《深入理解 Java 虚拟机 》学习笔记
第二章 Java 内存区域与内存溢出异常
内存区域

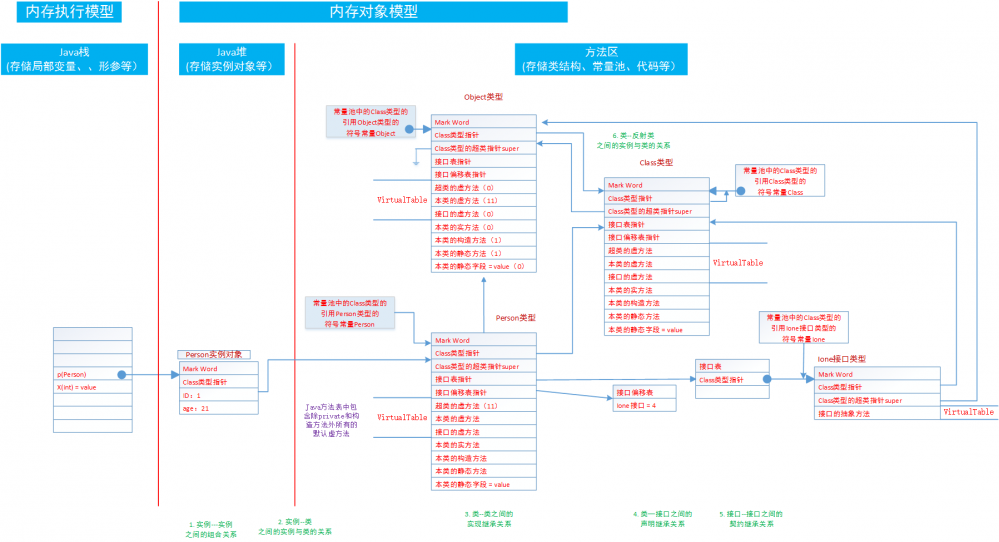
– from 姜志明
对象创建
- 加载类
- 若已经在内存中则跳过。
- 类加载完以后就可以确定对象所需的空间大小 // TODO why?
- 分配内存
- 根据 GC 回收算法的不同,分配方式略有区别。
- 标记整理算法,使用空闲列表
- 带压缩的算法,使用指针碰撞(已分配和未分配内存间由指针分隔)
- 根据 GC 回收算法的不同,分配方式略有区别。
- 内存清零
- 对象初始化
对象的内存布局

- MarkWord 占用一个 字 的大小,其中分为两部分:
- 对象自身运行时元数据。例如,哈希码、GC 分代年龄、锁状态标志等等
- 类型指针。指向其类的元数据。
- 若对象是数组则还需要保存数组的长度。
- 域的存储顺序:
- 基本类型优先,长度长的优先。
- 父类域优先。子类较短域可插入父类域空隙。
- 受虚拟机分配策略参数和域定义顺序的影响。
对象访问
两种方式:
- 直接引用
- 引用句柄(句柄池)
内存溢出异常
常用 JVM 参数 (Java HotSpot VM)
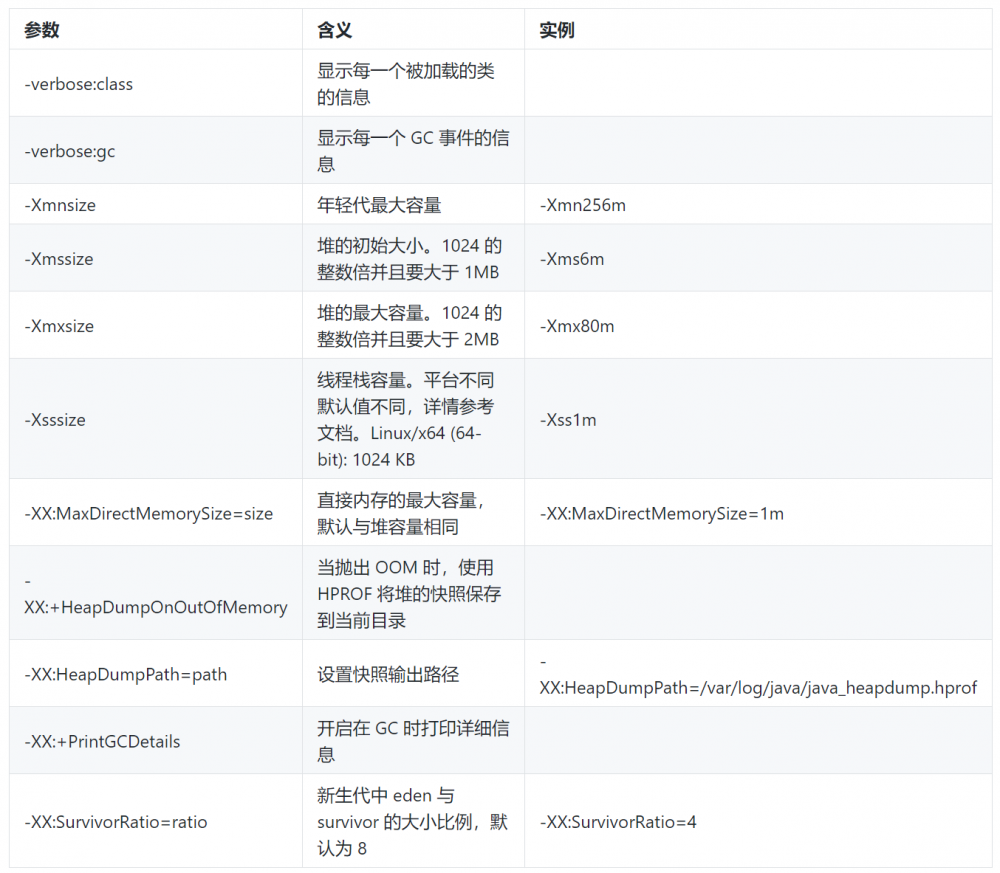
常见异常及可能原因
- 堆区
-
OutOfMemoryException。使用工具对快照进行分析,看是否发生了内存泄露(内存中有不再使用的但无法回收的对象或资源)。若是,则通过分析引用链找到根源,解决问题;若不是检查虚拟机堆参数,看是否能够调大。再检查代码中是否有生命周期很长的大对象。
-
- 虚拟机栈和本地方法栈
OutOfMemoryException StackOverflowException
- 方法区和运行时常量池
- 直接内存溢出
- 不正确的使用 NIO。
String 与字符串常量
public class StringTest {
public static void main(String[] args) {
String m = "hello";
String n = "hello";
String u = new String(m);
String v = new String("hello");
System.out.println("m == n: " + (m == n));
System.out.println("m == u: " + (m == u));
