java基础学习:JavaWeb之request和response
浏览器向服务器请求某个web资源时,称之为浏览器向服务器发送了一个http请求。一个完整http请求应该包含三个部分:
- 请求行 【描述客户端的请求方式、请求的资源名称,以及使用的HTTP协议版本号】
- 多个消息头 【描述客户端请求哪台主机,以及客户端的一些环境信息等】
- 一个空行
请求行
请求行:GET /java.html HTTP/1.1 请求行中的GET称之为请求方式,
请求方式有:POST,GET,HEAD,OPTIONS,DELETE,TRACE,PUT。
常用的有:POST,GET
一般来说,当我们点击超链接,通过地址栏访问都是get请求方式。通过表单提交的数据一般是post方式。
可以简单理解GET方式用来查询数据,POST方式用来提交数据,get的提交速度比post快
GET方式:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
POST方式:可以在请求的实体内容中向服务器发送数据,传送的数据量无限制。
请求头
- Accept: text/html,image/* 【浏览器告诉服务器,它支持的数据类型】
- Accept-Charset: ISO-8859-1 【浏览器告诉服务器,它支持哪种 字符集 】
- Accept-Encoding: gzip,compress 【浏览器告诉服务器,它支持的 压缩格式 】
- Accept-Language: en-us,zh-cn 【浏览器告诉服务器,它的语言环境】
- Host:www.it315.org:80【浏览器告诉服务器,它的想访问哪台主机】
- If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,缓存数据的时间】
- Referer: www.it315.org/index.jsp 【浏览器告诉服务器,客户机是从那个页面来的--- 反盗链 】
- 8.User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)【浏览器告诉服务器,浏览器的内核是什么】
- Cookie【浏览器告诉服务器, 带来的Cookie是什么 】
- Connection: close/Keep-Alive 【浏览器告诉服务器,请求完后是断开链接还是保持链接】
- Date: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,请求的时间】
HTTP响应
一个HTTP响应代表着 服务器向浏览器回送数据 ,一个完整的HTTP响应应该包含四个部分:
- 一个状态行【用于描述 服务器对请求的处理结果。 】
- 多个消息头【用于描述 服务器的基本信息 ,以及 数据的描述 , 服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据 】
- 一个空行
- 实体内容【 服务器向客户端回送的数据 】
状态行
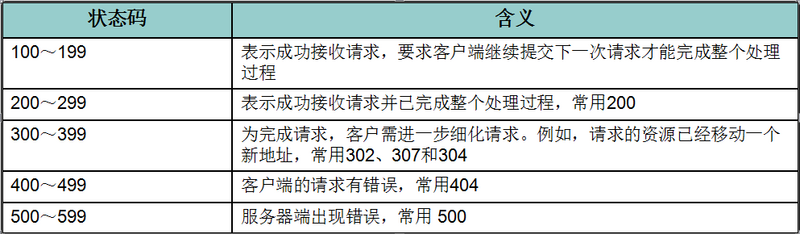
格式: HTTP版本号 状态码 原因叙述 状态行:HTTP/1.1 200 OK 状态码用于表示 服务器对请求的处理结果 ,它是一个 三位的十进制数 。响应状态码分为5类
响应头
- Location: www.it315.org/index.jsp 【服务器告诉浏览器 要跳转到哪个页面 】
- Server:apache tomcat【服务器告诉浏览器,服务器的型号是什么】
- Content-Encoding: gzip 【服务器告诉浏览器 数据压缩的格式 】
- Content-Length: 80 【服务器告诉浏览器回送数据的长度】
- Content-Language: zh-cn 【服务器告诉浏览器,服务器的语言环境】
- Content-Type: text/html; charset=GB2312 【服务器告诉浏览器, 回送数据的类型 】
- Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器该资源上次更新时间】
- Refresh: 1;url=www.it315.org【服务器告诉浏览器要 定时刷新 】
- Content-Disposition: attachment; filename=aaa.zip【服务器告诉浏览器 以下载方式打开数据 】
- Transfer-Encoding: chunked 【服务器告诉浏览器数据以分块方式回送】
- Set-Cookie:SS=Q0=5Lb_nQ; path=/search【服务器告诉浏览器要 保存Cookie 】
- Expires: -1【服务器告诉浏览器 不要设置缓存 】
- Cache-Control: no-cache 【服务器告诉浏览器 不要设置缓存 】
- Pragma: no-cache 【服务器告诉浏览器 不要设置缓存 】
- Connection: close/Keep-Alive 【服务器告诉浏览器连接方式】
- Date: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器回送数据的时间】
HttpServletRequest
概述
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的方法,可以获得客户这些信息。 request就是将请求文本封装而成的对象,所以通过request能获得请求文本中的所有内容,请求头、请求体、请求行

常用方法
1. 请求头
我们可以查看任意一个网页,它都是有请求头的。
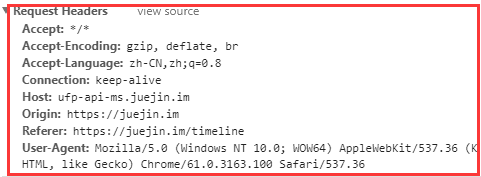
相关方法:
String getHeader(String name)根据头名称得到头信息值
