Spring系列之DI的原理及手动实现
在上一章中,我们介绍和简单实现了容器的部分功能,但是这里还留下了很多的问题。比如我们在构造bean实例的时候如果bean是带参数的我们需要怎么来进行,当然这个是可以在init方法中进行的,再比如我们平时在Spring中获取一个对象通过一个注解即可获取到类的实例,这个实例是怎么注入的呢?
IOC和DI
依赖注入(DI)和控制反转(IOC)其实基本上表达的是同一个东西,两者谁也离不开谁。
假设类a需要依赖类b,但a并不控制b的声明周期,仅仅在本类中使用b,而对于类b的创建和销毁等工作交给其他的组件来处理,这叫控制反转(IOC),而类a要依赖类b,则必须要获得类b的实例。这个获得类b的实例的过程则就是依赖注入(DI)。
注入分析
分析我们在那些地方可能会有注入这样一个行为?
要知道那些地方存在依赖注入首先得明白注入的是什么,结合上面分析这里很明显注入实际就是一个实例化的过程,更广泛的说是一个赋值的过程。而我们平时那些地方可能会存在赋值的动作呢?首先肯定是构造函数里,对类的实例化构造函数肯定是跑不了的,大多数赋初值的操作也都在构造函数中完成。然后还有就是另外执行过程中对属性值修改了。
那么需要进行依赖注入的地方就很明显了:
- 构造参数依赖
- 属性依赖
我们赋值的类型有那些呢?
很明显在Java中我们赋值类型包括基本数据类型(int,double...)和引用类型。
在分析清楚需要注入的行为和类型后又有另外的问题,我们虽然知道注入的类型是基本数据类型和引用类型,但是实际需要注入的类型是无法预料到的,我们事先并不知道某一个参数需要的是int还是boolean或者是引用类型。幸运的是Java实际上已经帮我们解决了这件事情,java中的所有类型都是继承自Object,我们只需要使用Object来接受值即可。
我们在对值进行注入的时候肯定是需要知道我们注入的具体的类型的,instanceof关键字可以帮助我们确定具体的某个类型,但是实际上也就仅仅限于基本数据类型了,因为引用类型实在太多了,用户自己定义的引用类型我们是没有办法事先确定的。所以我们要想办法能让我们知道注入的具体是哪一个类型。
BeanReference
我们定义一个用来标识bean类型的类,接口只包含一个标识bean的类型的参数beanName,在注入参数的时候只需要定义好beanName的值即可直接从IOC容器中取相应的bean,而对于基本数据类型和String则直接赋值即可。

当然这样还不能解决所有问题,因为传入的参数可能携带多个引用值,比如引用数组,List,Map以及属性文件读取(Properties)等,解决这些问题和上面差不多,引用类型还是使用BeanReference,多个值则进行遍历即可。
构造参数依赖分析
构造参数个数的问题
实际上上面的分析已经将我们的问题解决的差不多了,还存在一个问题就是构造参数的个数是没有办法确定的,我们怎么来存储一个bean实例化所需的全部参数,又如何值和参数对应。
很明显需要一个对应关系的话我们立刻能想到的就是key-value形式的Map,实际上我们还能使用List,根据顺序来存储,取得时候也依然是这个顺序。
如何匹配构造函数
一个类中方法的重载的个数可以是有多个的,我们如何精确的找到我们需要的方法呢?
在JDK中Class类中为我们提供了一系列的方法:
| method | 介绍 |
|---|---|
| Constructor getConstructor(Class<?>... parameterTypes) | 返回一个 Constructor对象,该对象反映 Constructor对象表示的类的指定的公共 类函数。 |
| Method getMethod(String name, Class<?>... parameterTypes) | 返回一个 方法对象,它反映此表示的类或接口的指定公共成员方法 类对象。 |
| Method[] getMethods() | 返回包含一个数组 方法对象反射由此表示的类或接口的所有公共方法 类对象,包括那些由类或接口和那些从超类和超接口继承的声明。 |
| Constructor<?>[] getConstructors() | 返回包含一个数组 Constructor对象反射由此表示的类的所有公共构造 类对象。 |
前面我们已经取到了参数:
- 根据参数个数匹配具有同样个数参数的方法
- 根据参数类型精确匹配步骤一种筛选出的方法
单例or原型
简单来讲,单例(Singleton)是指在容器运行过程中,一个bean只创建一次,后面需要使用都是同一个对象。原型(Prototype)在容器运行时不进行创建,只有在使用时才创建,没用一次就新创建一个。
对于单例模式只创建一次,那么上面的匹配过程也只会进行一次,对程序的运行不会有影响。但是原型模式每次创建都重新匹配一次这会在一定程度上拖慢程序的运行。所以这里我们可以考虑将原型bean实例化对应的方法缓存起来,那么后面在同一个地方使用创建时不用重复去匹配。
需要的接口
很明显上面的分析都是和bean定义有关,相应的方法也应该加在bean定义接口上了。
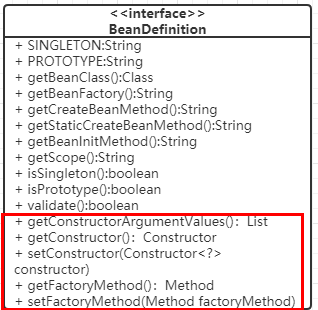
构造参数的注入应当是在bean创建的时候,在前面我们定义类几种不同的bean创建方式,现在应该在这些方法中加上构造参数了。
代码:
BeanReference
public class BeanReference {
private String beanName;
public String getBeanName() {
return beanName;
}
public void setBeanName(String beanName) {
this.beanName = beanName;
}
}
复制代码
DefaultBeanDefinition添加代码:
public class DefaultBeanDefinition implements BeanDefinition{
...
