Class 文件格式详解
Write once, run everywhere! ,我们都知道这是 Java 著名的宣传口号。不同的操作系统,不同的 CPU 具有不同的指令集,如何做到平台无关性,依靠的就是 Java 虚拟机。计算机永远只能识别 0 和 1 组成的二进制文件,虚拟机就是我们编写的代码和计算机之间的桥梁。虚拟机将我们编写的 .java 源程序文件编译为 字节码 格式的 .class 文件,字节码是各种虚拟机与所有平台统一使用的程序存储格式,这是平台无关性的本质,虚拟机在操作系统的应用层实现了平台无关。实际上不仅仅是平台无关,JVM 也是 语言无关 的。常见的 JVM 语言,如 Scala , Groovy ,再到最近的 Android 官方开发语言 Kotlin ,经过各自的语言编译器最终都会编译为 .class 文件。适当的了解 Class 文件格式,对我们开发,逆向都是大有裨益的。
Class 文件结构
class 文件的结构很清晰,如下所示:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
复制代码
其中的 u2 u4 分别代表 2 和 4 字节的无符号数。另外需要注意的是 classs 文件的多字节数据是按照大端表示法(big-endian)进行存储的,在解析的时候需要注意。
了解一种文件结构最好的方法就是去解析它,包括之后的 AndroidManifest.xml 、 dex 等等,都会通过代码直接解析来学习它们的文件结构。下面就以最简单的 Hello.java 程序进行解析:
public class Hello {
private static String HELLO_WORLD = "Hello World!";
public static void main(String[] args) {
System.out.println(HELLO_WORLD);
}
}
复制代码
javac 命令编译生成 Hello.class 文件。这里推荐一个利器 010Editor ,查看分析各种二进制文件结构十分方便,相比 Winhex 或者 Ghex 更加智能。下面是通过 010Editor 打开 Hello.class 文件的截图:
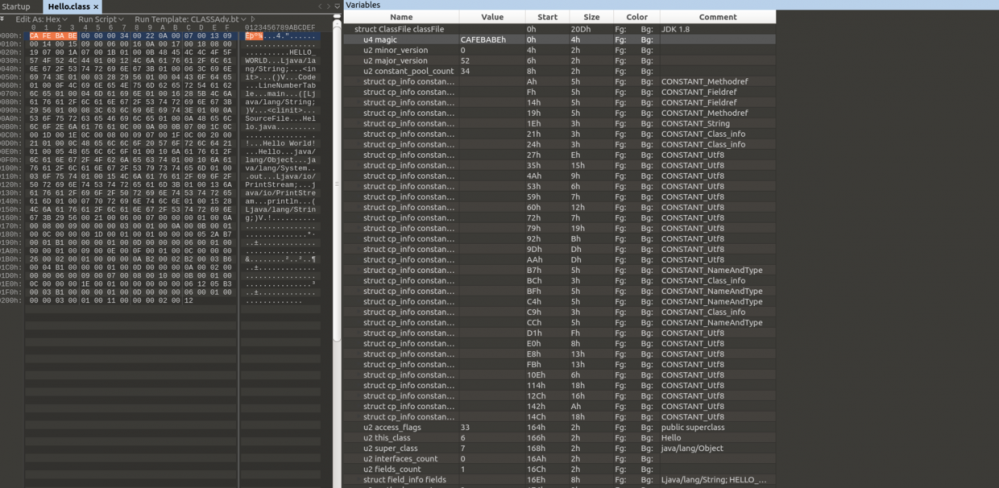
文件结构一目了然。点击各个结构也会自动标记处上半部分文件内容中对应的十六进制数据,相当方便。下面就对照着结构目录逐项解析。
magic

class 文件的魔数很有意思, 0xCAFEBABE ,也许 Java 创始人真的很热衷于咖啡吧,包括 Java 的图标也是一杯咖啡。
minor_version && major_version

minor_version 是次版本号, major_version 是主版本号。每个版本的 JDK 都有自己特定的版本号。高版本的 JDK 向下兼容低版本的 Class 文件,但低版本不能运行高版本的 Class 文件,即使文件格式没有发生任何变化,虚拟机也拒绝执行高于其版本号的 Class 文件。上面图中主版本号为 52,代表 JDK 1.8,在 JDK 1.8 以下的版本是无法执行的。
constant_pool
常量池是 Class 文件中的重中之重,存放着各种数据类型,与其他项目关联甚多。在解析的时候,我们可以把常量池看成一个数组或者集合,既然是数组或者集合,就要先确定它的长度。首先看一下 Hello.class 文件的常量池部分的截图:
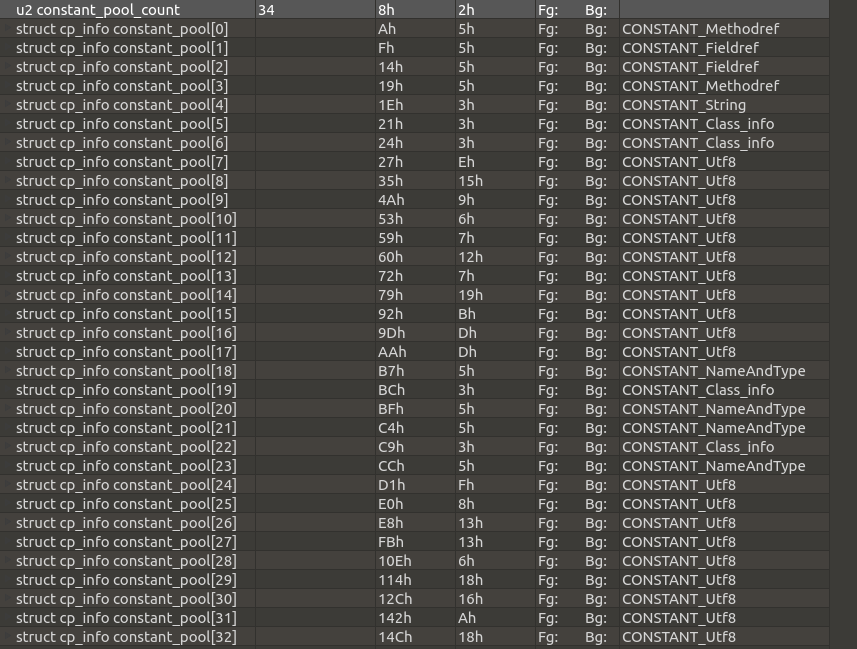
