《两周自制脚本语言》——第五天(设计语法分析器)
写在前面
本章会用到一个Parser类,该类已经写好,直接先导入即可,在Code/Stone文件夹里面
Stone语言的语法
首先,我们借助BNF来试写一下Stone语言的语法规则。具体内容请参见代码清单5.1。规则中出现的NUMBER、IDENTIFIER、STRING、OP与EOL都是终结符,分别表示整型字面量、标识符、字符串字面量、双目运算符与换行符类型
下面我们来看一下代码清单5.1中各条规则的含义。首先,非终结符primary(基本构成元素)用于表示括号括起的表达式、整型字面量、标识符(即变量名)或字符串字面量。这些是最基本的表达式构成元素
非终结符factor(因子)表示一个primary,或primary之前再添加一个 - 号的组合
expr(表达式)用于表示两个factor之间夹有一个双目运算符的组合
block(代码块)指的是由 { 括起来的statement(语句)序列
statement之间需要用分号或换行符(EOL)分隔。由于Stone 语言支持空语句,因此规则中的statement两侧写有中括号[]。可以看到,它的结构大致与expr类似。它们都由其他的非终结符(statement或factor)与一些用于分隔的符号组合而成
statement可以是if语句、while语句或仅仅是简单表达式语句(simp1e)。简单表达式语句是仅由表达式(expr)构成的语句。
最后的program是一个非终结符,它可以包含分号或换行符,用于表示一句完整的语句。其中,statement可以省略,因此program还能用来表示空行。代码块中最后一句能够省略句尾分号与换行符,为此,代码清单5.1的规则中分别设计了statement与program两种类型。program既可以是处于代码块之外的一条语句,也可以是一行完整的程序
代码清单5.1 Stone语言的语法定义
primary -> "(" expr ")" | NUMBER | IDENTIFIER | STRING
factor -> "-" primary | primary
expr -> factor { OP factor }
block -> "{" [ statement ] { (";" | EOL) [ statement ]} "}"
simple -> expr
statement -> "if" expr block [ "else" block ] | "while" expr block | simple
program -> [ statement ] (";" | EOL)
使用解析器与组合子
我们打算用一种名为Parser的简单库来设计语法分析器,它是一种解析器组合子类型的库。本章将介绍如何通过该库来设计Stone语言的语法分析器。库的内部结构及源代码则会在第17章解说
parser库的工作仅是将BNF写成的语法规则改写为Java语言程序。代码清单5.2是由代码清单5.1中列出的Stone 语言语法转换而成的语法分析程序。parser类与operators类都是由库提供的类。rule方法是parser类中的一个static方法
BasicParser类首先定义了大量Parser类型的字段,它们是将代码清单5.1中列出的BNF语法规则转换为Java语言后得到的结果。例如,primary字段的定义基于非终结符primary的语法规则。factor与block同理,都是相应的Java语言形式的语法规则
据此定义的parser对象能够根据各种类型的非终结符模式来执行语法分析。例如,将词法分析器作为参数,调用program字段的parse方法,就能从词法分析器获取一行程序中包含的单词,并对其做语法分析,返回一棵抽象语法树。请注意一下Basicparser类的parse方法,这是一个public方法,仅用于调用program字段的parse方法
代码清单5.2 Stone语言的语法分析器
package Stone;
import static Stone.Parser.rule;
import java.util.HashSet;
import Stone.Parser.Operators;
import Stone.ast.*;
/**
* A basic Parser for Stone grammatical analysis
*/
public class BasicParser {
HashSet<String> reserved = new HashSet<>();
Operators operators = new Operators();
Parser expr0 = rule();
Parser primary = rule(PrimaryExpr.class).or(rule().sep("(").ast(expr0).sep(")"), rule().number(NumberLiteral.class),
rule().identifier(Name.class, reserved), rule().string(StringLiteral.class));
Parser factor = rule().or(rule(NegativeExpr.class).sep("-").ast(primary), primary);
Parser expr = expr0.expression(BinaryExpr.class, factor, operators);
Parser statement0 = rule();
Parser block = rule(BlockStmnt.class).sep("{").option(statement0)
.repeat(rule().sep(";", Token.EOL).option(statement0)).sep("}");
Parser simple = rule(PrimaryExpr.class).ast(expr);
Parser forPrefix = rule().sep("(").ast(expr).sep(";").ast(expr).sep(";").ast(expr).sep(")");
Parser statement = statement0.or(