private Constructor constructor;
private Method method;
private List<?> constructorArg;
...
//getter setter
}
复制代码
DefaultBeanFactory添加代码
public class DefaultBeanFactory implements BeanFactory, BeanDefinitionRegistry, Closeable {
//other method
/**
* 解析传入的构造参数值
* @param constructorArgs
* @return
*/
private Object[] parseConstructorArgs(List constructorArgs) throws IllegalAccessException, InstantiationException {
if(constructorArgs==null || constructorArgs.size()==0){
return null;
}
Object[] args = new Object[constructorArgs.size()];
for(int i=0;i<constructorArgs.size();i++){
Object arg = constructorArgs.get(i);
Object value = null;
if(arg instanceof BeanReference){
String beanName = ((BeanReference) arg).getBeanName();
value = this.doGetBean(beanName);
}else if(arg instanceof List){
value = parseListArg((List) arg);
}else if(arg instanceof Map){
//todo 处理map
}else if(arg instanceof Properties){
//todo 处理属性文件
}else {
value = arg;
}
args[i] = value;
}
return args;
}
private Constructor<?> matchConstructor(BeanDefinition bd, Object[] args) throws Exception {
if(args == null){
return bd.getBeanClass().getConstructor(null);
}
//如果已经缓存了 则直接返回
if(bd.getConstructor() != null)
return bd.getConstructor();
int len = args.length;
Class[] param = new Class[len];
//构造参数列表
for(int i=0;i<len;i++){
param[i] = args[i].getClass();
}
//先进行精确匹配 如果能匹配到相应的构造方法 则后续不用进行
Constructor constructor = null;
try {
constructor = bd.getBeanClass().getConstructor(param);
} catch (Exception e) {
//这里上面的代码如果没匹配到会抛出空指针异常
//为了代码继续执行 这里我们来捕获 但是不需要做其他任何操作
}
if(constructor != null){
return constructor;
}
//未匹配到 继续匹配
List<Constructor> firstFilterAfter = new LinkedList<>();
Constructor[] constructors = bd.getBeanClass().getConstructors();
//按参数个数匹配
for(Constructor cons:constructors){
if(cons.getParameterCount() == len){
firstFilterAfter.add(cons);
}
}
if(firstFilterAfter.size()==1){
return firstFilterAfter.get(0);
}
if(firstFilterAfter.size()==0){
log.error("不存在对应的构造函数:" + args);
throw new Exception("不存在对应的构造函数:" + args);
}
//按参数类型匹配
//获取所有参数类型
boolean isMatch = true;
for(int i=0;i<firstFilterAfter.size();i++){
Class[] types = firstFilterAfter.get(i).getParameterTypes();
for(int j=0;j<types.length;j++){
if(types[j].isAssignableFrom(args[j].getClass())){
isMatch = false;
break;
}
}
if(isMatch){
//对于原型bean 缓存方法
if(bd.isPrototype()){
bd.setConstructor(firstFilterAfter.get(i));
}
return firstFilterAfter.get(i);
}
}
//未能匹配到
throw new Exception("不存在对应的构造函数:" + args);
}
private List parseListArg(List arg) throws Exception {
//遍历list
List param = new LinkedList();
for(Object value:arg){
Object res = new Object();
if(arg instanceof BeanReference){
String beanName = ((BeanReference) value).getBeanName();
res = this.doGetBean(beanName);
}else if(arg instanceof List){
//递归 因为list中可能还存有list
res = parseListArg(arg);
}else if(arg instanceof Map){
//todo 处理map
}else if(arg instanceof Properties){
//todo 处理属性文件
}else {
res = arg;
}
param.add(res);
}
return param;
}
}
复制代码
相关代码已经托管到github: myspring
循环依赖
到这里对构造函数的参数依赖基本完成了,经过测试也基本没有问题,但是在测试过程中发现如果构造出的参数存在循环依赖的话,则会导致整个过程失败。
什么是循环依赖?如何解决循环依赖?