常量池部分以一个 u2 类型开头,代表常量池中的容量,上例中为 34 。需要注意的是,常量池的下标是从 1 开始的,也就代表该 Class 文件具有 33 个常量。那么,为什么下标要从 1 开始呢?目的是为了表示在特定情况下 不引用任何一个常量池项 ,这时候下标就用 0 表示。
下表是常量池的一些常见数据类型:
| 类 型 | 标 志 | 描 述 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | UTF-8 编码的字符串 |
| CONSTANT_Integer_info | 3 | 整型字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的部分符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MethodType_info | 16 | 标识方法类型 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
常量池的数据类型有十几种,各自都有自己的数据结构,但是他们都有一个共有属性 tag 。 tag 是标志位,标记是哪一种数据结构。我们在这里不针对每种数据结构进行分析,就按照 Hello.class 文件的常量池结构粗略分析一下。
首先看 Hello.class 文件常量池的第一项:

这是一个 CONSTANT_Methodref_info , 表示类中方法的一些信息,它的数据结构是 tag class_index name_and_type_index 。 tag 标识为 10。 class_index 的值是 7,这是一个常量池索引,指向常量池中的某一项数据。注意,常量池的索引是从 1 开始的,所以这里指向的其实是第 6 个数据项:

CONSTANT_Methodref_info 的 class_index 指向的数据项永远是 CONSTANT_Class_info , tag 标识为 7,代表的是类或者接口,它的 name_index 也是常量池索引,上图中可以看到是第 26 项:

这是一个 CONSTANT_Utf8_info ,从名称就可以看出来这是一个字符串, length 属性标识长度,后面的 byte[] 代表字符串内容。从 010Editor 解析内容可以看到这个字符串是 java/lang/Object ,表示类的全限定名。
接着回到常量池第一项 CONSTANT_Methodref_info ,刚才看了 name_index 属性,另一个属性是 name_and_type_index ,它永远指向 CONSTANT_NameAndType_info ,表示字段或者方法,它的值为 19,我们来看一下常量池的第 18 项:

CONSTANT_NameAndType_info 的 tag 标识为 12,具有两个属性, name_index 和 descriptor_index ,它们指向的均是 CONSTANT_Utf8_info 。 name_index 表示字段或者方法的非限定名,这里的值是 <init> 。 descriptor_index 表示字段描述符或者方法描述符,这里的值是 ()V 。
到这里,常量池的第一个数据项就分析完了,后面的每一个数据项都可以按照这样分析。到这里就可以看到常量池的重要性了,包含了 Class 文件的大部分信息。
接着继续分析常量池之后的文件结构,先总体浏览一下:
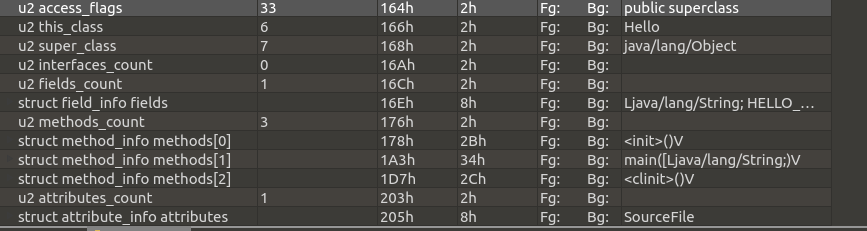
access_flags
访问表示,表示类或接口的访问权限和属性,下图为一些访问标志的取值和含义:
| 标志名称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBIC | 0x0001 | 是否为 public 类型 |