System.out.println("m == v: " + (m == v)
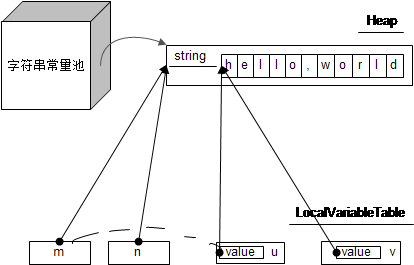
参考: 初探Java字符串
第三章 垃圾收集器与内存分配策略
判断对象是否存活
- 引用计数器算法。给对象添加一个引用计数器,增加/删除引用时对计数器进行修订。但是该方法因为无法解决循环引用(例如两个对象互相引用)的问题,所以一般不使用该方法
- 可达性分析算法。从
GC root开始递归查询并标记,结束后未被标记的(不可达的)即为可回收的对象。GC root共有四种:- 栈中引用的对象
- 方法区常量引用的对象
- 方法区静态域引用的对象
- 本地方法中 JNI 引用的对象(不太懂)
- 回收方法区
- 新生代的回收效率可达到 70% – 95%,而永久代则低的多(性价比太低)
- 在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGi 这类频繁自定义 ClassLoader 的场景都需要虚拟机有卸载类的能力。
垃圾收集算法
- 标记-清除算法
- 扫描一遍,标记出需要回收的对象,再扫描将其清除
- 标记/清除两阶段时间效率都不高,且回收后空间较零碎。
- 复制算法
- 将内存分为两块,当一块中内存不足时,将其中所有存活对象复制到另一块中,回收当前一整块。
- 目前商用虚拟机大都使用这一算法回收新生代。将内存划分为一个较大的 Eden 区和两块较小的 Survivor. Eden:Survivor = 8:1
- 标记整理算法
- 标记出须清理的对象,然后其余对象移动到一端
- 分代收集算法
- 新生代使用复制算法
- 永久代使用其他两种算法
HotSpot 算法实现
- 当程序执行到安全点(safepoint)时进行 GC,通过在安全点(safepoint)生成的 OopMaps 快速遍历 GC root 进行回收。
- 安全点(safepoint):指令序列复用的位置。例如方法调用、循环结构、异常跳转等位置。
- OopMaps:一种特殊的数据结构,用于枚举 GC root
- 但是如果线程处于不执行的状态时,如 sleep 或 blocked 无法执行到安全点,即需要提前标记为安全区域(safe region)。GC 时不考虑处于安全区域的线程,若安全区域代码执行结束但 GC 未结束时该线程等待 GC 结束信号。
- 安全区域(safe region):引用不发生改变的代码片段
垃圾收集器
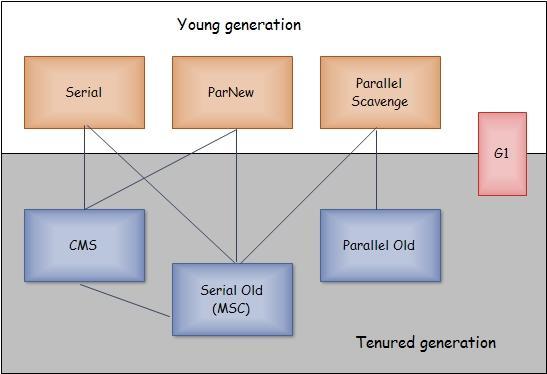
