随行付微服务测试之性能测试
传统性能测试更多的是以事务为核心,更多的是由单个或者多个事务构成业务场景进行压测。全链路压测指完全引入相关联的系统,尽量真实模拟线上硬件环境,更多的是以请求为核心,完全模拟真实请求流量,通过引流等方式进行场景的模拟进行压测,更多的适用于业务链路较长的交易。全链路一直是性能测试中的难点,其包含系统越多测试难度就越大,系统架构中每增加一层的监控内容就会给分析带来几何倍数的难度。因此,微服务架构下的性能测试的重要性就不言而喻了。
微服务架构下为什么做全链路压测
微服务系统系统间调用关系复杂,当出现业务流量暴涨的情况从CDN、网关接入、前端、缓存、中间件、后端服务、数据库整个交易链路都会面临巨大的访问压力,此时业务系统除了收到自身的影响还会依赖其他关联系统的情况,如果某一点出现问题,系统会累加问题并影响到其他其他系统,到时候是哪个系统出问题谁也说不出清楚,比如当某系统MQ开始出现积压,下游系统处理能就可能会变慢,当MQ吃掉内存并造成宕机,整个链路交易都会停止。
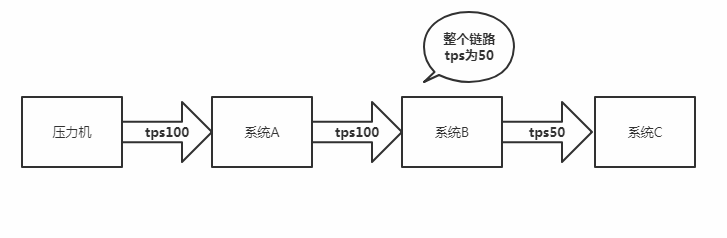
微服务架构下全链路压测的难点
如果在测试环境进行全链路压测,最大难点在于无法评估用户从客户端登录到完成交易的整个链路中,系统能的最大承载能力是多少。如果无法承载生成中的流量造成系统宕机,就会有灾难性的后果。所以在测试环境进行全链路要结合历史生成流量,并合理做出业务增长预估,如果能满足此流量可以判定为生产环境满足性能要求。当然,这只是权宜之计,如果在生产环境做全链路压测不会出现此情况。
另外,全链路压测涉及的微服务模块多,开发组多,各组开发人员又各负责自己的模块,因为版本升级块,业务层架构变化也快,很难能了解清楚最新的架构,如果漏掉一个系统的调用关系,分析就会变得非常困难。
软件的版本控制问题,因为版本升级快,造成测试环境与生成环境代码版本不一致,数据库表结构和索引不一致的情况。这种情况会造成测试结果不准确,重复测试。多系统更难控制此情况。
微服务架构下如何开展全链路测试
开展全链路压测,除了传统性能测试的需求调研、环境准备、脚本开发、数据预埋、场景设计、场景执行、应用监控分析、瓶颈定位、瓶颈修复、回归测试、结果整理、输出报告等环节外还要加入分析需压测业务场景涉及系统和协调各个压测系统资源两个环节。
1、梳理核心链路
在压测前我们一定要首先分析清楚需要压测的业务场景,只有分析清楚了业务场景才能梳理出来涉及的相关系统,分析清楚后也可以更快的找到性能瓶颈进行系统优化。这个工作一般是由架构师来梳理并确认涉及的相关系统,梳理清楚后就可以反馈给压测负责人进行人员和资源的协调了。
2、压测资源协调
