离线程中执行rpc调用时服务获取不到调用线程中的Threadlocal变量,这会导致链路跟踪信息无法传递等问题,在实践中需要引起特别注意,此问题关键是要解决跨线程间Threadlocal变量传递,至于如何传递,可以参考jdk的InheritableThreadlocal机制,他解决了父子进程间Threadlocal变量继承问题,提供了一种解决此问题的思路,但线程隔离机制,比如Hystrix通常都是通过线程池来实现,避免反复创建销毁线程带来的性能损耗,但隔离线程与调用线程没有父子关系,因此需要自行解决Threadlocal变量跨线程的问题。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