| ACC_FINAL | 0x0010 | 是否声明为 final |
| ACC_SUPER | 0x0020 | JDK1.0.2 之后编译出来的类这个标志都必须为真 |
| ACC_INTERFACE | 0x0200 | 是否为接口 |
| ACC_ABSTRACT | 0x0400 | 是否为 abstract 类型 |
| ACC_SYNTHETIC | 0x1000 | 标记这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 是否为注解 |
| ACC_ENUM | 0x4000 | 是否为枚举类型 |
Hello.class 文件的访问标记为十进制 33, Hello.java 就是一个普通的类,由 public 修饰,所以应该具有 ACC_PUBIC 和 ACC_SUPER 这两个标记, 0x0001 + 0x0010 正好为十进制 33。
this_class && super_class && interfaces_count && interfaces[]
为什么把这几项放在同一节进行解释?因为这几项数据共同确定了该类的继承关系。 this_class 代表类索引,用于确定该类的全限定名,图中可以看到索引值为 6 ,指向常量池中第 5 个数据项,这个数据项必须是 CONSTANT_Class_info ,查找常量池可以看到类名为 Hello ,代表当前类的名字。 super_class 表示父类索引, 同样也是指向 CONSTANT_Class_info ,值为 java/lang/Object 。我们都知道,Object 是 java 中唯一一个没有父类的类,因此它的父类索引为 0 。
super_class 之后紧接的两个字符是 interfaces_count ,表示的是该类实现的接口数量。由于 Hello.java 未实现任何接口,所以该值为 0。如果实现了若干接口,这些接口信息将存储在之后的 interfaces[] 之中。
fields_count && field_info
字段表集合,表示该类中声明的变量。 fields_count 指明变量的个数, fields[] 存储变量的信息。注意,这里的变量指的是成员变量,并不包括方法中的局部变量。再回忆一下 Hello.java 文件,仅有一个变量:
private static String HELLO_WORLD = "Hello World!"; 复制代码
上面这行变量声明告诉我们,有一个叫 HELLO_WORLD 的 String 类型变量,且是 private static 修饰的。所以 fields[] 所需存储的也正是这些信息。先来看下 filed_info 的结构:

access_flags 是访问标志,表示字段的访问权限和基本属性,和之前分析过的类的访问标志是很相似的。下表是一些常见的访问标志的名称和含义:
| 标志名称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBIC | 0x0001 | 是否为 public |
| ACC_PRIVATE | 0x0002 | 是否为 private |
| ACC_PROTECTED | 0x0004 | 是否为 protected |
| ACC_STATIC | 0x0008 | 是否为 static |
| ACC_FINAL | 0x0010 | 是否为 final |
| ACC_VOLATILE | 0x0040 | 是否为 volatile |
| ACC_TRANSIENT | 0x0080 | 是否为 transient |
| ACC_SYNTHETIC | 0x1000 | 是否由编译器自动生成 |