在全链路压测过程中,最难的工作其实不是系统优化、压测环境搭建等技术工作,最难的是压测资源的协调工作。这里的资源不单单指压测硬件、软件、环境等资源,还包括了人力资源。
3、构建数据
数据的真实和可用是保证压测结果的关键,尽量使数据多元化,参数重复性低,可以采用生产数据脱敏的方式。数据的真实性可以保证更真实的模拟生产数据流量。数据的真实不光指发起的数据,测试数据库的铺底数据量也要与生产一致。
4、流量监控
搭建流量监控平台,收集生产各种业务的流量,统计数据,按比例进行流量回放。
5、容量评估
首先知道容量目标是多少,比如全部交易量预期目标每天1亿笔,按流量平台监控到的业务占比进行压测,这样我们可以清楚在哪个节点应该增加多少机器,既能保证系统的稳定又能避免浪费。容量评估不是一步完成的,目标需要结合历史数据和公司现有业务规模。第一步先按现有环境摸底测试,再逐步增加或减少机器,循环多次,最后达到精准的容量评估。
微服务架构下全链路压测优化
1、单系统优化
把链路中逐个环节尽量切分成小块,粒度越小越佳,单粒度分析,涉及其他系统加挡板,这样可以基本解决所有性能问题。缺点是性能周期长。
2、架构优化
分析系统架构,在硬件资源不饱和情况下尽量减少架构层。笔者在测试中遇到一个案例,A系统调用加解密服务器,A系统因特殊原因线程固定300,不能增加线程,并发线程为300时,A系统服务器CPU为60%,TPS为370左右,CPU资源不饱和,加解密服务器cpu为50%,也不饱和,但因A系统不能调整线程数量,所以把加解密服务的包部署在A系统上,此时300并发,A服务器CPU为100%,TPS为700左右。这样的好处是减少了一层系统调用的连接时间,数据传输时间,又能使硬件充分利用,减少硬件的浪费。
3、业务优化
很多开发人员都会将优化思路集中在架构层面,但是很多时候从业务流程上进行优化效果可能更好,而且提升的效果会非常明显。业务优化不包括业务流程本身,还包活实现业务的代码逻辑,此优化场景多用于跑批业务。
微服务架构下分析系统瓶颈
下面我将分享在性能测试中,常用的具体分析系统瓶颈的几个方法。
应用系统从性能角度分为CPU密集型应用和IO密集型应用,调优的目标是让硬件达到瓶颈而不是软件达到瓶颈,最直观的体现就是TPS上升和监控到的CPU和IObusy使用率达到100%。除非有特殊要求,否则尽可能使硬件使用率高。
CPU不饱和原因有很多,最常用的分析手段是查看线程信息。
1、 jps命令查看java进程pid
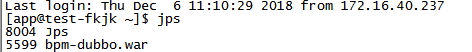
2、jstack -l 5599 > 5599.tdump 把线程信息存进一个后缀为tdump的文件里,这里后缀txt也可以,我习惯用jvisualvm打开,所以后缀是tdump
