开发笔记 – Spring Boot集成HBase
最近在重新整理 搜书吧 (一个做图书比价的平台)的系统架构,目前图书产品数量超过了200万条。各种数据加起来超过40G了,使用Mysql数据库存储服务器吃不消,于是考虑使用HBase存储大部分数据。
一、摘要
以前 搜书吧 的数据量比较小,使用数据库+静态文件存储的方式就可以搞定,主要有2个系统组成:网站前端+后台服务。事先把图书详情等一些固定内容生成html静态文件和前端的其他静态文件打包部署,动态变化的数据使用js通过REST接口获取。后台服务系统主要处理业务逻辑以及提供REST接口调用(为节省资源,很多其他个人项目的后台服务也运行在这个系统上)。现在图书数量增加到了200多万条,数据量比原来大很多,使用一台服务器不仅硬盘不足,Mysql存储内容太多,内存资源也不够用。于是想借鉴微服务的解决方案,使用Spring Boot+HBase搭建单独的服务,作为一个小型的数据中心,可为不同的项目存储数据。
二、软件
- Ubuntu 16.04
- IntelliJ IDEA 2018.01
- JDK 1.8.0
- Hadoop 2.8.5
- HBase 2.1.0
- spring-data-hadoop 2.5.0
- hbase-client 1.4.4
三、HBase介绍
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建起大规模集群。它是一个可以随机访问的存储和检索数据的平台,允许动态的灵活的数据模型。
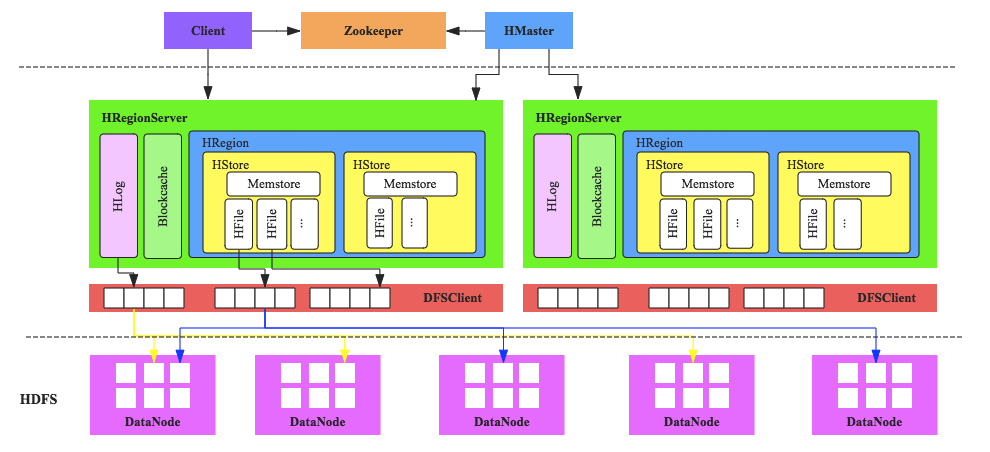
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion服务器(HRegion Server)和HMaster 服务器组成。HMaster负责管理所有的HRegion服务器,而HBase中的所有的服务器都是通过zookeeper来进行协调并处理HBase服务器运行期间可能遇到的错误。HBase Master并不存储HBase中的任何数据.HBase逻辑上的表可能会被划分成多个HRegion,然后存储到HRegion服务器中,HBase Master服务器中存储的是从数据到HRegion 服务器的映射。
四、SSH/HOST等安装配置
4.1 修改主机名
由于我使用的是 阿里云 的ECS,主机名有点长,先修改主机名称。输入一下命令,把名称修改自己想要的即可,比如我的修改为luoxudong02,修改完以后重启系统。
vim /etc/hostname
4.2 修改host
vim /etc/hosts
增加一条主机映射记录,其中前面为IP,后面为主机名称。IP地址需要是主机内网IP(可以使用ifconfig查看),阿里云ECS有一个公网IP,有一个私有IP,需要填写私有IP。

4.3 创建用户
为了方便管理,创建一个hadoop用户,如果是完全分布式的话要创建一个用户组,因为master和slaves要求用户和组要完全一样。
创建hadoop用户,并使用/bin/bash作为shell
sudo useradd -m hadoop -s /bin/bash
为hadoop用户设置密码
sudo passwd hadoop
为了后续操作方便,增加管理员权限
sudo adduser hadoop sudo
后续的操作都切换到hadoop用户下执行。
4.4 配置SSH免密登录
如果没有安装openssh-server则先安装
sudo apt-get install openssh-server
先创建秘钥
ssh-keygen -t rsa
一直按回车即可,完成以后把新创建的秘钥追加到autorized_keys中,该文件没有的话会自动创建。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
五、JDK安装配置
5.1 下载JDK
下载JDK1.8,从官网下载对应环境的安装包: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 。
下载完成以后解压到指定位置
