蜂鸟运单系统架构及实现
运单系统是蜂鸟配送系统核心,支撑着所有配送业务。运单系统需要有很好的扩展性和稳定性,以应对互联网产品千变化万的更新迭代和大流量下的系统稳定。这几年随着蜂鸟业务的不断发展,用户(消费者、商家、骑手、代理商)在产品功能和体验上不断提出新的要求。
蜂鸟每天会有上千万的配送单量,每次上游的呼叫配送请求都会对后台应用发出一系列调用。蜂鸟有多个上游流量入口,包括饿了么商家呼叫蜂鸟配送、第三方平台通过开放平台(open api)接入方式呼叫蜂鸟配送、蜂鸟配送产品跑腿呼叫蜂鸟配送等。上游商户有餐饮类外卖商户,新零售超市、生鲜类商户,零售类淘宝、天猫商户等不同行业商户的配送需求;各个行业不同类型商户对配送的要求各有不同,餐饮类商户配送要求较即时,配送范围一般为商户附近3公里范围内,配送时效要求30分钟左右;零售类商户配送要求小时级,配送范围有超10公里;也有配送要求当天送达,全城配送等。蜂鸟组织代理商、众包和第三方运力完成配送,会根据商户的配送要求,运力系统情况将运单分配给合适运力的骑手配送。且不同配送场景,运单履约过程各有不同,有普通外卖运单的到店、取餐配送,有零售类的前置仓配送,有取送模式的取分离和送分离配送等。一个好的运单系统需要有很好地扩展性和稳定性,运单系统作为物流基础模块需要提前考虑到系统的扩展,为上层各产品系统提供强大的支撑。
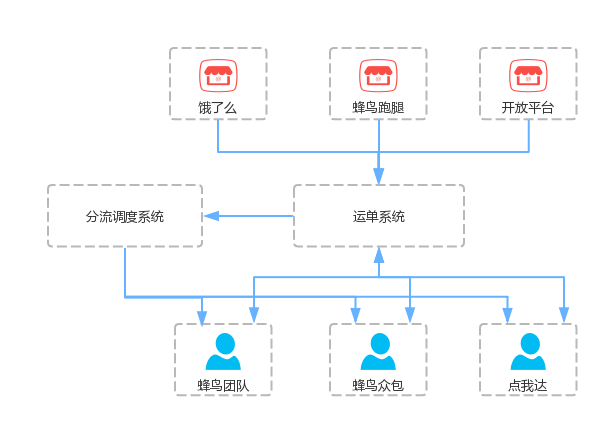
运单系统架构
运单系统核心是数据和状态机,架构上分为流量接入、核心、运力对接、查询、管理等功能模块。运单信息主要包括基础信息、配送信息、状态信息、起/终点信息、费用信息、属性/画像信息等,运单系统负责抽象和定义运单数据结构,如何定义运单数据结构以支撑不同配送业务场景的数据存储是系统设计上的一大难点。运单包括母单和子单,母单跟子单是一对多关系,运单系统根据上游配送请求和相应的唯一标志生成母单,运单履约过程中会根据上游的不同配送要求和实际运力情况动态的生成多段子单以接力模式完成整个配送过程。运单定义标准状态机,根据业务不同,定义不同的状态机跳转,子母单状态互相影响,不支持逆向状态机。
