Shading - jdbc 源码分析(七) - sql 归并
- ResultSetFactory:分片结果集归并工厂类,获取组装后的结果集(可以理解为原始的resultSet经过处理,生成的新的resultSet)
- AbstractDelegateResultSet :代理结果集抽象类
- IteratorReducerResultSet :迭代归并的聚集结果集,对于多个resultset的结果进行迭代, 继承 AbstractDelegateResultSet
- WrapperResultSet:ShardingResultSets 的内部类,对原生resultSet包了下,重写了了firstNext()、afterFirstNext()方法
- LimitCouplingResultSet: 分页限制条件的连接结果集,用于需要对结果集做分页处理的情况,继承 AbstractDelegateResultSet
- StreamingOrderByReducerResultSet:流式排序的聚集结果集,用于对结果集排序的处理,继承 AbstractDelegateResultSet
执行过程:
sql:
SELECT o.order_id FROM t_order o WHERE o.order_id in (1000,1200) order by user_id desc limit 10
- executeQuery:
调用ResultSetFactory,获取组装后的ResultSet,generateExecutor(sql).executeQuery() 属于SQL执行部分,之前分析过,这里就不再说了
public ResultSet executeQuery(final String sql) throws SQLException {
ResultSet result;
try {
result = ResultSetFactory.getResultSet(generateExecutor(sql).executeQuery(), routeResult.getSqlStatement());
} finally {
setCurrentResultSet(null);
}
setCurrentResultSet(result);
return result;
}
复制代码
- getResultSet():
/**
* 获取结果集.
*
* @param resultSets 结果集列表
* @param sqlStatement SQL语句对象
* @return 结果集包装
* @throws SQLException SQL异常
*/
public static ResultSet getResultSet(final List<ResultSet> resultSets, final SQLStatement sqlStatement) throws SQLException {
//实例化ShardingResultSets
ShardingResultSets shardingResultSets = new ShardingResultSets(resultSets);
log.debug("Sharding-JDBC: Sharding result sets type is '{}'", shardingResultSets.getType().toString());
//组装结果集
switch (shardingResultSets.getType()) {
case EMPTY:
return buildEmpty(resultSets);
case SINGLE:
return buildSingle(shardingResultSets);
case MULTIPLE:
return buildMultiple(shardingResultSets, sqlStatement);
default:
throw new UnsupportedOperationException(shardingResultSets.getType().toString());
}
}
复制代码
2.1:实例化ShardingResultSets
public ShardingResultSets(final List<ResultSet> resultSets) throws SQLException {
this.resultSets = filterResultSets(resultSets);
type = generateType();
}
复制代码
对于分片执行后得到的ResultSet集合,过滤掉空的结果,对于非空,使用 WrapperResultSet 包装起来
问题:WrapperResultSet是个内部类,为什么还要专门新建一个内部类来处理下,直接用原生的不就行了么?