long getDateHeader(java.lang.String name)获得指定头内容Date
int getIntHeader(java.lang.String name)获得指定头内容int
Enumeration getHeaderNames()得到所有头信息name
Enumeration getHeaders(String name)根据头名称得到相同名称头信息值
Enumeration<String> headerNames = req.getHeaderNames();
while(headerNames.hasMoreElements()){
String key = (String)headerNames.nextElement();
String value = req.getHeader(key);
System.out.println(key+"="+value);
}
复制代码
2. 请求体
1)与表单获取相关的方法:
String getParameter(name):根据表单中name属性的名,获取value属性的值方法
String[] getParameterValues(String name):专为复选框取取提供的方法
getParameterNames():得到表单提交的所有name的方法
Map<String , String[]> getParameterMap(): 得到表单提交的所有值的方法 //做框架用,非常实用
getInputStream: 以字节流的方式得到所有表单数据
2)与操作非表单数据相关的方法(request也是一个域对象):
void setAttribute(String name, Object value);
Object getAttribute(String name);
Void removeAttribute(String name);
3)与请求转发相关的方法:
RequestDispatcher getRequestDispatcher(String path)//得到请求转发或请求包含的协助对象
forward(ServletRequest request, ServletResponse response)//转发的方法
include(ServletRequest request, ServletResponse response)//请求包含
4)与编码相关的方法:
//解决post方式编码
request.setCharacterEncoding("UTF-8"):告诉服务器客户端什么编码,只能处理post请求方式
//解决get方式编码
String name = new String(name.getBytes(“iso-8859-1”),”UTF-8”);
#####3. 其他常用请求方法
getMethod();
getRequestURL();
getRequestURI();
getServerName();
getServerPort();
getContextPath();
getServletPath();
getQueryString();
getRemoteAddr();
getProtocol();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1.统一资源标记符 /Web_Servlet/ServletTest3
String uri = req.getRequestURI();
System.out.println(uri);
//2.统一资源定位符 http://localhost:6060/Web_Servlet/ServletTest3
StringBuffer url = req.getRequestURL();
System.out.println(url);
//3.协议和版本 HTTP/1.1
String potocol = req.getProtocol();
System.out.println(potocol);
//4.协议 http
String scheme = req.getScheme();
System.out.println(scheme);
//5.主机(域名) localhost,如果你使用的是ip地址,就显示ip地址
String serverName = req.getServerName();
System.out.println(serverName);
//6.端口 6060(这是我自己修改了的端口,默认是8080)
int port = req. getServerPort();
System.out.println(port);
//7.发布到tomcat下的项目名称 /Web_Servlet
String contextPath = req.getContextPath();
System.out.println(contextPath);
//8.servlet路径 /ServletTest3
String servletPath = req.getServletPath();
System.out.println(servletPath);
//9.获取所有请求参数,即?之后所有东西。 username=faker&password=mid
String queryString = req.getQueryString();
System.out.println(queryString);
//10.远程主机的ip地址 0:0:0:0:0:0:0:1
String remoteAddr = req.getRemoteAddr();
System.out.println(remoteAddr);
}
复制代码
HttpServletResponse
概述
Web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象、和代表响应的response对象。request和response对象即然代表请求和响应,那我们要获取客户机提交过来的数据,只需要找request对象就行了。要向容器输出数据,只需要找response对象就行了。