- 并发(concurrent) vs 并行(parallel)
- 并行是同时进行(多 CPU)
- 并发可交替
- Minor GC vs Major GC vs Full GC
- Minor GC:只回收新生代
- Major GC:只回收永久代
- Full GC: 回收整个堆。相当于 Minor GC + Major GC
- serial。单线程,简单高效。复制算法
- PerNew。serial 的多线程版本,并行。
- parallel Scavenge。 与 PerNew 类似,复制算法、多线程、并行。但侧重吞吐量,拥有自适应调节的能力。适合用在后台不需要太多用户交互的地方。
- 吞吐量 = 用户代码执行时间 / (用户代码执行时间 + 垃圾回收时间)
- 自适应调节:虚拟机根据但前系统的运行情况,自动调节虚拟机各参数以确保最大吞吐量。
- serial old。serial 的永久代版本。采用标记整理算法。
- parallel old。parallel Scavenge 的老年代版本,采用标记整理算法。与 parallel scavenge 搭配可以用在注重吞吐量及 CPU 资源敏感的地方。
- CMS(concurrent mark sweep)。并发低停顿,使用标记清理算法。非常优秀的一款收集器,但还是有几个缺点:
- 对 CPU 资源敏感,当其小于数量小于 4 个是可能会对用户程序有较大影响。默认启动回收线程数 = (CPU 数 + 3)/ 4
- 无法处理浮动垃圾。浮动垃圾:在垃圾回收期间生成的垃圾
- 回收后会留有大量的空间碎片。
- G1 //TODO
内存分配与回收策略
TLAB(Thread local allocate buffer)线程私有分配缓冲区,每个线程一个
-XX:MaxTenuringThreshold
第六章 类文件结构
- 类文件的结构拥有固定的格式,包含两部分的数据:
- 类的元数据。
- 方法代码的字节流
-
code属性表包含的属性max_stack max_locals
- 符号引用
- 类与接口的全限定名
- 域的名称与描述符
- 方法名与描述符
- 该部分内容可以通过查表获得,不再赘述。
第七章 虚拟机类加载机制
类加载的过程
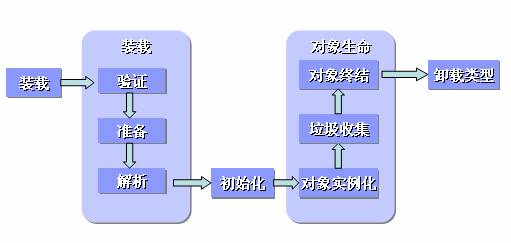
1. 加载
通过全类名获取该类的二进制字节流
解析字节流,将字节流所表达的静态存储结构转化为方法区的运行时数据结构 (这是什么东西?)
