对象并不一定都是在堆上分配内存的
在《深入理解 Java 虚拟机》中有这样一段话:
“随着 JIT 编译器的发展和逃逸分析技术的逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象分配到堆上也渐渐不那么绝对了”。
逃逸分析
- 这是由于在编译期间,JIT 会对代码做很多优化,其中有一部分优化的目的就是减少内存堆分配的压力,其中一项重要的技术叫做逃逸分析。
- 逃逸分析基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能会被外部方法调用,例如作为调用参数传递到其他方法中,称为方法逃逸。
- 甚至还有可能被外部线程访问到,譬如复制给类变量或者在其他线程中访问的实例变量。成为线程逃逸。
- 通过逃逸分析,HotSpot 编译器能够分析出一个新的对象的引用的使用范围,从而决定是否要将这个对象分配到堆上。
如果能证明一个对象不会逃逸到方法或线程之外,也就是别的方法或线程无法通过任何途径访问到这个对象,则可能为这个变量进行一些高效优化,如下所示:
栈上分配(Stack Alloction)
- JVM中,在Java堆上分配创建对象的内存空间。Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问堆中存储的对象数据。
- JVM中垃圾收系统可以回收堆中不再使用的对象,但回收动作无论是筛选可回收对象,还是回收和整理内存都需要好费时间。
- 如果确定一个对象不会逃逸出方法之外,那让这个对象在栈上分配内存将会是一个不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,不会逃逸的局部变量所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集系统的压力将会小很多。
同步消除(Synchronization Elimination)
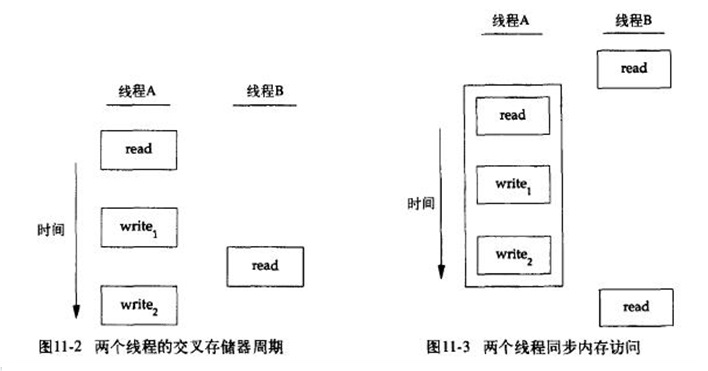
图11-2描述了两个线程读写相同变量的假设例子。 在这个例子中,线程 A 读取变量然后给这个变量赋予一个新的值,但写操作需要两个存储器周期。 当线程 B 在这两个存储器写周期中间读取这个相同的变量时,它就会得到不一致的值。 为了解决这个问题,线程不得不使用锁,在同一时间只允许一个线程访问该变量。 图 11-3 描述了这种同步。 如果线程 B 希望读取变量,它首先要获取锁; 同样地,当线程 A 更新变量时,也需要获取这把同样的锁。 因而线程 B 在线程 A 释放锁以前不能读取变量。 复制代码
- 线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以消除掉。
标量替换(Scalar Replacement)
- 标量(Scalar)是一个数据已经无法再分解成更小的数据来表示了,JVM中的原始数据类型(int、long等数值类型以及reference类型等)都不能进一步分解,他们就可以成为标量。
- 相对的,如果一个数据可以继续分解,那它就称为聚合量(Aggregation),Java中的对象就是最典型的聚合量。
- 如果把一个Java对象拆解,根据程序访问的情况,将其使用到的成员变量恢复原始类型来访问就叫做标量替换。
- 如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆解的话,那程序真正执行的时候将可能不在创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。
- 将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,有很大的概率会被JVM分配至物理机的告诉寄存器中存储)分配合读写之外,还可以为后续进一步优化手段创建条件。
并不成熟
关于逃逸分析的论文在 1999 年就已经发表了,但直到 JDK 1.6 才有实现,而且这项技术到如今也并不是十分成熟的。
其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。
一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了。
虽然这项技术并不十分成熟,但是他也是即时编译器优化技术中一个十分重要的手段。
参考来源:
周志明 《深入理解Java虚拟机》
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

