携程新一代监控告警平台 Hickwall 架构演进
作者简介
陈汉,携程网站运营中心研发工程师,从事Hickwall监控告警平台的研发工作。 经历了Hickwall项目的雏形到交付生产再到不断改进,通过整个开发过程,对监控领域有了深入的了解。喜欢探究系统的底层原理,对分布式有浓厚的兴趣。
本文来自陈汉在“ 2018携程技术峰会 ”上的分享。
监控告警是网站可用性的第一道防线,为网站提供更加实时可靠高效的监控告警,对互联网企业具有非凡的意义。致力于这个目标,经过不断地改进,携程新一代监控告警平台Hickwall在存储效率、查询速度和告警可靠性方面都有了极大的改善。
本文将从存储、聚合、告警三个方面介绍Hickwall在核心架构方面的演进。
一、架构演进概述
为了更好地了解Hickwall在核心架构方面的设计,我们首先将Hickwall第一代的架构和现有架构进行比较。
Hickwall最初的研发是在2015-2016年,当时我们调研了业界知名的开源监控系统。
比如Graphite,拥有非常好的生态,但是集群配置复杂,每个指标都采用一个文件存储,导致小文件多,iowait高,并且使用python实现,性能方面不太令人满意。
再比如OpenTSDB,基于HBase天然就支持分布式,但是也受限于HBase,多维查询的时候性能比较差。而其他的监控系统也并未非常成熟,最后我们决定使用ElasticSearch作为存储引擎。下图是第一代的核心架构图。
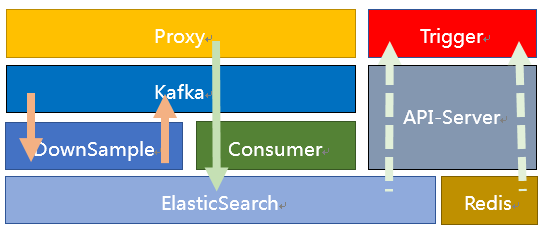
在这个架构中监控数据从Proxy进来,经过格式整理、数据补全、限流后发送到Kafka。Donwsample消费Kafka中的原始数据进行时间维度上的聚合,聚合成5m、15m等时间维度的数据点之后写入到Kafka。Consumer消费Kafka中的原始数据和聚合数据写入到ES,通过API-Server提供统一的接口给看图和告警。
因为ES的查询性能无法满足Trigger高频率的拉取需求,我们另外增加了Redis用来缓存最近一段时间的数据用于告警。这套架构初步实现了监控系统的功能,但是在使用过程中我们也发现以下几个问题:
-
组件过多。运维架构追求的是至简至稳,过多的组件会增加部署和维护的难度。另外在团队人员变动的情况下,新成员进来无法快速上手。
-
数据堆积。Consumer消费Kafka出现问题,容易导致Kafka中数据堆积,用户将无法看到线上系统的当前实时状态,直到将堆积的数据消费完。按照我们的实践经验,数据堆积的时间往往会有几十分钟,这对于互联网企业来讲是个非常大的问题。
-
数据链条过长。监控数据从Proxy进来到Trigger告警需要依次经过6个组件,任何一个组件出现问题,都可能导致告警漏告或误告。
为了解决这些问题,我们研发了Hickwall的第二代架构,使用自研的Influxdb集群取代了ES作为存储引擎,如下图。