HttpServletResponse对象代表服务器的响应。这个对象中封装了向客户端发送数据、发送响应头,发送响应状态码的方法。

常用方法
响应行/响应头/响应体
setStatus(int sc)设置响应状态码
setHeader(String name, String value)设置响应头信息
getWrite();字符输出流
getOutputStream();字节输出流
setCharacterEncoding(String charset)告知服务器使用什么编码
setContentType(String type)告诉响应的内容类型(text/html,application/json等)
重定向
response.sendRedirect(path);
注意:重定向没有任何局限,可以重定向web项目内的任何路径,也可以访问别的web项目中的路径,并且这里就用"/"区分开来,如果path使用了"/"开头,就说明我要重新开始定位了,不访问刚才的web项目,自己写项目名,如果path没有使用"/"开始,那么就知道是访问刚才那个web项目下的servlet,就可以省略项目名了。就是这样来区别。
两者的细节
两种setCharacterEncoding
-
request.setCharacterEncoding()指定后可以通过getParameter()则直接获得正确的字符串,如果不指定,则默认使用iso8859-1编码。值得注意的是在执行setCharacterEncoding()之前,不能执行任何getParameter()。而且,该指定只对POST方法有效,对GET方法无效。
分析原因,应该是在执行第一个getParameter()的时候,Java将会按照编码分析所有的提交内容,而后续的getParameter()不再进行分析,所以setCharacterEncoding()无效。而对于GET方法提交表单是,提交的内容在URL中,一开始就已经按照编码分析提交内容,setCharacterEncoding()自然就无效。
-
response.setCharacterEncoding设置HTTP 响应的编码,如果之前使用response.setContentType设置了编码格式,则使用response.setCharacterEncoding指定的编码格式覆盖之前的设置.与response.setContentType相同的是,调用此方法,必须在getWriter执行之前或者response被提交之前
学习资料: www.cnblogs.com/fan-xiaofan…
转发与重定向
实际发生位置不同,地址栏不同
转发是发生在服务器的:
转发是由服务器进行跳转的,细心的朋友会发现,在转发的时候,浏览器的地址栏是没有发生变化的,在我访问Servlet111的时候,即使跳转到了Servlet222的页面,浏览器的地址还是Servlet111的。也就是说浏览器是不知道该跳转的动作,转发是对浏览器透明的。通过上面的转发时序图我们也可以发现,实现转发只是一次的http请求,一次转发中request和response对象都是同一个。这也解释了,为什么可以使用request作为域对象进行Servlet之间的通讯。
重定向是发生在浏览器的:
重定向是由浏览器进行跳转的,进行重定向跳转的时候,浏览器的地址会发生变化的。曾经介绍过:实现重定向的原理是由response的状态码和Location头组合而实现的。这是由浏览器进行的页面跳转实现重定向会发出两个http请求,request域对象是无效的,因为它不是同一个request对象
用法不同
很多人都搞不清楚转发和重定向的时候,资源地址究竟怎么写。有的时候要把应用名写上,有的时候不用把应用名写上。很容易把人搞晕。记住一个原则:给服务器用的直接从资源名开始写,给浏览器用的要把应用名写上
request.getRequestDispatcher("/资源名 URI").forward(request,response)
转发时"/"代表的是本应用程序的根目录
response.send("/web应用/资源名 URI");
重定向时"/"代表的是webapps目录
能够去往的URL的范围不一样
转发是服务器跳转只能去往当前web应用的资源
重定向是服务器跳转,可以去往任何的资源
传递数据的类型不同
转发的request对象可以传递各种类型的数据,包括对象
重定向只能传递字符串
跳转的时间不同
转发时:执行到跳转语句时就会立刻跳转
重定向:整个页面执行完之后才执行跳转
Servlet中乱码解决与转发和重定向的区别
getWriter和getOutputStream
1.选择getOutputStream 和getWriter方法的要点
PrintWriter对象输出字符文本内容时,它内部还是将字符串转换成了某种字符集编码的字节数组后再进行输出,使用PrintWriter对象的好处就是不用编程人员自己来完成字符串到字节数组的转换。
使用ServletOutputStream对象也能输出内容全为文本字符的网页文档,但是,如果网页文档内容是在Servlet程序内部使用文本字符串动态拼凑和创建出来的,则需要先将字符文本转换成字节数组后输出。
2.两种方法区别
getOutputStream方法用于返回Servlet引擎创建的字节输出流对象,Servlet程序可以按字节形式输出响应正文。
getWriter方法用于返回Servlet引擎创建的字符输出流对象,Servlet程序可以按字符形式输出响应正文。
getOutputStream和getWriter这两个方法互相排斥,调用了其中的任何一个方法后,就不能再调用另一方法。
getOutputStream方法返回的字节输出流对象的类型为ServletOutputStream,它可以直接输出字节数组中的二进制数据。