tar -zxvf jdk-8u191-linux-x64.tar.gz -C ~/local
配置JDK环境变量,打开~/.bashrc文件,
vim ~/.bashrc
在文件最后添加以下代码。
export JAVA_HOME=~/local/jdk1.8.0_191 export CLASSPAT=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
使配置生效
source ~/.bashrc
六、Hadoop+HBase环境搭建
由于我只有一台空闲的服务器,所以目前我只是搭建了伪分布式环境,后续再根据需要扩展。
下载安装包时要选择对应的版本号,要不然会容易采坑。大家可以查看 官方文档 ,里面有介绍详细的配置要求。
6.1 环境要求
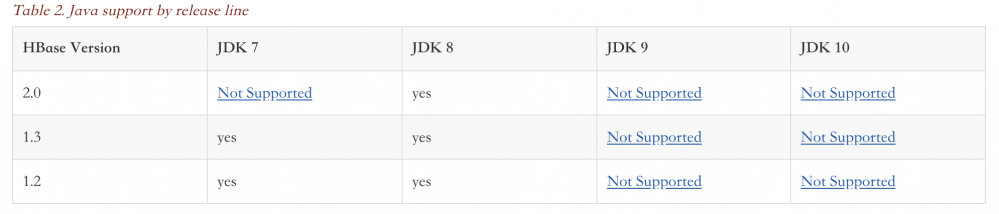
下面的表格是JDK版本的要求,其中JDK8是支持所有版本
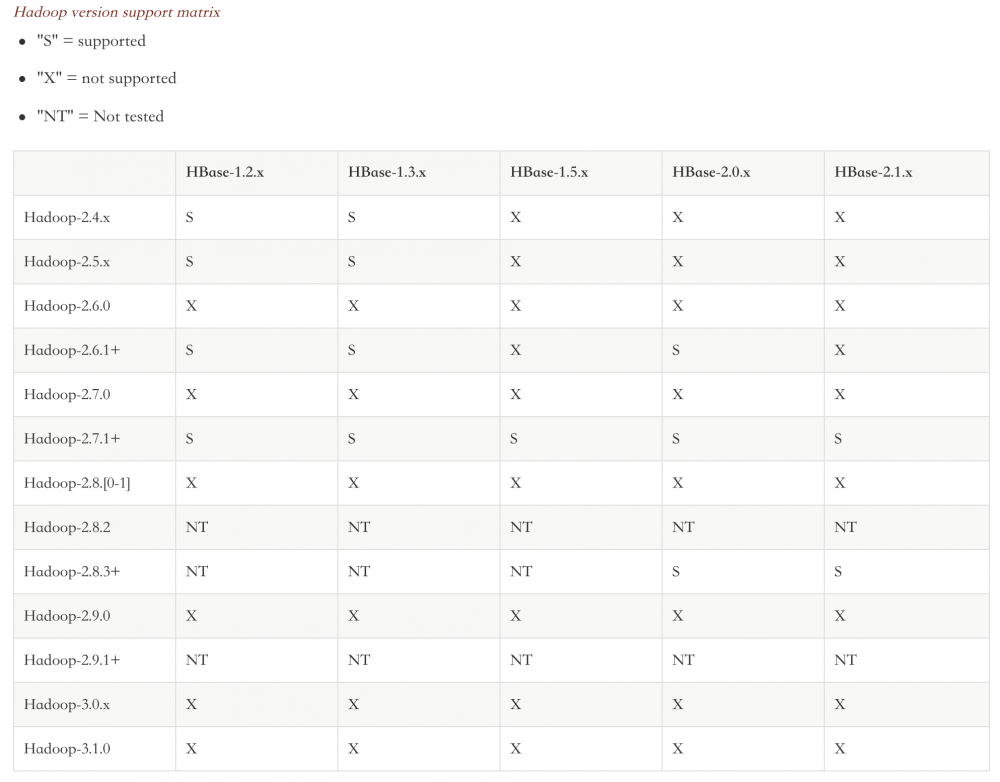
以下是各版本的Hadoop和HBase对应表,从表格可以看出,支持的最新版本是Hadoop-2.83+和HBase-2.1.x。我选择的是 Hadoop2.8.5 和 HBase-2.1.0 。
6.2 安装配置Hadoop
6.2.1 下载安装包
从官网下载Hadoop安装包,我安装的版本是2.8.5,下载地址: https://www-eu.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz 。下载后解压到指定目录。
tar -zxvf hadoop-2.8.5.tar.gz -C ~/local
解压以后Hadoop目录名称带版本号,大家可以重命名,去掉版本号,方便维护。
6.2.2 配置环境变量
跟JDK配置类似,打开bashrc文件,在后面添加一下代码
export HADOOP_HOME=~/local/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
6.2.3 设置Hadoop配置文件
进入${HADOOP_HOME}/etc/hadoop目录,修改一下几个文件
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml(mapred-site.xml.template重命名)
- slaves
1) hadoop-env.sh文件
如果文件中没有配置JAVA_HOME,如果存在以下代码则不需要修改。
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
否则需要在文件最后配置JDK路径
export JAVA_HOME=~/local/jdk1.8.0_191(如果文件中已经存在export JAVA_HOME=${JAVA_HOME}就可以不需要)
2) core-site.xml文件
在configuration节点中加入以下代码:
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://luoxudong02:9000</value>
</property>
hadoop.tmp.dir是HDFS与本地磁盘的临时文件,是文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置在/tmp/{$user}下面。需要指定一个持久化路径,否则系统tmp被自动清掉以后会出 fs.defaultFS是默认文件系统的名称,通常是NameNode的hostname:port,其中luoxudong02是主机名称,9000是默认端口号
3) hdfs-site.xml文件
在configuration节点中加入以下代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/local/hadoop/dfsdata/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/local/hadoop/dfsdata/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
