微服务注册中心如何承载大型系统的千万级访问?
点击上方 " 石杉的架构笔记", 右上角 选择“设为星标”
周一到周五早8点,精品技术文章准时送上!
往期文章
-
拜托!面试请不要再问我Spring Cloud底层原理 》
目录:
一、问题起源
二、 Eureka Server 设计精妙的注册表存储结构
三、 Eureka Server 端优秀的多级缓存机制
四、总结
一、问题起源
Spring Cloud架构体系中, Eureka 是一个至关重要的组件,它扮演着微服务 注册中心的角色,所有的服务注册与服务发现,都是依赖 Eureka 的。
不少初学Spring Cloud的朋友在落地公司生产环境部署时,经常会问:
-
Eureka Server 到底要部署几台机器?
-
我们的系统那么多服务,到底会对 Eureka Server 产生多大的访问压力?
-
Eureka Server 能不能抗住一个大型系统的访问压力?
如果你也有这些疑问,别着急!咱们这就一起去看看,Eureka作为微服务注册中心的核心原理
下面这些问题,大家先看看,有个大概印象。 带着这些问题,来看后面的内容,效果更佳
-
Eureka 注册中心使用什么样的方式来储存各个服务注册时发送过来的机器地址和端口号?
-
各个服务找 Eureka Server 拉取注册表的时候,是什么样的频率?
-
各个服务是如何拉取注册表的?
-
一个几百服务,部署上千台机器的大型分布式系统,会对 Eureka Server 造成多大的访问压力?
-
Eureka Server 从技术层面是如何抗住日千万级访问量的?
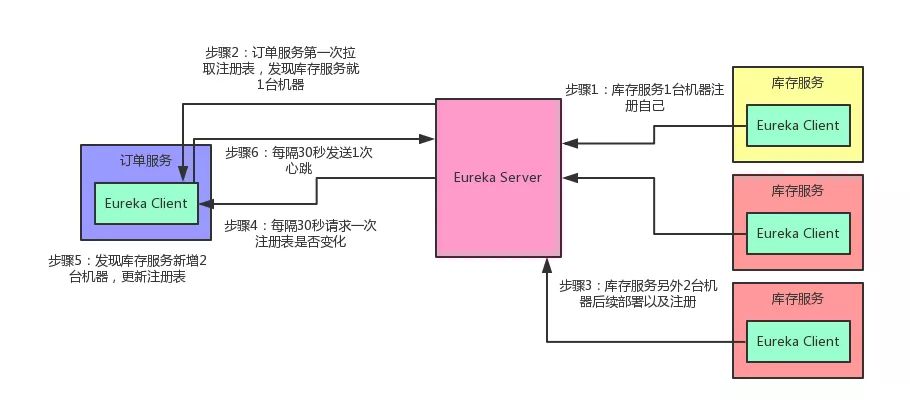
先给大家说一个基本的知识点,各个服务内的Eureka Client组件,默认情况下,每隔 30 秒会发送一个请求到 Eureka Server ,来拉取最近有变化的服务信息
举个例子 :
-
库存服务原本部署在 1 台机器上,现在扩容了,部署到了 3 台机器,并且均注册到了 Eureka Server 上。
-
然后订单服务的 Eureka Client 会每隔 30 秒去找 Eureka Server 拉取最近注册表的变化,看看其他服务的地址有没有变化。
除此之外, Eureka还有一个心跳机制 ,各个 Eureka Client 每隔 30 秒会发送一次心跳到 Eureka Server ,通知人家说,哥们,我这个服务实例还活着!
如果某个Eureka Client很长时间没有发送心跳给 Eureka Server ,那么就说明这个服务实例已经挂了。
光看上面的文字,大家可能没什么印象。老规矩!咱们还是来一张图,一起来直观的感受一下这个过程。
二、Eureka Server设计精妙的注册表存储结构
现在咱们假设手头有一套大型的分布式系统,一共100个服务,每个服务部署在 20 台机器上,机器是 4 核 8G 的标准配置。
也就是说,相当于你一共部署了100 * 20 = 2000个服务实例,有 2000 台机器。
每台机器上的服务实例内部都有一个Eureka Client组件,它会每隔 30 秒请求一次 Eureka Server, 拉取变化的注册表。
此外,每个服务实例上的Eureka Client都会每隔 30 秒发送一次心跳请求给 Eureka Server 。
那么大家算算, Eureka Server 作为一个微服务注册中心, 每秒钟要被请求多少次?一天要被请求多少次?
-
按标准的算法,每个服务实例每分钟请求 2 次拉取注册表,每分钟请求 2 次发送心跳
-
这样一个服务实例每分钟会请求 4 次, 2000 个服务实例每分钟请求 8000 次
-
换算到每秒,则是 8000 / 60 = 13 3 次左右,我们就大概估算为 Eureka Server 每秒会被请求 150 次
-
那一天的话,就是 8000 * 60 * 24 = 1152 万,也就是 每天千万级访问量
好!经过这么一个测算,大家是否发现这里的奥秘了?
-
首先,对于微服务注册中心这种组件,在一开始设计它的拉取频率以及心跳发送频率时,就已经考虑到了一个大型系统的各个服务请求时的压力,每秒会承载多大的请求量。
-
所以各服务实例 每隔 30 秒 发起请求拉取变化的注册表,以及 每隔 30 秒 发送心跳给 Eureka Server ,其实这个时间安排是有其用意的。
按照我们的测算,一个上百个服务,几千台机器的系统,按照这样的频率请求Eureka Server,日请求量在千万级,每秒的访问量在 150 次左右。
即使算上其他一些额外操作,我们姑且就算每秒钟请求 Eureka Server 在 200 次 ~300 次吧。
所以通过设置一个适当的拉取注册表以及发送心跳的频率,可以保证大规模系统里对Eureka Server的请求压力不会太大。
关键问题来了 , Eureka Server 是如何保证轻松抗住这每秒数百次请求,每天千万级请求的呢?
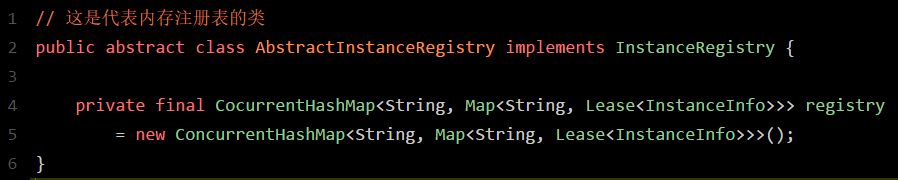