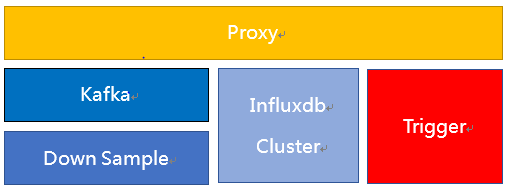
在这个架构中监控数据从Proxy进来分三路转发,第一路发送给Influxdb集群,确保无论发生任何故障,只要Hickwall恢复正常,用户就能立即看到线上系统的当前状态。
第二路发送给Kafka,由Downsample完成数据聚合后将聚合数据直接写入到Influxdb集群。第三路发送给流式告警,这三路数据互不影响,即使存储和聚合都出现问题,告警依然可以正常工作,确保了告警的可靠稳定。
二、Influxdb集群设计
ES用于时间序列存储存在不少问题,例如磁盘使用空间大,磁盘IO使用多,索引维护复杂,写入和查询速度慢等。
而Influxdb是排名第一的时间序列数据库,能针对时间范围进行高效的查询,支持自动删除过时数据,较低的使用和维护成本。 只是早期的Influxdb不够稳定,bug比较多,直到2017年底。我们经过测试确认Influxdb已经足够稳定可以交付生产,就萌生了用Influxdb替换ES的想法。当然Influxdb存在单点问题,在0.12版本以后,官方的集群方案还闭源了。
为了解决Influxdb的单点问题,我们研发了Influxdb的集群方案Incluster,如下图。
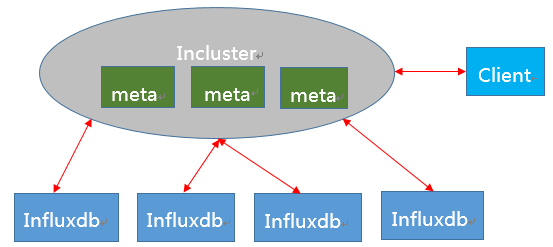
Incluster并没有对Influxdb进行代码侵入式的修改,而是在上层维护关于数据分布和查询的元数据,因此当Influxdb有重大发布的时候Incluster能够及时更新数据节点。
客户端通过Incluster节点写入数据,Incluster按照数据分布策略将写入请求转发到相关的Influxdb节点上,查询的时候按照数据分布策略从各个节点上读取数据并合并查询结果。在元数据这一层Incluster采用raft保证元数据的一致性和分区容错性,在具体数据节点上使用一致性hash保证数据的可用性和分区容错性。
Incluster提供了三种数据分布策略Series、Measurement和Measurement+Tag。通过调整数据分布策略,Incluster能够尽量做到减少数据热点并在查询时减少查询节点。在实践过程中,我们使用Measurement策略来存储系统指标,如CPU;使用Measurement+Appid策略来存储请求量。
作为一个分布式存储,磁盘损坏不可避免,灾备是必须考虑的问题。我们按照数据分布策略通过读取Influxdb底层的TSM数据文件,来恢复损坏的节点上面的数据。实践经验表明Incluster能够做到半个小时恢复一个损坏的节点。
在用户使用方面,Incluster提供了对InfluxQL的透明支持,也提供了类Graphite语法用于配图。类Graphite语法可以简化配图语法,提供InfluxQL无法实现的功能,例如查询最近一段时间变化最剧烈的指标,除此之外还可以屏蔽底层存储细节,以后如果想使用比Influxdb更优秀的时间序列存储引擎,可以减少用户迁移成本。