dfs.replication 是指在文件被下入的时候,每一块将要被复制多少份,默认是3,单主机设置1就可以了
dfs.namenode.name.dir 是NameNode元数据存放位置,默认存放在${hadoop.tmp.dir}/dfs/name目录。
dfs.datanode.data.dir 是DataNode在本地磁盘存放block的位置,可以使用逗号分隔的目录列表,默认存放在${hadoop.tmp.dir}/dfs/data目录。
dfs.permissions 标识是否要检查权限,默认是true,设置false则允许每个人都可以存取文件。
4) yarn-site.xml文件
在configuration节点中加入以下代码:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>luoxudong02</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
yarn.resourcemaneger.hostname 指定主机名称
5) mapred-site.xml文件
这个文件本身是不存在,需要把目录中的mapred-site.xml.template重命名,在其中的configuration节点加入以下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6) slaves文件
把文件内容改成主机名称,如:luoxudong02
这样配置基本就完成了,接下来启动hadoop
第一次启动之前需要格式化HDFS(只需要执行一次,后面启动Hadoop服务器不需要执行格式化命令)
bin/hdfs namenode -format
启动服务
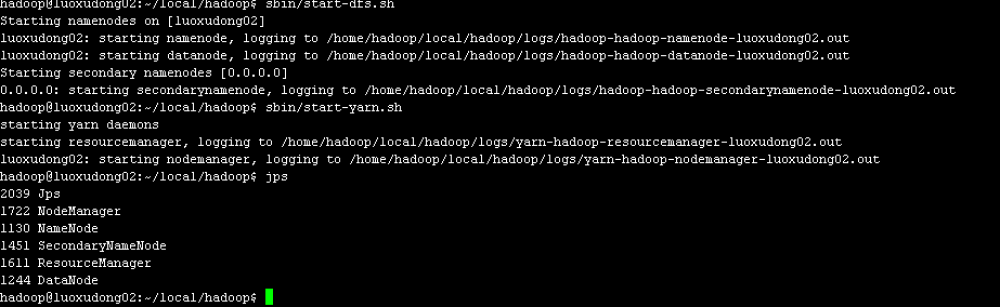
sbin/start-dfs.sh sbin/start-yarn.sh
然后输入jps命令,如果启动成功将会看到以下服务
6.3 安装配置HBase
6.3.1 下载安装包
从官网下载HBase安装包,我安装的是HBase-2.1.0,官网下载地址: http://archive.apache.org/dist/hbase/2.1.0/hbase-2.1.0-bin.tar.gz 。下载完成后解压到指定目录
tar -zxvf hbase-2.1.0-bin.tar.gz -C ~/local
把解压后的目录名称修改为HBase,去掉版本号。
6.3.2 配置环境变量
跟JDK配置类似,打开bashrc文件,在后面添加一下代码
export HBASE_HOME=~/local/hbase export PATH=$HBASE_HOME/bin:$PATH
重新整理JDK、Hadoop和HBase的环境变量后如下
export JAVA_HOME=~/local/jdk1.8.0_191 export CLASSPAT=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib export HADOOP_HOME=~/local/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export HBASE_HOME=~/local/hbase export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$PATH
6.3.3 设置HBase配置文件
HBase配置稍微简单一些,只需要配置3个文件
- hbase-env.sh
- hbase-site.xml
- regionservers
1) hbase-env.sh文件
修改两个地方
export JAVA_HOME=~/local/jdk1.8.0_191 export HBASE_MANAGES_ZK=true
第一行是关联JDK路径,第二个是指定使用HBase自带的ZK。
2) hbase-site.xml文件
在configuration节点中增加以下代码:
<property>
<name>hbase.zookeeper.quorum</name>
<value>luoxudong02</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/local/hbase/zkdata</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/local/hbase/tmp</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://luoxudong02:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
hbase.zookeeper.quorum是集群的地址列表,使用逗号分割开,由于我们使用的是伪分布式,只有一台主机,设置成主机名称就可以。
hbase.zookeeper.property.dataDir是快照的存储位置
hbase.tmp.dir是本地文件系统的临时文件夹
hbase.rootdir是regionserver的共享目录,用来持久化HBase
hbase.cluster.distributed指运行模式,false表示单机模式,true标识分布式模式
3) 修改regionservers文件
把内容修改成主机名称,如:luoxudong02
这样基本配置完成,接下来启动服务
bin/start-hbase.sh
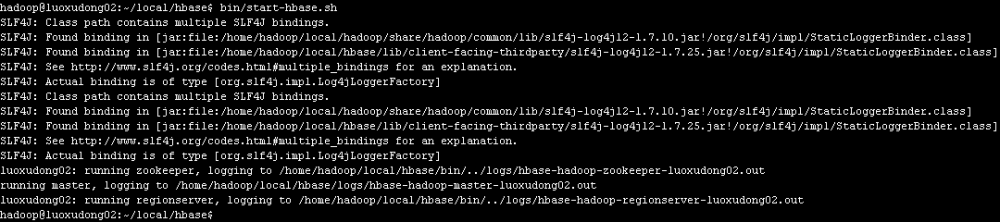
这里有一个小问题,启动的时候提示slg4j有多个,那是因为hadoop安装包下和hbase安装包下都存在,网上有人说删除hbase安装包下的slf4j-log412文件,我试了下删除会包其他错误,导致hbase无法正常启动,暂时没有找到比较好的解决办法。由于不影响使用,暂时不管。
Hadoop和HBase成功启动后会有以下服务

大家在启动后可能发现HMaster服务或者HRegionServer服务没有。通过查看log/hbase-hadoop-master-主机名.log中的日志发下出现类似以下错误:
java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:635)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:619)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:149)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2669)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:94)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2703)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2685)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:373)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:295)
at org.apache.hadoop.hbase.util.CommonFSUtils.getRootDir(CommonFSUtils.java:358)
at org.apache.hadoop.hbase.util.CommonFSUtils.isValidWALRootDir(CommonFSUtils.java:407)
at org.apache.hadoop.hbase.util.CommonFSUtils.getWALRootDir(CommonFSUtils.java:383)
at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:691)