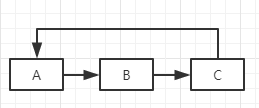
如上图,A依赖B,B依赖C,C又依赖A,在初始化的过程中,A需要加载B,B需要加载C,到了C这一步又来加载A,一直重复上面的过程,这就叫循环依赖。
在Spring框架中对Bean进行配置的时候有一个属性 lazy-init 。一旦将这个属性设置为true,那么循环依赖的问题就不存在了,这是为什么呢?实际上如果配置了懒加载那么这个bean并不会立刻初始化,而是等到使用时才初始化,而在需要使用时其他的bean都已经初始化好了,这是我们直接取实例,依赖的实例并不需要实例化,所以才不会有循环依赖的问题。
那么我们这里怎么解决呢?
根据Spring的启发,需要解决循环依赖那么主要就是对于已经实例化过的bean不在进行实例化,那么我们定义一个用于记录已经实例化后的bean的容器,每一次实例化一个bean是检测一次,如果已经实例化过的bean直接跳过。
添加的代码:
public class DefaultBeanFactory implements BeanFactory, BeanDefinitionRegistry, Closeable {
//记录正在创建的bean
private ThreadLocal<Set<String>> initialedBeans = new ThreadLocal<>();
public Object doGetBean(String beanName) throws InstantiationException, IllegalAccessException {
//other operation
// 记录正在创建的Bean
Set<String> beans = this.initialedBeans.get();
if (beans == null) {
beans = new HashSet<>();
this.initialedBeans.set(beans);
}
// 检测循环依赖
if (beans.contains(beanName)) {
throw new Exception("检测到" + beanName + "存在循环依赖:" + beans);
}
// 记录正在创建的Bean
beans.add(beanName);
//other operation
//创建完成 移除该bean的记录
beans.remove(beanName);
return instance;
}
}
复制代码
实际上在单例bean中,对于已经创建好的bean是直接从容器中获取实例,不需要再次实例化,所以也不会有循环依赖的问题。但是对于原型bean,创建好的实例并不放到容器中,而是每一次都重新创建初始化,才会存在循环依赖的问题。
属性依赖
除了在构造函数中初始化参数外,我们还可以对属性进行赋值,对属性赋值的好处在于可以在运行中动态的改变属性的值。
和构造参数依赖有什么不同
整体来说没有什么差别,不同在于对构造参数依赖时有具体的对应方法,可以根据参数的个数和顺序来确定构造方法,所以在注入是我们可以使用上面选择的List根据存入顺序作为参数的顺序。而对于属性依赖,我们必须要根据属性的名称来注入值才可以,所以在使用list就不行了。
解决:
- 使用一个Map容器,key为属性名,value为属性值,使用时解析map即可
- 自定义一个包裹属性的类,参数为属性名和属性值,然后使用list容纳包裹属性的类,实际上和上面的map差不多。
这里我使用map类。
然后其他的地方都基本一样,对于引用类型依旧使用 BeanReference 。在 BeanDefinition 中添加获取和设置属性值得方法:
//属性依赖
Map<String,Object> getPropertyKeyValue();
void setPropertyKeyValue(Map<String,Object> properties);
复制代码
在BeanFactory的实现中加入解析属性的方法:
private void parsePropertyValues(BeanDefinition bd, Object instance) throws Exception {
Map<String, Object> propertyKeyValue = bd.getPropertyKeyValue();
if(propertyKeyValue==null || propertyKeyValue.size()==0){
return ;
}
Class<?> aClass = instance.getClass();
Set<Map.Entry<String, Object>> entries = propertyKeyValue.entrySet();
for(Map.Entry<String, Object> entry:entries){
//获取指定的字段信息
Field field = aClass.getDeclaredField(entry.getKey());
//将访问权限设置为true
field.setAccessible(true);
Object arg = entry.getValue();
Object value = null;
if(arg instanceof BeanReference){
String beanName = ((BeanReference) arg).getBeanName();
value = this.doGetBean(beanName);
}else if(arg instanceof List){
List param = parseListArg((List) arg);
value = param;
}else if(arg instanceof Map){
//todo 处理map
}else if(arg instanceof Properties){
//todo 处理属性文件
}else {
value = arg;
}
field.set(instance, value);
}
}
复制代码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