rule(IfStmnt.class).sep("if").ast(expr).ast(block).option(rule().sep("else").ast(block)),
rule(WhileStmnt.class).sep("while").ast(expr).ast(block), simple);
Parser program = rule().or(statement, rule(NullStmnt.class)).sep(";", Token.EOL);
public BasicParser() {
reserved.add(";");
reserved.add("}");
reserved.add(Token.EOL);
operators.add("=", 1, Operators.RIGHT);
operators.add("==", 2, Operators.LEFT);
operators.add(">", 2, Operators.LEFT);
operators.add("<", 2, Operators.LEFT);
operators.add("+", 3, Operators.LEFT);
operators.add("-", 3, Operators.LEFT);
operators.add("*", 4, Operators.LEFT);
operators.add("/", 4, Operators.LEFT);
operators.add("%", 4, Operators.LEFT);
}
public ASTree parse(Lexer lexer) throws ParseException {
return program.parse(lexer);
}
}
Parser类的方法
| function | mean |
|---|---|
| rule() | 创建Parser对象 |
| rule(Class c) | 创建parser对象 |
| parser(Lexer l) | 执行语法分析 |
| number() | 向语法规则中添加终结符(整型字面量) |
| number(Class c) | 向语法规则中添加终结符(整型字面量) |
| identifier(HashSet<String> r) | 向语法规则中添加终结符(除保留字r外的标识符) |
| identifier(Class c,HashSet<String> r) | 向语法规则中添加终结符(除保留字r外的标识符) |
| string() | 向语法规则中添加终结符(字符串字面量) |
| string(class c) | 向语法规则中添加终结符(字符串字面量) |
| token(String... pat) | 向语法规则中添加终结符(与pat匹配的标识符) |
| sep(String... pat) | 向语法规则中添加包含于抽象语法树的终结符(与pat匹配的标识符) |
| ast(parser p) | 向语法规则中添加非终结符p |
| option(Parser p) | 向语法规则中添加可省略的非终结符p |
| maybe(Parser... p) | 向语法规则中添加可省略的非终结符p(如果省略,则作为一棵仅有根节点的抽象语法树处理) |
| or(Parser p) | 向语法规则中添加若干个由or关系连接的非终结符p |
| repeat(Parser p) | 向语法规则中添加至少重复出现0次的非终结符p |
| expression(Parser p,Operators op) | 向语法规则中添加双目运算表达式(p是因子,op是运算符表) |
| expression(Class c,Parser p,Operators op) | 向语法规则中添加双目运算表达式(p是因子,op是运算符表) |
| reset() | 清空语法规则 |
| reset(Class c) | 清空语法规则,将节点类赋值为c |
| insertChoice(Parser p) | 为语法规则起始处的or添加新的分支选项 |
上表列出了Parser类的方法。接下来,我们来看一下如何具体通过这些方法将BNF形式的语法规则转换为Java语言
首先,假设要处理这样一条语法规则
paren -> "(" expr ")"
非终结符paren表示的是由括号括起的表达式。这条规则的右半部分是从代码清单5.1的非终结符primary的模式中抽取的
将它转换为Java语言后将得到下面的代码
Parser paren = rule().sep("(").ast(expr).sep(")");
paren的值是一个parser对象,它表示非终结符paren的模式(即语法规则的右半部分)。rule方法是用于创建 Parser对象的factory方法。由它创建的Parser对象的模式为空,需要依出现顺序向模式中添加终结符或非终结符。根据语法规则,非终结符paren的模式包含左括号、非终结符expr以及右括号。这些模式需要依次添加至新创建的模式之中
左右括号不仅是终结符,也是分隔字符(seperator),因此需要通过sep方法添加。非终结符则由ast方法添加,其参数是一个与需要添加的非终结符对应的parser对象
这样一来,parser对象就能够表示某一特定的语法规则模式。该对象不仅能完整表示语法规则右半部的模式,也能表示模式的一部分。or方法与repeat方法能够表示BNF中由 |(或) 与 {} 构成的循环,而parser对象能够接收用于表示这些分支选项或循环部分的模式的参数
再比如,factor的语法规则如下所示
factor -> "-" primary | primary
在代码清单5.2中,与该规则对应的factor字段的定义如下,为方便阅读,此处省略rule的参数
Parser factor = rule().or(rule().spe("-").ast(primary),primary);
这里的代码调用通过rule方法创建的Parser对象的or方法,并添加了两种分支模式。对该模式来说,factor对应的parser对象只要与两者中的一种匹配即可