getWriter方法将Servlet引擎的数据缓冲区包装成PrintWriter类型的字符输出流对象后返回,PrintWriter对象可以直接输出字符文本内容。
Servlet程序向ServletOutputStream或PrintWriter对象中写入的数据将被Servlet引擎获取,Servlet引擎将这些数据当作响应消息的正文,然后再与响应状态行和各响应头组合后输出到客户端。
Serlvet的service方法结束后,Servlet引擎将检查getWriter或getOutputStream方法返回的输出流对象是否已经调用过close方法,如果没有,Servlet引擎将调用close方法关闭该输出流对象。
3.修改编码类型
getOutputStream解决办法:
- 通过更改浏览器的编码方式:IE/”查看”/”编码”/”UTF-8”(不可取)
- 通过设置响应头告知客户端编码方式: response.setHeader(“Content-type”, “text/html;charset=UTF-8”); //告知浏览器数据类型及编码
- 通过meta标签模拟请求头:out.write("".getBytes());
- 通过以下方法: response.setContentType("text/html;charset=UTF-8");
rgetWriter解决办法:
response. setContentType(“text/html;charset=UTF-8”);
两者的应用
1. 文件下载
//通过路径得到一个输入流
String path = this.getServletContext().getRealPath(filepath);
FileInputStream fis = new FileInputStream(path);
//创建字节输出流
ServletOutputStream sos = response.getOutputStream();
//得到要下载的文件名
String filename = path.substring(path.lastIndexOf("//")+1);
//设置文件名的编码
filename = URLEncoder.encode(filename, "UTF-8");//将不安全的文件名改为UTF-8格式
//告知客户端要下载文件
response.setHeader("content-disposition", "attachment;filename="+filename);
response.setHeader("content-type", "image/jpeg");
//执行输出操作
int len = 1;
byte[] b = new byte[1024];
while((len=fis.read(b))!=-1){
sos.write(b,0,len);
}
sos.close();
fis.close();
复制代码
2. 验证码
3. 定时刷新
response.setContentType("text/html;charset=UTF-8");
response.getWriter().write("3秒后跳转页面.....");
//三秒后跳转到index.jsp页面去
response.setHeader("Refresh", "3;url='/index.jsp'");
复制代码
4. 设置缓存
//浏览器有三消息头设置缓存,为了兼容性!将三个消息头都设置了
response.setDateHeader("Expires", -1);
response.setHeader("Cache-Control","no-cache");
response.setHeader("Pragma", "no-cache");
复制代码
5. 数据压缩
//创建GZIPOutputStream对象,给予它ByteArrayOutputStream
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
GZIPOutputStream gzipOutputStream = new GZIPOutputStream(byteArrayOutputStream);
//GZIP对数据压缩,GZIP写入的数据是保存在byteArrayOutputStream上的
gzipOutputStream.write("asdfzxcvasdfzxvasdfzxcv".getBytes());
//gzipOutputStream有缓冲,把缓冲清了,并顺便关闭流
gzipOutputStream.close();
byte[] bytes = byteArrayOutputStream.toByteArray();
//告诉浏览器这是gzip压缩的数据
response.setHeader("Content-Encoding","gzip");
//将压缩的数据写给浏览器
response.getOutputStream().write(bytes);
复制代码
6. 防盗链
//获取到网页是从哪里来的
String referer = request.getHeader("Referer");
复制代码
正文到此结束
- 本文标签: stream map json 服务器 主机 id js 代码 目录 开发 remote 下载 Agent 安全 HTML web src https HTTP协议 IDE 参数 端口 ACE 缓存 cat App apache Connection ip IO 数据 value windows Word Keep-Alive Ipo 域名 zip Webapps tomcat cache GMT UI key 协议 http 乱码 时间 java java基础 servlet Service
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