答:WrapperResultSet 继承了AbstractDelegateResultSet,这个类是被装饰类(在调用ResultSet的next()方法获取数据的时候,使用到了装饰模式),同时这个类还重写了firstNext() 和afterFirstNext()方法,获取数据的时候会用到
private List<ResultSet> filterResultSets(final List<ResultSet> resultSets) throws SQLException {
List<ResultSet> result = new ArrayList<>(resultSets.size());
for (ResultSet each : resultSets) {
if (each.next()) {
result.add(new WrapperResultSet(each));
}
}
return result;
}
复制代码
根据resultSets 集合的大小来判断是单结果集还是多结果集,多结果集的处理比较复杂(用到了装饰模式),这里指对于排序、分页的处理
private Type generateType() {
if (resultSets.isEmpty()) {
return Type.EMPTY;
} else if (1 == resultSets.size()) {
return Type.SINGLE;
} else {
return Type.MULTIPLE;
}
}
复制代码
2.2:根据ShardingResultSets的type属性构建ResultSet的子类
既然多结果集的情况比较复杂,我们就以复杂的例子来分析,上面的SQL也是分页,排序都用上了。
private static ResultSet buildMultiple(final ShardingResultSets shardingResultSets, final SQLStatement sqlStatement) throws SQLException {
ResultSetMergeContext resultSetMergeContext = new ResultSetMergeContext(shardingResultSets, sqlStatement);
return buildCoupling(buildReducer(resultSetMergeContext), resultSetMergeContext);
}
复制代码
在分析多结果集之前,我们先来了解下装饰模式,多结果集就是使用这个模式来对结果集进行排序、分页的。(关于装饰对象,我觉得这篇文章写得不错)
装饰模式的应用
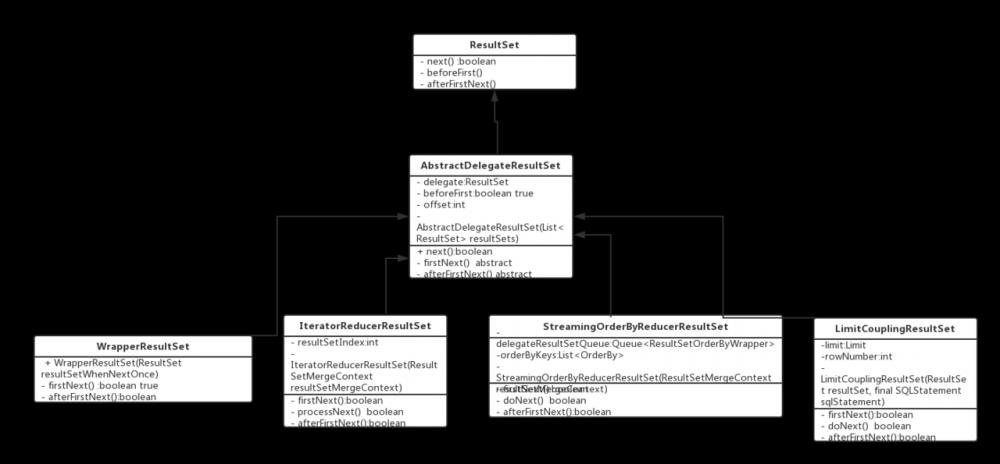
上面这幅图是结果集类间的依赖关系。
- ResultSet:抽象的构建角色,也可以理解为被装饰的原始对象
- AbstractDelegateResultSet:Decorator,装饰角色,内部维护一个抽象构建的引用,接受所有装饰对象的请求,并转发给真实的对象处理,这样就可以在调用真实对象的方法前,增加一些新的功能
- IteratorReducerResultSet:具体的装饰者,对于多个结果集,负责当一个结果集的数据处理完成后,切换到另外一个结果集上面(多个结果集遍历)
- StreamingOrderByReducerResultSet:具体的装饰者,内部维护一个 PriorityQueue ,负责对排序好的结果集消费
- LimitCouplingResultSet: 具体的装饰者,看名字就知道了吧,处理多结果集的分页
- WrapperResultSet:具体的装饰者,主要负责移动到下一个数据
下面接着分析代码: 我们的SQL中带有order by,所以返回StreamingOrderByReducerResultSet
- buildReducer:
private static ResultSet buildReducer(final ResultSetMergeContext resultSetMergeContext) throws SQLException {
//判断分组归并是否需要内存排序.