or方法的两个参数接收的都是parser对象,作为将被添加的分支选项。第2个参数接收的Parser对象用于表示非终结符primary的模式,第1个参数则将接收如下所示的Parser对象
rule().sep("-").ast(primary)
这样一来,Parser对象就能仅表示语法规则右侧所写模式的一部分
在代码清单5.2中,Basicparser类首先通过rule方法创建了一个parser对象,且没有调用其他任何方法,直接将该对象赋值给expro字段
Parser expr0 = rule()
这里预先创建的parser对象expro将会被赋值给expr。语言处理器可以通过该对象依次创建与primary及factor对应的Parser对象,最后再使用factor将正确的模式添加至expr0,完成一系列的处理。最终获得的对象(实际上即为expro)将被赋值给expr。在代码清单5.2中,statement字段也做了相同的处理
parser类的expression方法能够简单地创建expr形式的双目运算表达式语法。该方法的参数是因子的语法规则以及运算符表。因子(factor)指的是用于表示(优先级最高的)运算符左右两侧成分的非终结符。参数将被传递至与这一因子的语法规则对应的Parser对象
运算符表以Operators对象的形式保存,它是expression方法的第3个参数。运算符能通过add方法逐一添加。例如,语言处理器可以在代码清单5.2中Basicparser的构造函数内通过下面的方式添加新的运算符
operators.add("=",1,Operators.RIGHT)
add方法的参数分别是用于表示运算符的字符串、它的优先级以及左右结合顺序。用于表示优先级的数字是一个从1开始的int类型数值,该值越大,优先级越高
左结合指的是两个相同运算符接连出现时,左侧的那个优先级较高,例如, + 号是一种左结合的运算符,在计算
1 + 2 + 3
时,将会像下面这样首先计算左侧的加法运算
((1 + 2) + 3)
如果是右结合,就会先计算右侧的运算,例如 = 号
x = y = 3
等同于
(x = (y = 3))
由语法分析树生成的抽象语法树
Parser库将在找到与语法规则中的模式匹配的单词序列后用它们来创建抽象语法树。如果没有指定抽象语法树的根节点,则会默认使用一个ASTList对象。用于表示单词匹配的对象将构成语法树的叶节点。如果没有特别说明,叶节点都是ASTLeaf对象
下图是3+4经过语法分析后生成的抽象语法树
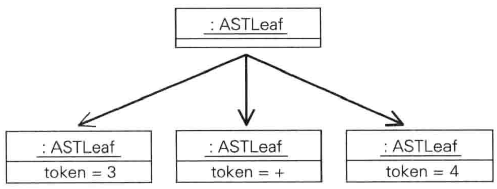
假设有下面的语法规则
adder -> NUMBER "+" NUMBER
将他改写为java语言后,得到
Parser adder = rule().number.token("+").number();
Parser库查找到与该模式匹配的单词序列后将创建如上图所示的抽象语法树的子树。其中,叶节点是用于表示与该模式匹配的单词(即终结符)的ASTLeaf对象,它们的直接父节点是一个ASTList对象,构成了这棵子树的根节点。其他的类也能作为该子树根节点与叶节点的对象类型。如果rule方法的参数为java.1ang.Class对象,抽象语法树的根节点就是一个该类的对象。此外,number与identifier等方法除了能够向模式添加终结符,还可以接收java.lang.Class对象作为参数,生成这种类型的叶节点对象
Parser adder = rule(BinaryExpr.class).number(NumberLiteral.class).token("+").number(NumberLiteral.class);
用以上方式改写代码,叶节点将改为NumberLiteral对象,根节点则将是一个BinaryExpr对象
上例中,+号由token方法添加。如果希望向模式添加分隔符,就需要使用sep方法。通过sep方法添加的符号不会被包含在生成的抽象语法树中。例如:
parser adder = rule().number().sep("+").number();
生成的抽象语法树与上图语法树的区别在于,它不含中间的ASTLeaf对象。为保持抽象语法树结构简洁,程序执行过程中无需使用的终结符应尽可能去除
如果语法规则的模式中含有非终结符,与该非终结符匹配的单词序列将暂时原样保留在子树中。来看一个例子,下面的模式使用了上面提到的adder
Parser eq = rule().ast(adder).token("==").ast(adder);
ast方法用于向模式添加非终结符。它的参数是一个parser对象。上面的例子中传递给ast方法的参数是adder,与ast方法接收的parser对象所表示的模式相匹配的部分都会首先作为一棵子树呈现,该子树能够表示 Parser对象中的结构关系。这棵子树的根节点将成为某些由上一层模式生成的节点的直接子节点。如下图所示,根据adder生成的子树的根节点是根据eq生成的抽象语法树的根节点(最上层的ASTList对象)的一个子节点

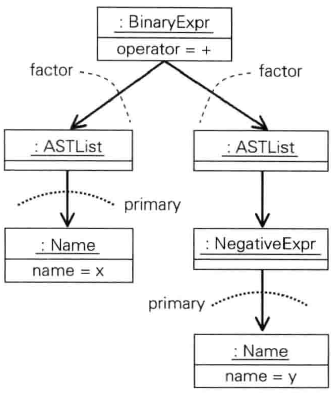
以上是Parser库构造抽象语法树的基本规则,不过由这种规则生成语法树通常会很大,包含很多无用的信息。例如
Parser factor = rule().or(rule(NegativeExpr.class). sep("-").ast(primary),primary);
根据已经介绍的基本规则,表达式x+-y经过语法分析后将得到下图的抽象语法树。图中的ASTList对象不含任何信息,显然没有存在的必要
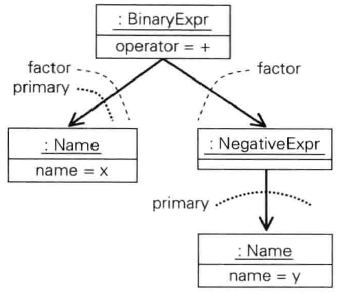
接下来,我们添加一条特殊的规定,即,如果子节点只有一个,parser库将不会另外创建一个额外的节点。本应是子节点的子树将直接作为与该模式对应的抽象语法树使用。以x + -y为例,生成的抽象语法树如下图所示。根据这条规定,parser库不会创建无用的AsTList对象。以Name对象及NegativeExpr对象为根节点的子树将直接成为与factor对应的抽象语法树
代码清单5.3 PrimaryExpr.java
package Stone.ast;
import java.util.List;