| ACC_ENUM | 0x4000 | 是否为 enum |
private static 即为 0x0002 + 0x0008 ,等于十进制的 10。
name_index 为常量池索引,表示字段的名称,查看常量池第 7 项,是一个 CONSTANT_Utf8_info ,值为 HELLO_WORLD 。
descriptor_index 也是常量池索引,表示字段的描述,查看常量池第 8 项,是一个 CONSTANT_Utf8_info ,值为 Ljava/lang/String; 。
这样便得到了这个字段的完整信息。在图中还可以看到, descriptor_index 后面还跟着 attributes_count ,这里的值为 0,否则后面还会跟着 attributes[] 。关于属性表后面还会专门分析到,这里先不做分析。
methods_count && method_info
紧接着字段表集合的是方法表集合,表示类中的方法。方法表集合和字段表集合的结构很相似,如下图所示:

access_flags 表示访问标志,其标志值和字段表略有不同,如下所示:
| 标志名称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBIC | 0x0001 | 是否为 public |
| ACC_PRIVATE | 0x0002 | 是否为 private |
| ACC_PROTECTED | 0x0004 | 是否为 protected |
| ACC_STATIC | 0x0008 | 是否为 static |
| ACC_FINAL | 0x0010 | 是否为 final |
| ACC_SYNCHRONIZED | 0x0020 | 是否为 sychronized |
| ACC_BRIDGE | 0x0040 | 是否由编译器产生的桥接方法 |
| ACC_VARARGS | 0x0080 | 是否接受不定参数 |
| ACC_NATIVE | 0x0100 | 是否为 native |
| ACC_ABSTRACT | 0x0400 | 是否为 abstract |
| ACC_STRICTFP | 0x0800 | 是否为 strictfp |
| ACC_SYNTHETIC | 0x1000 | 是否由编译器自动产生 |
name_index 和 descriptor_index 与字段表一样,分别表示方法的名称和方法的描述,指向常量池中的 CONSTANT_Utf8_info 项。方法中的具体代码存储在之后的属性表中,经编译器编译为字节码格式存储。属性表在下一节进行具体分析。
attributes_count && attribute_info
属性表在之前已经出现过好几次,包括字段表,方法表都包含了属性表。属性表的种类很多,可以表示源文件名称,编译生成的字节码指令,final 定义的常量值,方法抛出的异常等等。在 《Java虚拟机规范(Java SE 7)》中已经预定义了 21 项属性。这里仅对 Hello.class 文件中出现的属性进行分析。
首先来看下 Hello.class 文件中紧跟在方法表之后的最后两项。

attributes_count 声明后面的属性表长度,这里为 1,后面跟了一个属性。由上图该属性结构可知,这是一个定长的属性,但是大部分属性类型其实是不定长的。
attribute_name_index 是属性名称索引,指向常量池中的 CONSTANT_Utf8_info ,代表的是属性的类型,该属性为 17,所以指向常量池的第 16 项,查阅常量池,其值为 SourceFile ,表示这是一个 SourceFile 属性,其属性值为源文件的名称。