if (resultSetMergeContext.isNeedMemorySortForGroupBy()) {
resultSetMergeContext.setGroupByKeysToCurrentOrderByKeys();
return new MemoryOrderByReducerResultSet(resultSetMergeContext);
}
//判断分组是否需要排序(带有order by)
if (!resultSetMergeContext.getSqlStatement().getGroupByList().isEmpty() || !resultSetMergeContext.getSqlStatement().getOrderByList().isEmpty()) {
return new StreamingOrderByReducerResultSet(resultSetMergeContext);
}
return new IteratorReducerResultSet(resultSetMergeContext);
}
复制代码
StreamingOrderByReducerResultSet的构造函数:
public StreamingOrderByReducerResultSet(final ResultSetMergeContext resultSetMergeContext) throws SQLException {
//把resultSet传递到父类
super(resultSetMergeContext.getShardingResultSets().getResultSets());
//实例化PriorityQueue处理排序
delegateResultSetQueue = new PriorityQueue<>(getResultSets().size());
orderByKeys = resultSetMergeContext.getCurrentOrderByKeys();
}
复制代码
问题:为什么要用PriorityQueue 优先级队列处理排序,而不用普通的list sort一下
回答:我认为主要有2个方面:1、队列内部用链表维护的,在做排序的时候直接更改节点指针就可以,时间复杂度为O(1),数组的话要做移位操作,时间复杂度O(n),所以链表看起来更合适。2、假设执行后有2个结果集A、B;现在对A、B结果集的数据进行排序(每个结果集本身已经是排序好的),用队列的话,每次分别取2个结果集中的第一个数据放入队列,每次只对其中2个数据排序,用完后便从队列中移除(poll),这样比较方便,并且每次排序也只是2个值比较,对于单个next取值的情况 节省内存(数据量大的话,排序很占用内存的把)
- buildCoupling: SQL中带有limit,并且只有一个order by 字段,所以返回LimitCouplingResultSet
private static ResultSet buildCoupling(final ResultSet resultSet, final ResultSetMergeContext resultSetMergeContext) throws SQLException {
ResultSet result = resultSet;
//group by处理
if (!resultSetMergeContext.getSqlStatement().getGroupByList().isEmpty() || !resultSetMergeContext.getSqlStatement().getAggregationSelectItems().isEmpty()) {
result = new GroupByCouplingResultSet(result, resultSetMergeContext);
}
//判断是否需要内存排序:什么情况下需要?在多个order by 字段的时候
if (resultSetMergeContext.isNeedMemorySortForOrderBy()) {
resultSetMergeContext.setOrderByKeysToCurrentOrderByKeys();
result = new MemoryOrderByCouplingResultSet(result, resultSetMergeContext);
}
//分页处理
if (null != resultSetMergeContext.getSqlStatement().getLimit()) {
result = new LimitCouplingResultSet(result, resultSetMergeContext.getSqlStatement());
}
return result;
}
复制代码
至此,装饰模式需要的类已经构建好了,分别是:LimitCouplingResultSet处理分页、StreamingOrderByReducerResultSet处理排序、WrapperResultSet
resultSet.next():
AbstractDelegateResultSet 重写了resultSet.next()方法,下面是重写的逻辑:
@Override
public final boolean next() throws SQLException {
//beforeFirst 默认true,走firstNext
boolean result = beforeFirst ? firstNext() : afterFirstNext();
beforeFirst = false;
if (result) {
LoggerFactory.getLogger(this.getClass().getName()).debug(
"Access result set, total size is: {}, result set hashcode is: {}, offset is: {}", getResultSets().size(), delegate.hashCode(), ++offset);
}
return result;
}
复制代码
LimitCouplingResultSet#firstNext():
对于A、B 2个结果集,比如要查 10,15索引位的数据,那么我们会把0,15索引位的结果查询出来,然后再过滤掉结果集A 10索引位前的数据,剩下5个数据再从A、B结果集取
@Override
protected boolean firstNext() throws SQLException {
return skipOffset() && doNext();
}
//过滤offset索引位前的数据
private boolean skipOffset() throws SQLException {
for (int i = 0; i < limit.getOffset(); i++) {
// 如果没有数据了,就返回false,说明A结果集没有数据了,交给下一个装饰类,切换到B结果集
if (!getDelegate().next()) {
return false;
}
}
return true;
}