为该类创建一个 Class 对象,用来访问该类的类数据
2. 连接
- 验证
为了确保加载的字节流时符合规范的,不会危害到虚拟机自身的安全。主要包括
- 文件格式验证
- 元数据验证
- 字节码验证
- 符号引用验证
- 准备
为类变量分配内存并进行初步初始化(0/null) // 不应该是在类加载阶段完成的么?
- 解析
将符号引用替换为直接引用
3. 初始化
- static fields and block init
4. 使用
5. 卸载
类加载器
一个加载器确定一个类的命名空间。同一个类由不同加载器加载后是不同的类。
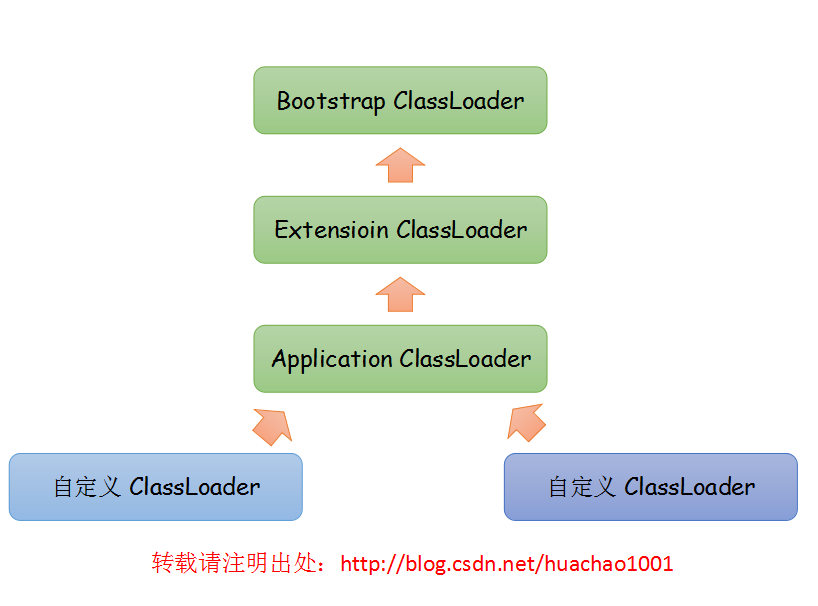
双亲委派:当需要加载一个类时先使用父类加载器(其实这个地方不是很准确,父子关系是通过复合来实现的),若失败了,再使用当前的加载器。如果自己写一个 Object 类,编译可通过但是由于双亲委派,它永远都不会被加载。
第十章 早期(编译器)优化
// TODO: 因本章含有相当多的 编译原理 相关概念,所以第十、十一章学习延后(预计第 8-9 周)
前端编译过程( *.java --> *.class )
解析与填充符号表
词法分析。将源代码转换为标记(Token) 的集合
- Token: 是编译过程中的最小元素。例如关键字、变量名、运算符等等
语法分析。通过 Token 序列将构造抽象语法树(Abstract syntax tree)
参考
- 郑州大学姜志明老师课件
- 初探Java字符串 (非常好的一篇文章)
- Java HotSpot VM 参数
- Java HotSpot Virtual Machine Garbage Collection Tuning Guide
- JVM 垃圾回收器工作原理及使用实例介绍 — IBM
- Minor GC vs Major GC vs Full GC
- Abstract syntax tree
- 4.4 Symbol Tables
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