attribute_length 是属性的长度,但不包含 attribute_name_index 和其本身,所以整个属性的长度应该是 attribute_length + 6 。
sourcefile_index 是源文件名称索引,指向常量池中的 CONSTANT_Utf8_info ,索引值为 18,即指向第 17 项,不难猜测,该项表示的字符串就是源文件名称 Hello.java 。
这个属性比较简单,下面来看 main 方法表中的属性表,该属性表所代表的是 main 方法中的代码经过编译编译生成的字节码:

可以看到 main 方法的方法表中包含了一个属性,其结构还是比较复杂的,下面进行逐项分析。
attribute_name_index 指向常量池第 11 项,其字符串为 Code ,表示这是一个 Code 属性。 Code 属性是 Class 文件中最重要的属性,它存储的是 Java 代码编译生成的字节码。
attribute_length 为 38,表示后面 38 个字节都是该属性的内容。
max_stack 代表了操作数栈深度的最大值。在方法执行的任意时刻,操作数栈都不会超过这个深度。虚拟机运行的时候需要根据这个值来分配栈帧中的操作栈深度。
max_locals 代表了局部变量表所需的存储空间,以 slot 为单位。 Slot 是虚拟机为局部变量分配内存所使用的最小单位。
code_length 指的是编译生成的字节码的长度, 紧接着的 code 就是用来存储字节码的。上图中可以看到这里的字节码长度是 10 个字节,我们来看一下这 10 个字节:
B2 00 02 B2 00 03 B6 00 04 B1 复制代码
字节码指令是由操作码(Opcode)以及跟随其后的所需参数构成的。操作码是单字节,代表某种特定操作,参数个数可能为 0。关于字节码指令集的指令描述,在 《Java 虚拟机规范》 一书中有详细介绍。
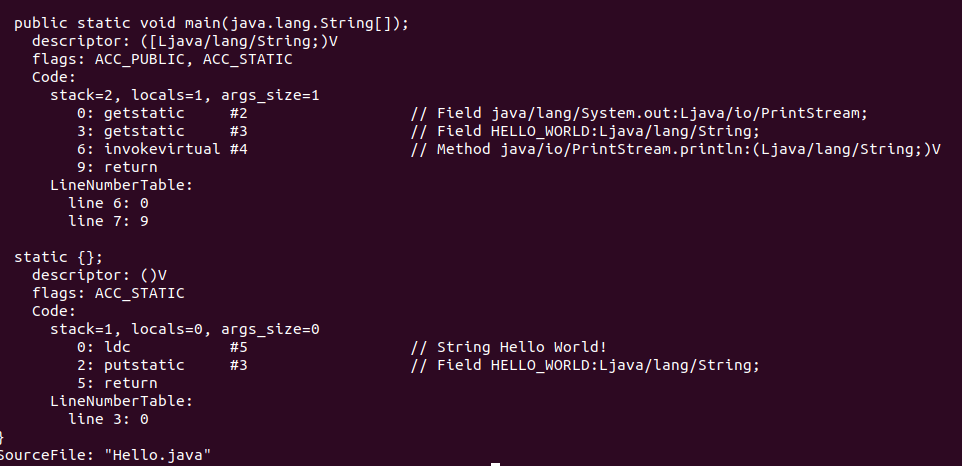
这里我们接着分析上述字节码。首个操作符为 0xb2 ,查表可得代表的操作是 getstatic ,获取类的静态字段。其后跟着两字节的索引值,指向常量池中的第 2 项数据,这是一个 CONSTANT_Fieldref_info ,表示的是一个字段的符号引用。按照上面的分析方式分析一下这个字段,它的类名是 java/lang/System ,名称是 out ,描述符是 Ljava/io/PrintStream; 。由此可知, 0xb20002 这段字节码的含义是获取类 System 中类型为 Ljava/io/PrintStream 的静态字段 out 。
接着看下一个操作符,仍旧是 0xb2 ,同上,分析可得这个字段是类 Hello 中类型为 Ljava/lang/String 的静态字段 HELLO_WORLD 。
第三个操作符是 0xb6 ,查表其代表的操作为 invokevirtual ,其含义是调用实例方法。后面紧跟两个字节,指向常量池中的 CONSTANT_Methodref_info 。查看常量池中的第 4 项数据,分析可得其类名为 java/io/PrintStream ,方法名为 println ,方法描述符为 (Ljava/lang/String;)V 。这三个字节的字节码执行的操作就是我们的打印语句了。
最后一个操作符是 0xb1 ,代表的操作为 return ,表示方法返回 void 。到这里,该方法就执行完毕了。
到这里, Hello.class 的文件结构就基本分析完了。我们再回顾一下 Class 文件的基本结构:
魔数 | 副版本号 | 主版本号 | 常量池数量 | 常量 | 访问标志 | 类索引 | 父类索引 | 接口数量 | 接口表 | 字段数量 | 字段表 | 方法数量 | 方法表 | 属性数量 | 属性表