要搞清楚这个,首先得清楚 Eureka Server 到底是用什么来存储注册表的?三个字, 看源码
接下来咱们就一起进入 Eureka 源码里一探究竟:
-
如上图所示,图中的这个名字叫做 registry 的 Cocurrent HashMap ,就是注册表的核心结构 。看完之后忍不住先赞叹一下, 精妙的设计!
-
从代码中可以看到, Eureka Server 的注册表直接基于 纯内存 ,即在内存里维护了一个数据结构。
-
各个服务的注册、服务下线、服务故障,全部会在内存里维护和更新这个注册表。
-
各个服务每隔 30 秒拉取注册表的时候, Eureka Server 就是直接提供内存里存储的有变化的注册表数据给他们就可以了。
-
同样,每隔 30 秒发起心跳时,也是在这个纯内存的Map 数据结构里更新心跳时间。
一句话概括 :维护注册表、拉取注册表、更新心跳时间,全部发生在内存里!这是 Eureka Server 非常核心的一个点。
搞清楚了这个,咱们再来分析一下registry这个东西的数据结构,大家千万别被它复杂的外表唬住了,沉下心来,一层层的分析!
-
首先,这个 ConcurrentHashMap的key就是服务名称 ,比如 “inventory-service”,就是一个服务名称。
-
value则 代表了一个服务的多个服务实例 。
-
举例:比如 “inventory-service”是可以有3个服务实例的,每个服务实例部署在一台机器上。
再来看看作为value的这个Map:
Map<String, Lease<InstanceInfo > >
-
这个 Map的key就是 服务实例的 id
-
value是一个叫 做 Lease 的类 ,它的泛型是一个叫做 InstanceInfo 的东东,你可能会问,这俩又是什么鬼?
-
首先说下 InstanceInfo,其实啊,我们见名知义,这个 InstanceInfo就代表了 服务实例的具体信息 ,比如机器的 ip地址、hostname以及端口号。
-
而
这个Lease,里面则会
三、Eureka Server端优秀的多级缓存机制
假设 Eureka Server 部署在 4 核 8G 的普通机器上,那么 基于内存来承载各个服务的请求,每秒钟最多可以处理多少请求呢?
-
根据之前的测试,单台 4 核 8G 的机器,处理纯内存操作,哪怕加上一些网络的开销, 每秒处理几百请求也是轻松加愉快的 。
-
而且 Eureka Server 为了 避免同时读写内存数据结构造成的并发冲突 问题,还采用了 多级缓存机制 来进一步提升服务请求的响应速度。
-
在拉取注册表的时候:
-
首先从 ReadOnlyCacheMap 里查缓存的注册表。
-
若没有,就找 ReadWriteCacheMap 里缓存的注册表。
-
如果还没有,就从 内存中获取实际的注册表数据。
-
在注册表发生变更的时候:
-
会在内存中更新变更的注册表数据,同时 过期掉 ReadWriteCacheMap 。
-
此过程不会影响 ReadOnlyCacheMap 提供人家查询注册表。
-
一段时间内(默认 30 秒),各服务拉取注册表会直接读 ReadOnlyCacheMap
-
30 秒过后, Eureka Server 的后台线程发现 ReadWriteCacheMap 已经清空了,也会清空 ReadOnlyCacheMap 中的缓存
-
下次有服务拉取注册表,又会从内存中获取最新的数据了,同时填充各个缓存。
多级缓存机制的优点是什么?
-
尽可能保证了内存注册表数据不会出现频繁的读写冲突问题。
-
并且进一步保证对Eureka Server的大量请求,都是快速从纯内存走,性能极高。
为方便大家更好的理解,同样来一张图,大家跟着图再来回顾一下这整个过程:

四、总结
-
通过上面的分析可以看到, Eureka 通过设置适当的请求频率 (拉取注册表 30 秒间隔,发送心跳 30 秒间隔) ,可以保证一个大规模的系统每秒请求 Eureka Server 的次数在几百次。
-
同时通过纯内存的注册表,保证了所有的请求都可以在内存处理,确保了极高的性能
-
另外,多级缓存机制,确保了不会针对内存数据结构发生频繁的读写并发冲突操作,进一步提升性能。
上述就是Spring Cloud架构中, Eureka 作为微服务注册中心可以承载大规模系统每天千万级访问量的原理。
如有收获,请帮忙转发,您的鼓励是作者最大的动力,谢谢!
一大波 微服务、分布式、高并发、高可用 的 原创系列 文章正在路上, 欢迎扫描下方二维码 ,持续关注:
《双 1 1 背后 每秒上万并发下的 Spring Cloud 参数优化实战》 ,敬请期待
《微服务架构如何保障双 1 1 狂欢下的 9 9.99% 高可用》 ,敬请期待

石杉的架构笔记(id:shishan100)
十余年 BAT架构经验 倾囊相授
正文到此结束
热门推荐








相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

