亿级流量系统架构之如何在上万并发场景下设计可扩展架构(上)?【石杉的架构笔记】
欢迎关注个人公众号:石杉的架构笔记(ID:shishan100)
周一至周五早8点半!精品技术文章准时送上!
一、写在前面
之前更新过一个“亿级流量系统架构”系列,主要讲述了一个大规模商家数据平台的如下几个方面:
- 如何承载百亿级数据存储
- 如何设计高容错的分布式架构
- 如何设计承载百亿流量的高性能架构
- 如何设计每秒数十万并发查询的高并发架构
- 如何设计全链路99.99%高可用架构。
接下来,我们将会继续通过几篇文章,对这套系统的可扩展架构、数据一致性保障等方面进行探讨。
如果没看过本系列文章的同学可以先回过头看看之前写的几篇文章:
亿级流量系统架构
- 亿级流量系统架构之如何支撑百亿级数据的存储与计算
- 亿级流量系统架构之如何设计高容错分布式计算系统
- 亿级流量系统架构之如何设计承载百亿流量的高性能架构
- 亿级流量系统架构之如何设计每秒十万查询的高并发架构
- 亿级流量系统架构之如何设计全链路99.99%高可用架构
二、背景回顾
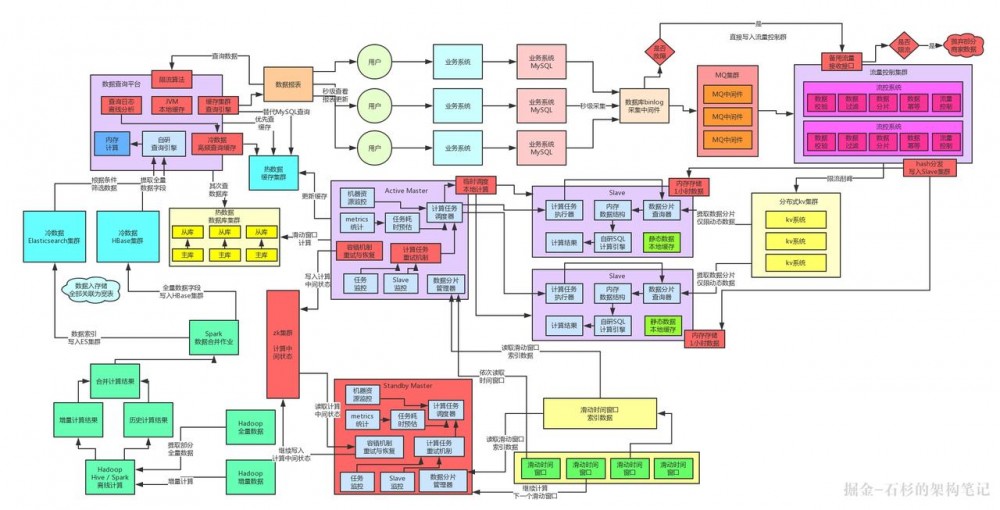
如果大家看过之前的一系列文章,应该依稀还记得上一篇文章最后,整个系统架构大致演进到了如下图的一个状态。
如果没看过之前的系列文章,上来猛一看下面这个图,绝对一脸懵逼,就看到一片“花花绿绿”。这个也没办法,复杂的系统架构都是特别的庞杂的。
三、实时计算平台与数据查询平台之间的耦合
好,咱们正式开始!这篇文章咱们来聊聊这套系统里的不同子系统之间通信过程的一个可扩展性的架构处理。
这里面蕴含了线上复杂系统之间交互的真实场景和痛点,相信对大家能够有所启发。
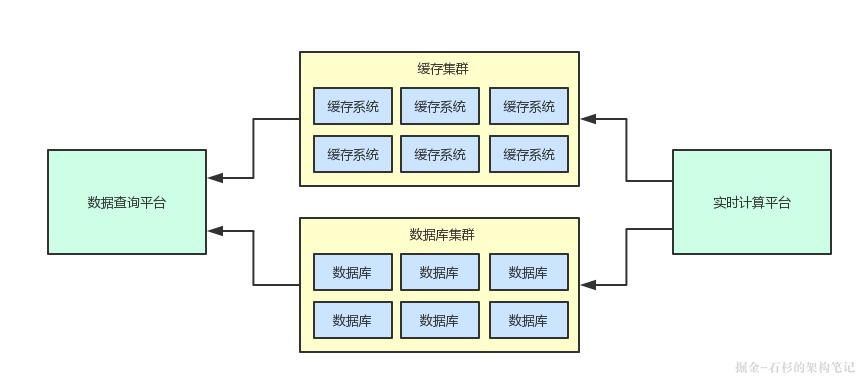
我们就关注一下上面的 架构图里左侧的部分 ,处于中间位置的那个实时计算平台在完成了每一个数据分片的计算过后,都会将计算结果写入到最左侧的数据查询平台中。
出于种种考量,因为计算结果的数据量相比于原始数据的数据量,实际上已经少了一个数量级了。
所以,我们选择的是实时计算平台直接将数据写入到数据查询平台的MySQL数据库集群中,然后数据查询平台基于MySQL数据库集群来对外提供查询请求。
此外,为了保证当天的实时计算结果能够高并发的被用户查询,因此当时采取的是实时计算平台的计算结果同时双写缓存集群和数据库集群。
这样,数据查询平台可以优先走缓存集群,如果找不到缓存才会从数据库集群里回查数据。
所以上述就是实时计算平台与数据查询平台之间在某一个时期的一个典型的系统耦合架构。
两个不同的系统之间,通过同一套数据存储(数据库集群+缓存集群)进行了耦合。
大家看看下面的图,再来清晰的感受一下系统之间耦合的感觉。
系统耦合痛点1:被动承担的高并发写入压力
大家如果仔细看过之前的系列文章,大概就该知道,在早期主要是集中精力对实时计算平台的架构做了大量的演进,以便于让他可以支撑超高并发写入、海量数据的超高性能计算,最后就可以抗住每秒数万甚至数十万的数据涌入的存储和计算。