各个项目严格按照顺序紧凑地排列在 Class 文件之中,中间没有任何分隔符。
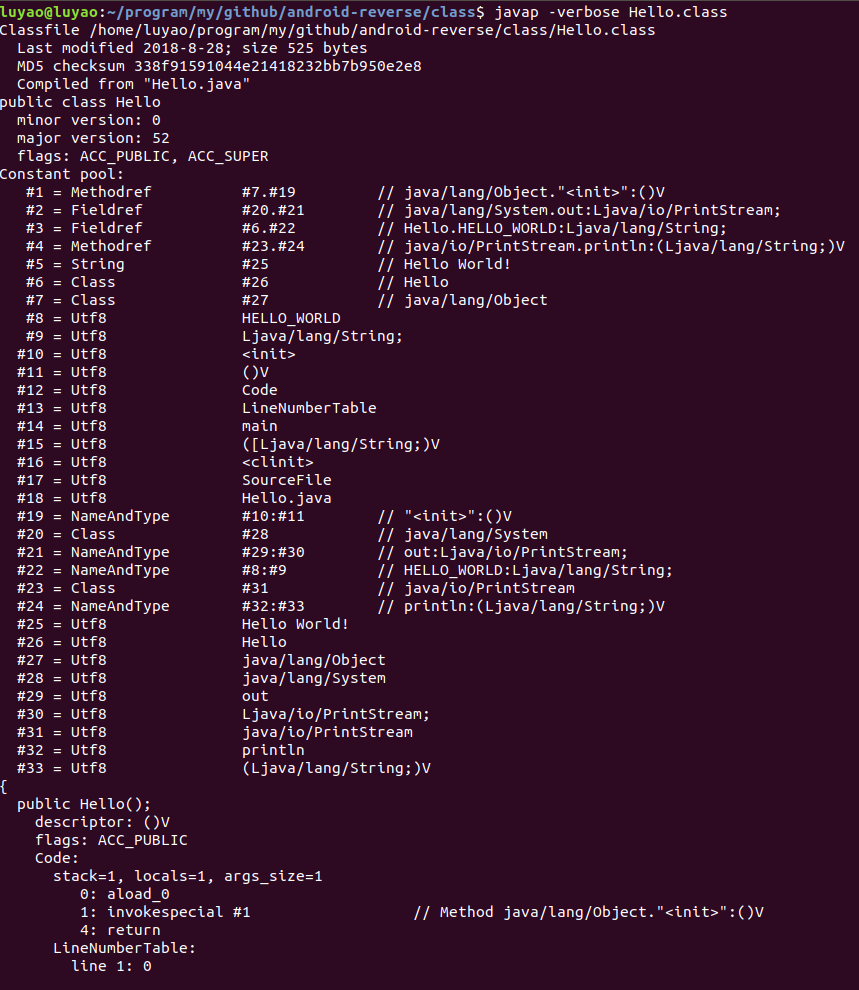
另外我们也可以通过 javap 命令快速查看 Class 文件内容:
javap -verbose Hello.class
结果如下图所示:
代码解析
Class 文件格式的代码解析相对比较简单,读到文件流逐项解析即可。
魔数和主副版本解析:
private void parseHeader() {
try {
String magic = reader.readHexString(4);
log("magic: %s", magic);
int minor_version = reader.readUnsignedShort();
log("minor_version: %d", minor_version);
int major_version = reader.readUnsignedShort();
log("major_version: %d", major_version);
} catch (IOException e) {
log("Parser header error:%s", e.getMessage());
}
}
复制代码
常量池解析:
private void parseConstantPool() {
try {
int constant_pool_count = reader.readUnsignedShort();
log("constant_pool_count: %d", constant_pool_count);
for (int i = 0; i < constant_pool_count - 1; i++) {
int tag = reader.readUnsignedByte();
switch (tag) {
case ConstantTag.METHOD_REF:
ConstantMethodref methodRef = new ConstantMethodref();
methodRef.read(reader);
log("%s", methodRef.toString());
break;
case ConstantTag.FIELD_REF:
ConstantFieldRef fieldRef = new ConstantFieldRef();
fieldRef.read(reader);
log("%s", fieldRef.toString());
break;
case ConstantTag.STRING:
ConstantString string = new ConstantString();
string.read(reader);
log("%s", string.toString());
break;
case ConstantTag.CLASS:
ConstantClass clazz = new ConstantClass();
clazz.read(reader);
log("%s", clazz.toString());
break;
case ConstantTag.UTF8:
ConstantUtf8 utf8 = new ConstantUtf8();
utf8.read(reader);
log("%s", utf8.toString());
break;
case ConstantTag.NAME_AND_TYPE:
ConstantNameAndType nameAndType = new ConstantNameAndType();
nameAndType.read(reader);