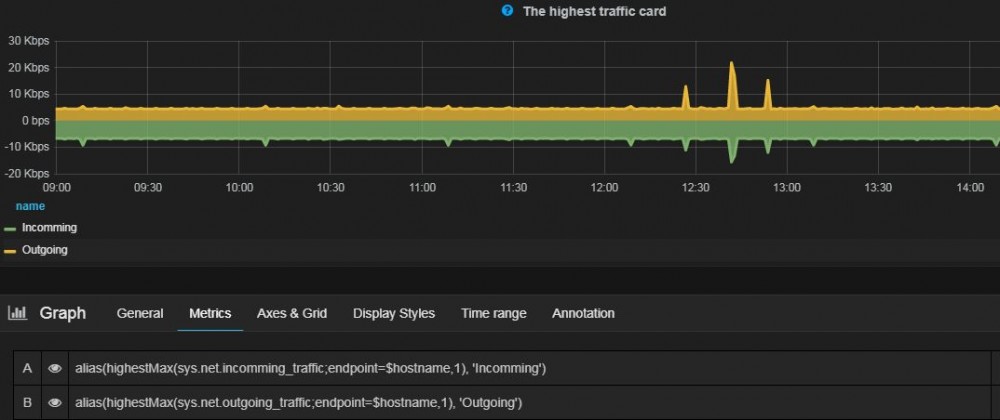
三、数据聚合的探索
Influxdb在数据存储和简单查询方面表现出色,但是在数据聚合上就存在一些问题。
Influxdb提供了Continuous Query Language(CQL)用于数据聚合,但是经过测试发现CQL内存占用较大。Influxdb原本需要的内存就不小,在我们使用过程中128G内存已经使用了一半,如果再加上CQL的内存,容易造成节点不稳定。
另外CQL无法从不同的节点获取数据进行聚合,在Incluster集群方案中存在资源浪费维护复杂的问题。因此我们将数据聚合功能独立出来,在外部进行数据聚合后再将聚合数据写入到Incluster。
时间维度的聚合是有状态的计算,我们面临两个问题。 一个是中间状态如何减少内存的使用,另外一个是节点重启的时候中间状态如何恢复。
我们通过指定每个节点需要消费的Kafka Partition,使得每个节点需要处理的数据可控,避免KafkaPartition Rebalance导致内存不必要的使用,另外通过对Measurement和Tag这些字符串的去重可以减少内存使用。中间状态恢复方面我们并没有使用保存CheckPoint的方法,而是通过提前一段时间消费来恢复中间状态。这种方式避免了保存CheckPoint带来的资源损耗。
业务场景聚合主要的挑战在于一次聚合涉及到的指标数太多,聚合逻辑复杂。例如某个应用的某个接口的请求成功率,涉及到的指标数目上千,这种聚合查询Influxdb无法支持的。
我们的解决方案是使用ClickHouse进行预聚合。ClickHouse是俄罗斯开源的面向OLAP的分布式列式数据库,拥有极高的读写性能,并提供了强大的SQL语言和丰富的数据处理函数,可以完成很多指标的处理,例如P95。
四、流式告警的实现
告警最简单的实现就是定时从数据库中拉取数据,然后检查一下数据是否有异常。但是这种Pull的方式对存储存在一定的压力,尤其是告警规则告警对象众多的时候,对存储的可靠性和响应时间有极高的要求。
我们经过研究发现告警数据在所有监控数据中占比其实不大,以携程为例只占了8%,而且需要的绝大部分都是最近几分钟的数据,如果我们能从数据流中直接获取所需要的数据,就能过滤掉大部分不必要的数据,避免对后台存储的依赖,让告警变得更加可靠实时。
实现流式告警最大的挑战是数据订阅。我们不可能让每一个告警规则都去消费一遍数据流,最好的方式是消费一遍数据流然后将告警数据准确的分发到告警上下文中。
在这里如何降低数据分发的时间复杂度和空间复杂度是最大的难点。