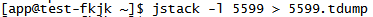
3、sz 5599.tdump 把文件下载到本地
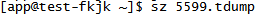
4、打开文件,查看线程信息,有三种情况:
4.1. 如果线程都是RUNNABLE状态,此时CPU利用率依然不高,说明线程池业务线程数量少,加大线程池线程数量。
4.2.如果线程状态是BLOCKED,要查该线程等待的锁编号。
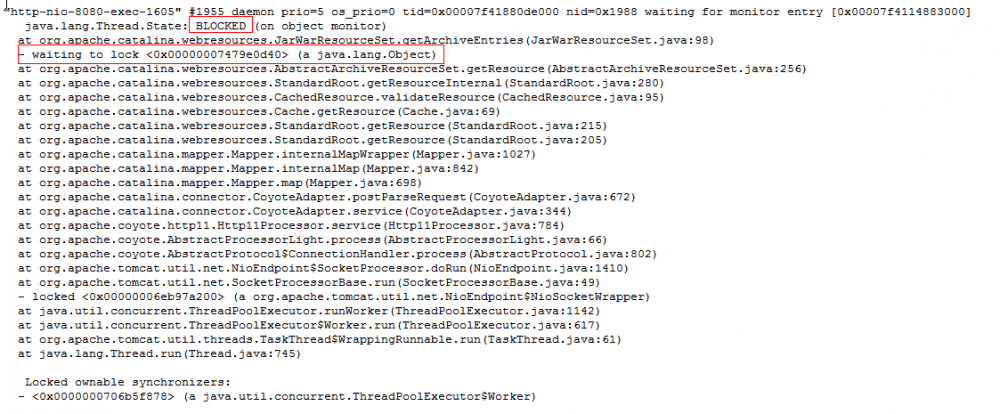
4.3.根据锁编号找到持有锁的线程,再根据信息分析代码问题并优化。
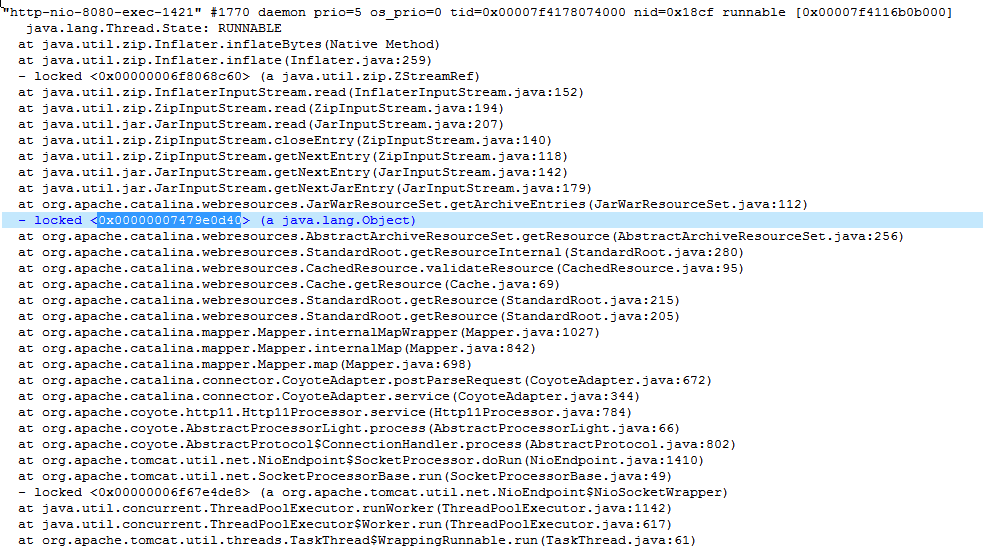
此应用CPU利用率上不去的原因是因为需要压缩的文件过大,压缩时间长,导致其他线程都在等待该线程释放锁,CPU同时间只能处理这一个线程,所以利用率低。
5、如果线程状态是WAITING,要分析是什么原因导致线程等待:
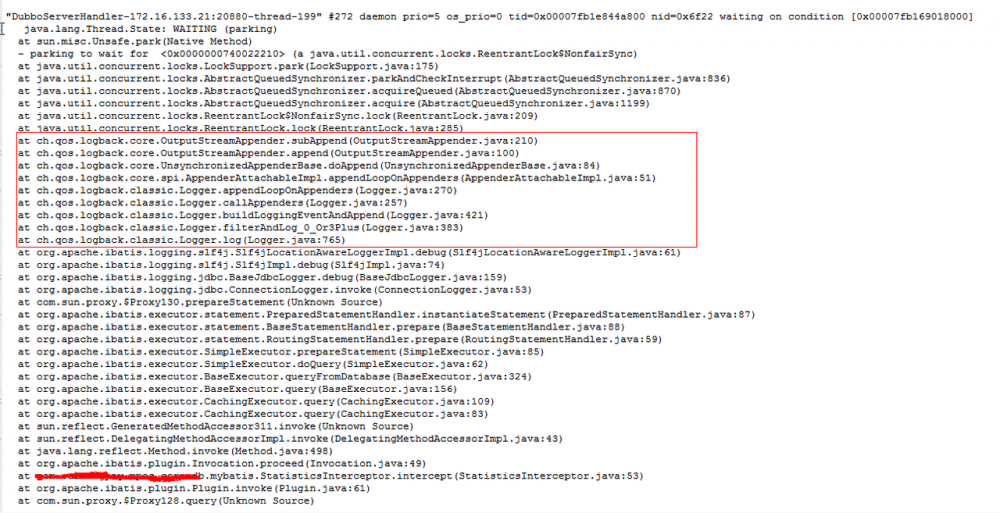
这个线程是因为logback为同步线程锁,线程等待日志写入硬盘,导致CPU利用率上不去,只要把logback改成异步就可以了。
6、IO的问题有两种情况,一种是CPU等待IO;一种是单个磁盘IObusy达到100%,其他磁盘空闲。第一种情况可以采用缓存、异步的方式去解决,这样能解决大部分性能问题。这里主要介绍第二种情况,第二种情况可以进行业务层面的IO分散来保证。就是把写入一个磁盘的文件分散写到多个磁盘上,这样就可以缓解单个磁盘的压力。对于性能人员来说,要定位到具体是哪个文件导致的IO繁忙程度高。在代码的逻辑清晰的情况下,是完全可以知道哪些文件是频繁读写的。但是对性能分析人员,通常是面对一个不是自己编写的系统,有时还是多个团队合作产生的系统。如果可以迅速地把问题到一个段具体的代码,到一个具体的文件,那就可以提高沟通的效率。
iostat命令可以发现IO异常。iotop可以定位具体哪个进程导致io异常。但要定位到具体文件,我们需要先了解一个文件的重要属性:inode。
理解inode,要从文件储存说起。文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
[root@cdhslave1 ~]# tune2fs -l /dev/sda3|grep Block Block count: 66891008 Block size: 4096 Blocks per group: 32768 复制代码