//当rowNumber>rowCOunt,说明已经取够了5条数据,此时可以返回了
private boolean doNext() throws SQLException {
return ++rowNumber <= limit.getRowCount() && getDelegate().next();
}
复制代码
分页处理完,getDelegate().next() 调用StreamingOrderByReducerResultSet#next,StreamingOrderByReducerResultSet继承了AbstractDelegateResultSet,所以也是走的上面重写的next()逻辑。
- StreamingOrderByReducerResultSet#firstNext()
遍历A、B 2个结果集,分别取出结果集中的第一个元素,放入队列中,peek出第一个元素(此时的元素已经按照排序规则排好),setDelegate()切换包装(排序后)的结果集,这样下一个装饰类获取到的就是排序后的结果集
protected boolean firstNext() throws SQLException {
for (ResultSet each : getResultSets()) {
ResultSetOrderByWrapper wrapper = new ResultSetOrderByWrapper(each);
//wrapper#next()取出第一个元素
if (wrapper.next()) {
delegateResultSetQueue.offer(wrapper);
}
}
return doNext();
}
private boolean doNext() {
if (delegateResultSetQueue.isEmpty()) {
return false;
}
setDelegate(delegateResultSetQueue.peek().delegate);
log.trace("Chosen order by value: {}, current result set hashcode: {}", delegateResultSetQueue.peek().row, getDelegate().hashCode());
return true;
}
@RequiredArgsConstructor
private class ResultSetOrderByWrapper implements Comparable<ResultSetOrderByWrapper> {
private final ResultSet delegate;
//具有排序功能的数据行对象
private OrderByResultSetRow row;
boolean next() throws SQLException {
// 调用next()
boolean result = delegate.next();
//有值
if (result) {
//实例化 带有排序值的行对象
row = new OrderByResultSetRow(delegate, orderByKeys);
}
return result;
}
//比较
@Override
public int compareTo(final ResultSetOrderByWrapper o) {
return row.compareTo(o.row);
}
}
复制代码
问:怎么排序的?
答:ResultSetOrderByWrapper 实现了Comparable接口,我们调用next方法,实例化了 OrderByResultSetRow 这一行对象,行对象把排序的字段值取到,也重写了Comparable接口,当我们把ResultSetOrderByWrapper对象塞到队列里,队列会调用对象的compareTo方法,对队列的数据进行重新排序,这样取出来的第一个元素就是排好序后的元素。
排序相关代码:
public final class OrderByResultSetRow extends AbstractResultSetRow implements Comparable<OrderByResultSetRow> {
private final List<OrderBy> orderBies;
private final List<Comparable<?>> orderByValues;
public OrderByResultSetRow(final ResultSet resultSet, final List<OrderBy> orderBies) throws SQLException {
super(resultSet);
this.orderBies = orderBies;
orderByValues = loadOrderByValues();
}
//加载排序字段的值
private List<Comparable<?>> loadOrderByValues() {
List<Comparable<?>> result = new ArrayList<>(orderBies.size());
for (OrderBy each : orderBies) {
Object value = getCell(each.getColumnIndex());
Preconditions.checkState(value instanceof Comparable, "Sharding-JDBC: order by value must extends Comparable");
result.add((Comparable<?>) value);
}
return result;
}
//重新排序规则
@Override
public int compareTo(final OrderByResultSetRow otherOrderByValue) {
for (int i = 0; i < orderBies.size(); i++) {
OrderBy thisOrderBy = orderBies.get(i);
int result = ResultSetUtil.compareTo(orderByValues.get(i), otherOrderByValue.orderByValues.get(i), thisOrderBy.getOrderByType());
if (0 != result) {
return result;
}
}
return 0;
}
}
复制代码
排好序后,AbstractDelegateResultSet 的ResultSet delegate属性就是正确的结果集,调用getString()之类的方法获取SQL结果。
@Override
public final String getString(final String columnLabel) throws SQLException {
return delegate.getString(columnLabel);
}
复制代码
最后:
小尾巴走一波,欢迎关注我的公众号,不定期分享编程、投资、生活方面的感悟:)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