Hickwall的实现思路是减治法,通过Measurement精确匹配减少下一步需要匹配的规则数量,通过tagValue的布隆过滤器判断是哪个Trigger节点需要的数据。Trigger节点收到数据以后对数据点进行精确的匹配过滤,转发到具体的告警上下文中。
这个方案的优势在于时间复杂度不随规则数量告警对象而线性增长,空间复杂度不随tagValue的长度而增长。
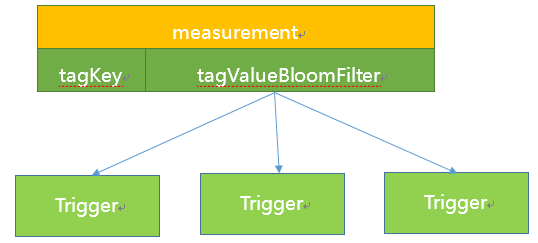
Hickwall使用Akka框架进行告警逻辑和告警数据的处理。Akka是异步高并发的框架,提供了Actor编程模型,能够轻松实现并发地处理数据和执行告警逻辑。
生产系统是个时刻变化的系统,每时每刻都可能有机器上下线,每时每刻都可能有应用发布变更,随着这些变动告警系统需要随之增删告警对象和修改告警阈值。而Actor的创建删除是非常轻量的,为生产系统提供了非常友好的抽象,降低了开发成本。
Hickwall使用了RocksDB来缓存告警数据,通过JNI直接嵌入到Trigger实例中。RocksDB是Facebook开源的KV数据库,基于Google的LevelDB进行了二次开发,底层存储使用LSM Tree,拥有极高的写入速率。
无停滞的处理数据在流式告警中是非常重要的,使用RocksDB能够减少JVM中的对象,减少内存的使用,进而减少了JVM GC的压力。
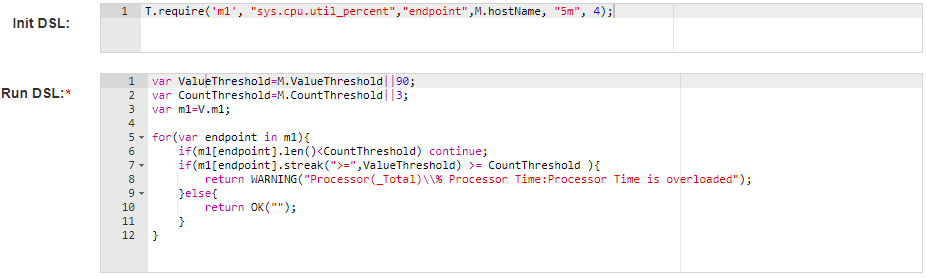
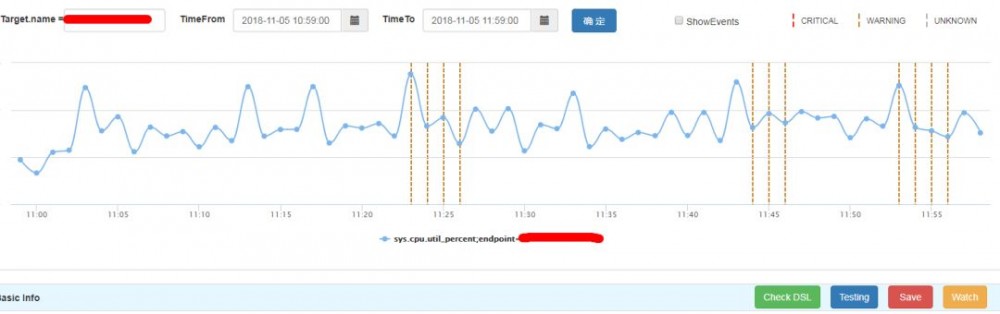
在用户使用方面,Hickwall提供了基于JS语法的DSL语言,Init DSL负责数据的订阅和接收到数据后的处理工作,提供了groupBy、filter、exclude、summarize等流式计算中常见的数据处理函数,Run DSL负责具体的告警逻辑,判断是否有异常。
考虑到DSL书写有一定的难度,Hickwall提供了语法检查、历史数据回测等功能,帮助用户书写出符合需求的告警逻辑。
2018携程技术峰会PPT和视频可见 这里 。
【推荐阅读】
正文到此结束
- 本文标签: 代码 架构演进 http trigger 一致性 限流 数据库 UI Google value 运营 kk 模型 缓存 配置 API 实例 src 2015 Elasticsearch Proxy js sql Facebook App 企业 互联网企业 高并发 存储引擎 https HBase 集群方案 CTO consumer python 分布式 JVM db 集群 NSA 空间 ACE id 索引 部署 测试 网站 时间 开源 排名 MQ 工程师 tag 互联网 redis 需求 开发 删除 IO bug 并发 压力 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