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。inode包含文件的元信息,具体来说有以下内容:
1. 文件的字节数
2. 文件拥有者的User ID
3. 文件的Group ID
4. 文件的读、写、执行权限
5. 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
6. 链接数,即有多少文件名指向这个inode
7. 文件数据block的位置
通过inode就能找到具体文件,监控inode,我用SystemTap这个工具。
SystemTap是一个诊断Linux系统性能或功能问题的开源软件。它使得对运行时的Linux系统进行诊断调式变得更容易、更简单。下图是Systemtap的工作原理:

Systemtap的运行是在内核层面,而不是shell层面。Systemtap自带的examples中有监控IO的例子,以iotop.stp为例,执行的结果是:每隔5秒打印读写总量排前10位的进程。先写一个命令dd bs=64k count=40k if=/dev/zero of=test oflag=dsync,这个命令是每次从/dev/zero 读取64k数据,然后写入当前目录下的test文件,一共重复4万次。执行命令后打开iotop.stp监控,如下图:
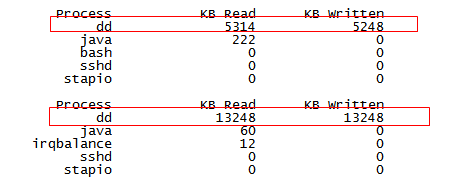
可以看到读写最多进程。但是现有脚本不能看到dd命令读文件和写文件的inode,需要自己扩展一下脚本,脚本扩展后如下图:

这里就可以看到我们读文件的inode为4072,写文件的inode为15,通过find / -inum命令可以找到具体写哪个文件。

总结
本篇介绍了全链路压测的概念,微服务架构下全链路压测的意义、难点以及如何做全链路压测,最后给出系统瓶颈分析和调优建议和方法。
正文到此结束
- 本文标签: java CDN 系统架构 软件 开源 jstack Slave1 测试环境 目录 js 压力 CTO 性能问题 http MQ 缓存 linux https 进程 时间 总结 统计 工作原理 索引 shell 线程 需求 锁 src IO 架构师 node 数据库 代码 开发 example 业务层 bus 部署 测试 grep 数据 操作系统 jvisualvm 线程池 全链路压测 并发 服务器 find 开源软件 参数 同步 IOS 监控平台 Logback root UI 快的 下载 id 微服务
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

