Kafka如何解决常见的微服务通信问题
微服务自成立以来就以不同的方式相互沟通。有些人更喜欢使用HTTP REST API,但这些API有自己的排队问题,而有些则更喜欢较旧的消息队列,比如RabbitMQ,它们带有扩展和操作方面的问题。
以kafka为中心的架构旨在解决这两个问题。
在本文中,我将解释Apache Kafka如何改进微服务中使用的历史HTTP REST API /消息队列体系结构以及它如何进一步扩展其功能。
两个阵营的故事
我们故事中的第一个阵营是通过直接调用其他服务来处理通信,通常通过HTTP REST API或其他形式的远程过程调用(RPC)。
第二个阵营在借用面向服务的体系结构(SOA)的企业服务总线概念时,使用负责与其他服务进行通信并作为消息队列运行的中介。
这个角色通常是通过使用像RabbitMQ这样的消息代理来完成的。这种通信方式以额外的网络跳跃为代价消除了来自各个服务的大部分通信负担。
微服务使用HTTP REST API
HTTP REST API是在服务之间执行RPC的常用方法。它的主要好处是在开始时简化设置和发送消息的相对效率。
但是,此模型要求其实现者考虑排队以及如果传入请求的数量超过节点容量时该怎么做。例如,如果您假设在超出其容量的服务之前有一长串服务,那么链中的所有前述服务都需要具有相同类型的背压处理来应对该问题。
此外,此模型要求所有单独的HTTP REST API服务都需要高度可用。在由微服务构成的长处理管道中,没有一个微服务能够丢失所有组件部分,只有当来自任何给定组的至少一个进程仍然正常运行时,这才起作用。
这通常需要将负载平衡器放在这些微服务的前面。此外,服务发现通常是必须的,因为不同的微服务需要找出调用的位置以便彼此通信。
这种模式的一个优点是它提供了潜在的优秀延迟,因为在给定的请求路径中很少有中间人,并且这些组件(如Web服务器和负载平衡器)具有高性能且经过彻底的战斗测试。
不同RPC微服务之间的一般依赖性处理通常很快变得更加复杂,并最终开始减缓开发工作。为了解决这些问题,还引入了提供服务网格的Envoy代理等新方法。
虽然这些解决了模型的许多负载平衡和服务发现问题,但它们需要通过简单,直接的RPC调用来提高系统的整体复杂性。
许多公司开始时只有少数微服务相互交谈,但最终他们的系统变得越来越复杂,在彼此之间产生了意义上的联系。
消息队列
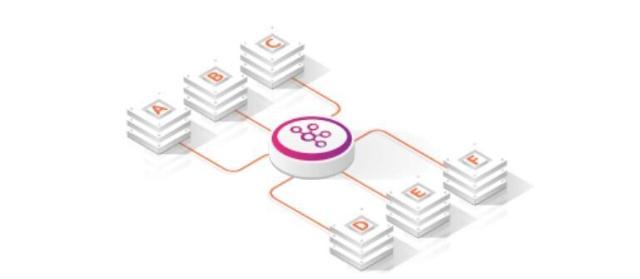
构建微服务通信的另一种方式是围绕消息总线或消息排队系统的使用。老式的面向服务的体系结构称为这些企业服务总线(ESB)。通常,他们一直是像RabbitMQ或ActiveMQ这样的消息代理。
消息代理充当集中式消息服务,通过该服务,所有有问题的微服务相互通信,消息服务处理诸如排队和高可用性之类的事情,以确保服务之间的可靠通信。
通过支持消息队列,可以将消息接收到队列中以供稍后处理,而不是在峰值需求期间处理容量最大化时丢弃它们。
但是,许多消息代理已经证明了可扩展性的限制以及它们如何在集群环境中处理消息持久性和交付的警告。
围绕消息队列的另一个大型对话主题是它们在错误情况下的行为,例如,消息传递是否保证至少发生一次,最多一次,等等。
选择的语义取决于消息队列实现,这意味着您必须熟悉其消息传递语义。
此外,向体系结构添加消息队列会添加要操作和维护的新组件,并且通过为发送的消息添加一个额外的网络跃点也会增加网络延迟,这会产生额外的延迟。
通过可以与消息排队系统一起使用的访问控制列表(ACL)的集中性,可以在此模型中略微简化安全问题,从而可以集中控制谁可以读取和写入哪些消息。
集中化还带来了一些安全方面的好处。例如,您不必允许所有服务相互连接,而是只允许连接到消息队列服务,并防止其他服务相互远离,从而减少攻击面。
以kafka为中心的新时代的优势
Apache Kafka是一个由LinkedIn创建和开源的事件流媒体平台。使它与旧的消息排队系统完全不同的是它能够在发送者不知道谁将接收消息的意义上将发送者与接收者完全分离。
在许多其他消息代理系统中,需要预知谁将阅读消息; 这阻碍了传统排队系统中新用例的采用。
使用Apache Kafka时,消息被写入称为主题的日志样式流,并且写入主题的发件人完全忘记了从那里实际读取消息的人或者什么。因此,为了一个新的目的,提出一个新的用例来处理Kafka主题内容是一切照旧的。
Kafka完全不知道已发送消息的有效负载,允许以任意方式序列化消息,尽管大多数人仍然使用JSON,AVRO或Protobufs作为其序列化格式。
您还可以轻松设置ACL,以限制哪些生产者和消费者可以写入和读取系统中的哪些主题,从而为您提供对所有消息传递的集中安全控制。
通常看到Kafka被用作消防风格数据管道的接收器,其数据量可能很大。例如,Netflix报告说他们每天使用Kafka处理超过两万亿条消息。
消费者拥有的一个重要特性是,当消息负载增加且Kafka消费者的数量因故障或容量增加而发生变化时,Kafka将自动重新平衡消费者之间的处理负载。这使得需要从微服务中明确地处理高可用性到Apache Kafka服务本身。
处理流数据的能力将Kafka的功能扩展到作为消息传递系统运行到流数据平台之外。
最重要的是,Apache Kafka在将其用作微服务通信总线时提供相当低的延迟,即使它为所有请求引入了额外的网络跃点。
这种低延迟,自动扩展,集中管理和经过验证的高可用性的强大组合使Apache Kafka能够将其范围从微服务通信扩展到您尚未想象的许多流实时分析用例。
原文 http://mushiming.top/mushblog/archives/888正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