log("%s", nameAndType.toString());
break;
}
}
} catch (IOException e) {
log("Parser constant pool error:%s", e.getMessage());
}
}
复制代码
剩余信息解析:
private void parseOther() {
try {
int access_flags = reader.readUnsignedShort();
log("access_flags: %d", access_flags);
int this_class = reader.readUnsignedShort();
log("this_class: %d", this_class);
int super_class = reader.readUnsignedShort();
log("super_class: %d", super_class);
int interfaces_count = reader.readUnsignedShort();
log("interfaces_count: %d", interfaces_count);
// TODO parse interfaces[]
int fields_count = reader.readUnsignedShort();
log("fields_count: %d", fields_count);
List<Field> fieldList=new ArrayList<>();
for (int i = 0; i < fields_count; i++) {
Field field=new Field();
field.read(reader);
fieldList.add(field);
log(field.toString());
}
int method_count=reader.readUnsignedShort();
log("method_count: %d", method_count);
List<Method> methodList=new ArrayList<>();
for (int i=0;i<method_count;i++){
Method method=new Method();
method.read(reader);
methodList.add(method);
log(method.toString());
}
int attribute_count=reader.readUnsignedShort();
log("attribute_count: %d", attribute_count);
List<Attribute> attributeList = new ArrayList<>();
for (int i = 0; i < attribute_count; i++) {
Attribute attribute=new Attribute();
attribute.read(reader);
attributeList.add(attribute);
log(attribute.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码
由于属性种类众多,这里未对属性就行详细解析,仅为了加深对 Class 文件结构的了解,相当于一个低配版的 javap 。
Class 文件结构的基本了解就到这里,文中相关文件和 Class 文件解析工程源码都在这里, android-reverse 。
下一篇开始学习 smali 语言。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