但是因为早期采用了上图的这种最简单、最高效、最实用的耦合交互方式,实时计算平台直接把每个数据分片计算完的结果写入共享存储中,就导致了一个很大的问题。
实时计算平台能抗住超高并发写入没问题了,而且还能快速的高性能计算也没问题。
但是,他同时会随着数据量的增长,越来越高并发的将计算结果写入到一个数据库集群中。而这个数据库集群在团队划分的时候,实际上是交给数据查询平台团队来负责维护的。
也就是说,对实时计算平台团队来说,他们是不care那个数据库集群是什么状态的,而就是不停的把数据写入到那个集群里去。
但是,对于数据查询平台团队来说,他们就会被动的承担实时计算平台越来越高并发压力写入的数据。
这个时候数据查询平台团队的同学很可能处于这样的一种焦躁中:本来自己这块系统也有很多架构上的改进点要做,比如说之前提到的冷数据查询引擎的自研。
但是呢,他们却要不停的被线上数据库服务器的报警搞的焦头烂额,疲于奔命。
因为数据库服务器单机写入压力可能随着业务增长,迅速变成每秒5000~6000的写入压力,每天到了高峰期,线上服务器的CPU、磁盘、IO、网络等压力巨大,报警频繁。
此时数据查询平台团队的架构演进节奏就会被打乱,因为必须被动的去根据实时计算平台的写入压力来进行调整,必须立马停下手中的工作,然后去考虑如何对数据库集群做分库分表的方案,如何对表进行扩容,如何对库进行扩容。
同时结合分库分表的方案,数据查询平台自身的查询机制又要跟着一起改变,大量的改造工作,调研工作,数据迁移工作,上线部署工作,代码改造工作。
实际上,上面说的这种情况,绝对是不合理的。
因为整个这套数据平台是一个大互联网公司里核心业务部门的一个核心系统,他是数十个Java工程师与大数据工程师通力合作一起开发,而且里面划分为了多个team。
比如说数据接入系统是一个团队负责,实时计算平台是一个团队负责,数据查询平台是一个团队负责,离线数据仓库是一个团队负责,等等。
所以只要分工合作了以后,那么就不应该让一个团队被动的去承担另外一个团队猛然增长的写入压力,这样会打破每个团队自己的工作节奏。
导致这个问题的根本原因,就是因为两个系统间,没有做任何解耦的处理。
这就导致数据查询平台团队根本无法对实时计算平台涌入过来的数据做任何有效的控制和管理,这也导致了“被动承担高并发写入压力”问题的发生。
这种系统耦合导致的被动高并发写入压力还不只是上面那么简单,实际在上述场景中,线上生产环境还发生过各种奇葩的事情:
某一次线上突然产生大量的热数据,热数据计算结果涌入数据查询平台,因为没做任何管控,几乎一瞬间导致某台数据库服务器写入并发达到1万+,DBA焦急的担心数据库快宕机了,所有人也都被搞的焦头烂额,心理崩溃。
系统耦合痛点2:数据库运维操作导致的线上系统性能剧烈抖动
在这种系统耦合的场景下,反过来实时计算平台团队的同学其实心里也会呐喊:我们心里也苦啊!