at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:600)
at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:484)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2965)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:236)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:140)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2983)
这时需要把HBase下的lib/client-facing-thirdparty/htrace-core-xxx.jar包拷贝到lib下
cp lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar lib/
然后再重新启动HBase就可以了,如果发现还是启动失败,可以查看日志,针对具体问题google一下。
启动成功以后可以通过HBase shell命令测试一下。
Hadoop和HBase的配置就完成了,接下来通过Spring Boot创建一个Web服务来访问HBase。
6.4 Spring Boot配置
Spring Boot配置比较简单
6.4.1 HOST配置
打开本地hosts文件,添加HBase主机映射,跟Hadoop服务器配置的host类似,有一点不同就是IP地址需要是Master主机的外网IP地址。
6.4.2 添加依赖包
我是使用maven来管理jar包,在pom.xml中增加以下依赖包
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop-boot</artifactId>
<version>2.5.0.RELEASE</version>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.5.0.RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.4</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>2.11.0</version>
</dependency>
6.4.3 新建HBaseProperties.java
package com.luoxudong.bigdata.config;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.util.Map;
@ConfigurationProperties(prefix = "hbase")
public class HBaseProperties {
private Map<String, String> config;
public Map<String, String> getConfig() {
return config;
}
public void setConfig(Map<String, String> config) {
this.config = config;
}
}
6.4.4 新建HBaseConfig.java
package com.luoxudong.bigdata.config;
import java.util.Map;
import java.util.Set;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.hadoop.hbase.HbaseTemplate;
@Configuration
@EnableConfigurationProperties(HBaseProperties.class)
public class HBaseConfig {
private final HBaseProperties properties;
public HBaseConfig(HBaseProperties properties) {