public class PrimaryExpr extends ASTList {
public PrimaryExpr(List<ASTree> c) {
super(c);
}
public static ASTree create(List<ASTree> c) {
return c.size() == 1 ? c.get(0) : new PrimaryExpr(c);
}
}
代码清单5.4 NegativeExpr.java
package Stone.ast;
import java.util.List;
public class NegativeExpr extends ASTList {
public NegativeExpr(List<ASTree> t) {
super(t);
}
public ASTree operand() {
return child(0);
}
public String toString() {
return "-" + operand();
}
}
代码清单5.5 BlockStmnt.java
package Stone.ast;
import java.util.List;
public class BlockStmnt extends ASTList {
public BlockStmnt(List<ASTree> t) {
super(t);
}
}
代码清单5.6 IfStmnt.java
package Stone.ast;
import java.util.List;
public class IfStmnt extends ASTList {
public IfStmnt(List<ASTree> t) {
super(t);
}
public ASTree condition() {
return child(0);
}
public ASTree thenBlock() {
return child(1);
}
public ASTree elseBlock() {
return numChildren() > 2 ? child(2) : null;
}
public String toString() {
return "(if " + condition() + " " + thenBlock() + " else " + elseBlock() + ")";
}
}
代码清单5.7 WhileStmnt.java
package Stone.ast;
import java.util.List;
public class WhileStmnt extends ASTList {
public WhileStmnt(List<ASTree> t) {
super(t);
}
public ASTree condition() {
return child(0);
}
public ASTree body() {
return child(1);
}
public String toString() {
return "(while " + condition() + " " + body() + ")";
}
}
代码清单5.8 NullStmnt.java
package Stone.ast;
import java.util.List;
public class NullStmnt extends ASTList {
public NullStmnt(List<ASTree> t) {
super(t);
}
}
代码清单5.9 StringLiteral.java
package Stone.ast;
import Stone.Token;
public class StringLiteral extends ASTLeaf {
public StringLiteral(Token token) {
super(token);
}
public String value() {
return token().getText();
}
}
测试语法分析器
代码清单5.2中的语法分析器需要通过调用BasicParser类的parse方法来执行。该方法将从词法分析器逐一读取非终结符program。即,以语句为单位读取单词,并进行语法分析。parse方法的返回值是一棵抽象语法树
代码清单5.10是parse方法的使用范例。该类的main方法在执行后将显示一个对话框,并对输入的程序执行语法分析。程序将调用经过分析得到的ASTree对象(抽象语法树)的tostring方法来显示结果。该过程将循环多次
下面是一段示例程序,以及执行语法分析后得到的抽象语法树
even = 0
odd = 0
i = 1
while i < 10 {
if i % 2 == 0 { // even number?
even = even + i
} else {
odd = odd + i
}
i = i + 1
}
even + odd
这段代码的语法分析结果如下
(even = 0) (odd = 0) (i = 1) (while (i < 10) ((if ((i % 2) == 0) ((even = (even + i))) else ((odd = (odd + i)))) (i = (i + 1)))) (even + odd)
代码清单5.10 ParserRunner.java
package chap5;
import Stone.ast.ASTree;
import Stone.*;
public class ParserRunner {
public static void main(String[] args) throws ParseException {
Lexer l = new Lexer(new CodeDialog());
BasicParser bp = new BasicParser();
while (l.peek(0) != Token.EOF) {
ASTree ast = bp.parse(l);
System.out.println("=> " + ast.toString());
}
}
}
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