因为反过来大家可以思考一下,线上数据库中的表结构改变,那几乎可以说是再正常不过了,尤其是高速迭代发展中的业务。
需求评审会上,要是不小心碰上某个产品经理,今天改需求,明天改需求。工程师估计会怒火冲天的想要砍人。但是没办法,最后还是得为五斗米折腰,该改的需求还是得改。该改的表结构也还是要改,改加的索引也还是要加。
但是大家考虑一个点,如果说对上述这种强耦合的系统架构,单表基本都是在千万级别的数据量,同时还有单台数据库服务器每秒几千的写入压力。
在这种场景下,在线上走一个MySQL的DDL语句试一试?奉劝大家千万别胡乱尝试,因为数据查询团队里的年轻同学,干过这个事儿。
实际的结果就是,DDL咔嚓一执行,对线上表结构进行修改,直接导致实时计算平台的写入数据库的性能急剧下降10倍以上。。。
然后连带导致实时计算平台的数据分片计算任务大量的延迟。再然后,因为实时计算之后的数据无法尽快反馈到存储中,无法被用户查询到,导致了大量的线上投诉。
并且,DDL语句执行的还特别的慢,耗时数十分钟才执行完毕,这就导致数十分钟里,整套系统出现了大规模的计算延迟,数据延迟。
一直到数十分钟之后DDL语句执行完毕,实时计算平台才通过自身的自动延迟调度恢复机制慢慢恢复了正常的计算。
orz......于是从此之后,数据查询平台的攻城狮,必须得小心翼翼的在每天凌晨2点~3点之间进行相关的数据库运维操作,避免影响线上系统的性能稳定性。
但是,难道人家年轻工程师没有女朋友?难道年长工程师没有老婆孩子?经常在凌晨3点看看窗外的风景,然后打个滴滴回家,估计没任何人愿意。
其实上述问题,说白了,还是因为两套系统直接通过存储耦合在了一起,导致了任何一个系统只要有点异动,直接就会影响另外一个系统。 耦合!耦合!还是耦合!
系统耦合痛点N。。。
其实上面只不过是挑了其中两个系统耦合痛点来说明而已,文章篇幅有限,很难把上述长达数月的耦合状态下的各种痛点一一说明,实际线上生产环境的痛点还包括不限于:
- 实时计算平台自身写入机制有bug导致的数据丢失,结果让数据查询平台的同学去排查;
- 实时计算平台对缓存集群和数据库集群进行双写的时候,双写一致性的保证机制,居然还需要自己来实现,直接导致自己的代码里混合了大量不属于自己的业务逻辑;
- 数据查询平台有时候做了分库分表运维操作之后,比如扩容库和表,居然还得让实时计算平台的同学配合着一起修改代码配置,一起测试和部署上线
- 数据查询平台和实时计算平台两个team的同学在上述大量耦合场景下,经常天天一起加班到凌晨深夜,各自的女朋友都以为他们打算在一起了,但实际情况是一堆大老爷儿们天天被搞的焦头烂额,苦不堪言,都不愿意多看对方一眼
- 因为系统耦合导致的各种问题,两个team都要抽时间精力来解决,影响了自己那套系统的架构演进进度,没法集中人力和时间做真正有价值和意义的事情
四、下集预告
下一篇文章,我们就来聊一聊针对这些痛点,如何灵活的运用MQ消息中间件技术来进行复杂系统之间的解耦,同时解耦过后如何来自行对流量数据进行管控,解决各种系统耦合的问题。
敬请期待 :
- 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(中)?