this.properties = properties;
}
@Bean
public HbaseTemplate hbaseTemplate() {
HbaseTemplate hbaseTemplate = new HbaseTemplate();
hbaseTemplate.setConfiguration(configuration());
hbaseTemplate.setAutoFlush(true);
return hbaseTemplate;
}
public org.apache.hadoop.conf.Configuration configuration() {
org.apache.hadoop.conf.Configuration configuration = HBaseConfiguration.create();
Map<String, String> config = properties.getConfig();
Set<String> keySet = config.keySet();
for (String key : keySet) {
configuration.set(key, config.get(key));
}
return configuration;
}
}
6.4.5 application.yml配置
hbase:
config:
hbase.zookeeper.quorum: luoxudong02
hbase.zookeeper.property.clientPort: 2181
6.4.6 使用
配置基本完成,然后再需要的地方应用HaseTemplate对象对hbase进行操作。
@Autowired private HbaseTemplate hbaseTemplate;
七、注意事项
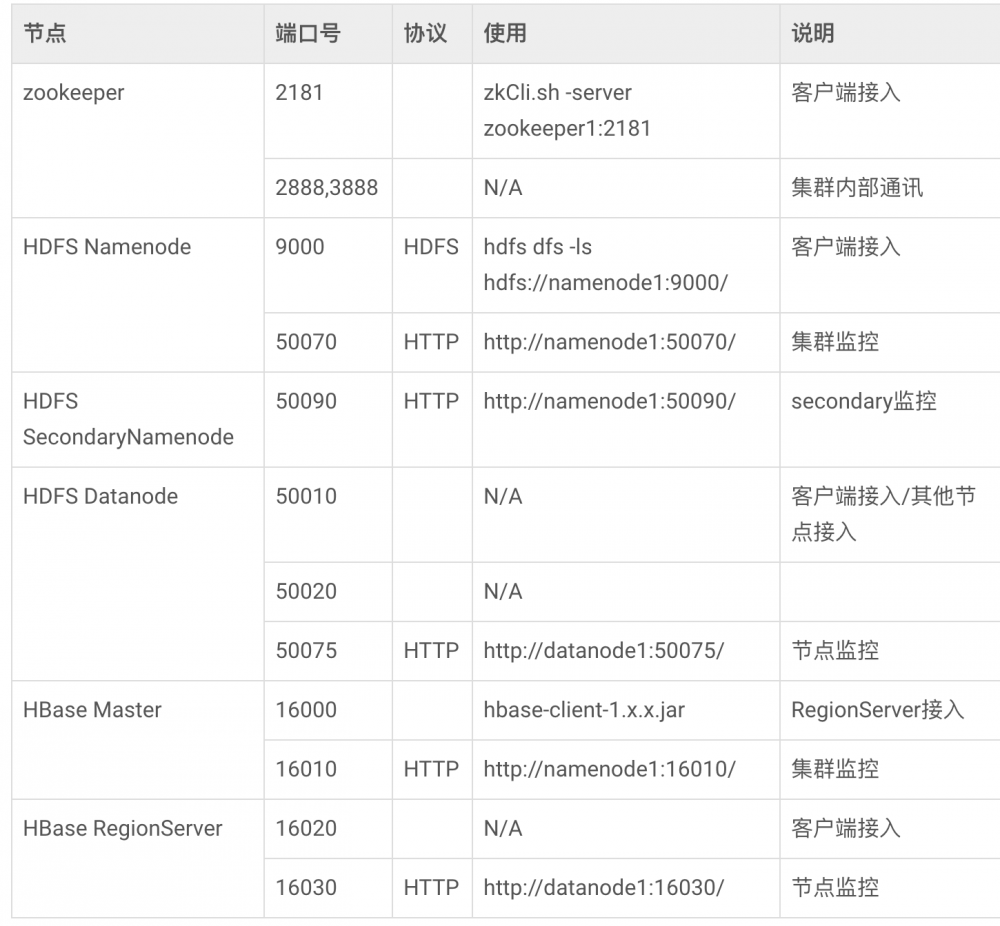
也许按照上面的配置完成,你发现客户端没法访问HBase。一般无法访问是因为客户端或者服务器配置出错,可以通过查看前端控制台日志和HBase/log下的日志可以发现错误原因。有一个在调试过程中发现客户端和后台都没有报错,就是调用hbaseTemplate操作hbase时不继续往下执行,找了半天才找到问题。因为我使用的是案例云ECS,安全组默认是不允许22以外的端口访问,默认情况下前端需要访问HBase的2181和16020端口,需要把这两个端口放开。如果服务端单独配置了防火墙,也需要放开这两个端口。以下是HBase涉及到的端口表格,大家可以根据具体情况放开相关端口。
八、其他
以上哪里写的不对或者有待改进,欢迎大家提意见,谢谢!
转载请注明出处: http://www.luoxudong.com/?p=505
正文到此结束
- 本文标签: 删除 ORM 目录 分布式 root pom tar 集群 zookeeper Region Google value dist http bean 云 Spring Boot web maven js 网站 HBase HBase Shell API key client Service mysql id apache node https cat 安全 配置 管理 XML build 公网IP Property linux 服务端 ssh 端口 struct 产品 apr 安装 IDE DOM final ECS Logging Master java 微服务 Hadoop ip 数据库 Datanode map 数据 HTML 开发 主机 下载 文件系统 spring Mysql数据库 测试 shell Oracle Namenode sql 调试 App 阿里云 core 数据模型 IO rmi bigdata 服务器 servlet description HDFS HMaster UI CTO REST src ACE cache Ubuntu 模型 安装配置 nfs Slaves HRegionServer 系统架构 代码 软件 lib
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