- 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(下)?
END
如有收获,请帮忙转发,您的鼓励是作者最大的动力,谢谢!
一大波微服务、分布式、高并发、高可用的原创系列文章正在路上
欢迎扫描下方二维码 ,持续关注:

石杉的架构笔记(id:shishan100)
十余年BAT架构经验倾囊相授
推荐阅读:
1、
拜托!面试请不要再问我Spring Cloud底层原理
2、
【双11狂欢的背后】微服务注册中心如何承载大型系统的千万级访问?
3、
【性能优化之道】每秒上万并发下的Spring Cloud参数优化实战
4、
微服务架构如何保障双11狂欢下的99.99%高可用
5、
兄弟,用大白话告诉你小白都能听懂的Hadoop架构原理
6、
大规模集群下Hadoop NameNode如何承载每秒上千次的高并发访问
7、【
性能优化的秘密】Hadoop如何将TB级大文件的上传性能优化上百倍
8、 拜托,面试请不要再问我TCC分布式事务的实现原理坑爹呀!
9、 【坑爹呀!】最终一致性分布式事务如何保障实际生产中99.99%高可用?
10、 拜托,面试请不要再问我Redis分布式锁的实现原理!
11、【眼前一亮!】看Hadoop底层算法如何优雅的将大规模集群性能提升10倍以上?
12、亿级流量系统架构之如何支撑百亿级数据的存储与计算
13、 亿级流量系统架构之如何设计高容错分布式计算系统
14、 亿级流量系统架构之如何设计承载百亿流量的高性能架构
15、 亿级流量系统架构之如何设计每秒十万查询的高并发架构
16、 亿级流量系统架构之如何设计全链路99.99%高可用架构
17、 七张图彻底讲清楚ZooKeeper分布式锁的实现原理
18、
大白话聊聊Java并发面试问题之volatile到底是什么?
19、 大白话聊聊Java并发面试问题之Java 8如何优化CAS性能?
20、 大白话聊聊Java并发面试问题之谈谈你对AQS的理解?
21、 大白话聊聊Java并发面试问题之公平锁与非公平锁是啥?
22、 大白话聊聊Java并发面试问题之微服务注册中心的读写锁优化
23、 互联网公司的面试官是如何360°无死角考察候选人的?(上篇)
24、 互联网公司面试官是如何360°无死角考察候选人的?(下篇)
25、 Java进阶面试系列之一:哥们,你们的系统架构中为什么要引入消息中间件?
26、 【Java进阶面试系列之二】:哥们,那你说说系统架构引入消息中间件有什么缺点?
27、 【行走的Offer收割机】记一位朋友斩获BAT技术专家Offer的面试经历
28、 【Java进阶面试系列之三】哥们,消息中间件在你们项目里是如何落地的?
29、 【Java进阶面试系列之四】扎心!线上服务宕机时,如何保证数据100%不丢失?
30、 一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!
31、 【高并发优化实践】10倍请求压力来袭,你的系统会被击垮吗?
32、 【Java进阶面试系列之五】消息中间件集群崩溃,如何保证百万生产数据不丢失?
作者:石杉的架构笔记
链接:https://juejin.im/post/5c1e51fd6fb9a049a81f4f35
来源:掘金
著作权归作者所有,转载请联系作者获得授权
正文到此结束
- 本文标签: 二维码 DDL 分布式 分布式锁 并发 mysql https Namenode redis 架构演进 src id 性能优化 微服务 db 集群 数据 MQ Mysql数据库 缓存 node 产品 UI 分布式事务 锁 IO 工程师 JVM Hadoop 互联网 系统架构 时间 volatile 文章 bug 索引 测试 压力 配置 需求 开发 加班 一致性 服务注册 服务器 数据库 sql 代码 参数 凌晨 高可用 注册中心 java 事故 zookeeper 管理 滴滴 http 高并发 Spring cloud 部署 spring 双11 大数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