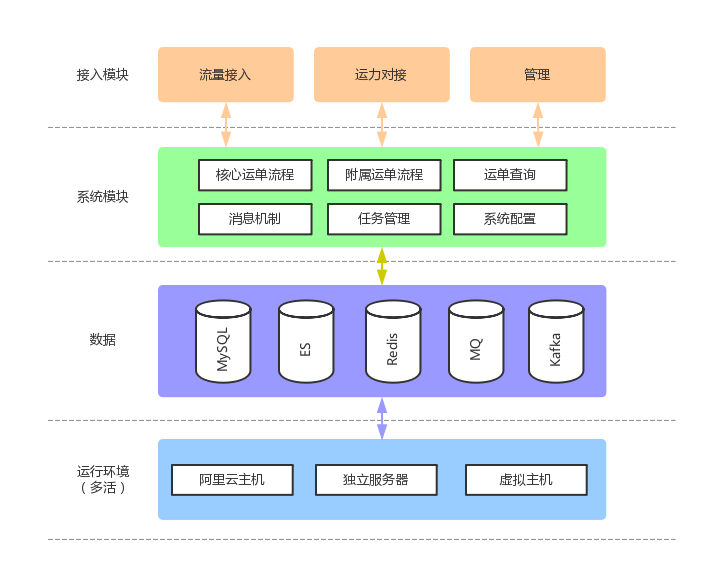
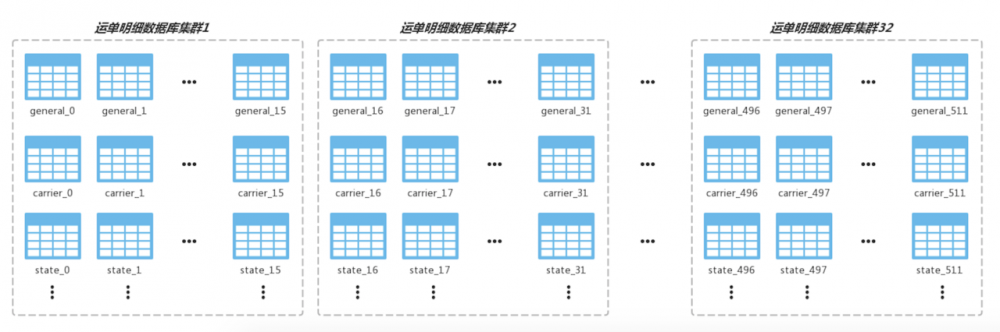
数据存储上运单存储在三种数据介质:Mysql、Redis和ES。Mysql数据分为运单明细数据和运单查询数据,两类数据均以sharding方式存储。因为描述一张运单的信息属性非常多,运单明细数据通过多张表存储,包括运单基本信息表、配送信息表、状态信息表、起/终点信息表、费用信息表、属性/画像信息表等。随着运单系统支持的业务越来越多,业务越来越复杂,运单数据字段又会根据数据的使用场合将公共可结构化的数据作为运单属性存储,业务方特有非公共属性字段数据以KV非结构化形式存储在运单属性数据表中。运单明细数据按物流商户ID作为分区key分为512片存储在32个数据库集群,每个集群一主一备。运单查询数据库存储运单关键ID的mapping关系,用于支持实时的多维查询。Redis按数据块缓存运单明细数据,支持对一致性要求不是特别高的明细数据查询。运单数据还会实时按天索引到ES中,支持复杂的较高,近实时的数据检索和聚合计算。
运单明细数据库按物流商户ID分片,物流商户ID是流量方商户主体在物流侧的映射,为自增ID,所以数据在不同的数据块集群上分布非常均匀。
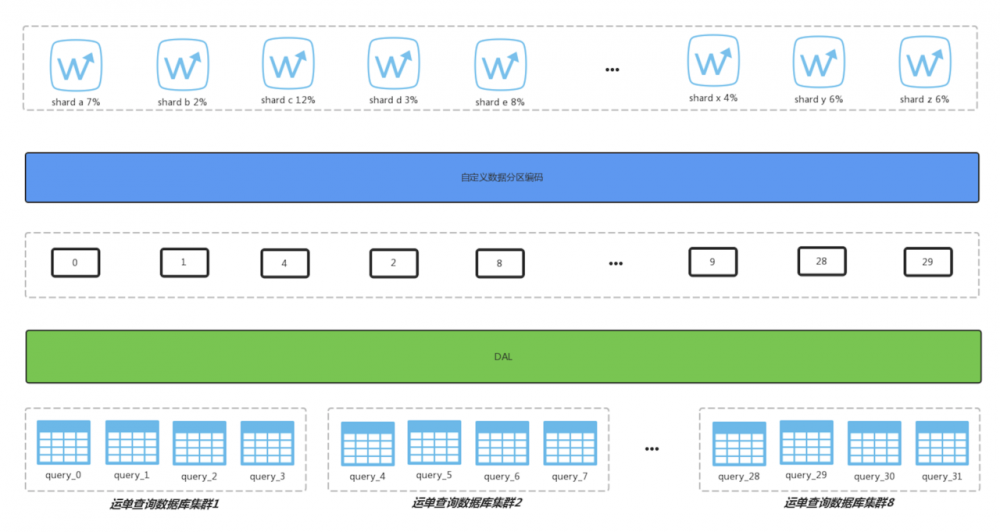
因为蜂鸟即时配送模式下,单笔运单流转有很强的地域特性,从用户下单、到支付、到商家接单、到骑手到店取餐至送达用户,整个运单的流转发生在短短的几十分钟,一个运单的全生命周期基本可确保都发生在同一个shard(饿了么多活地域概念,类似省份)。运单查询数据是按饿了么多活shard进行分片,因为运单有明确的shard信息,且履单过程中涉及到的各个角色都有明确的地域特性,所以不同地域的请求操作会对应到不同的数据块分片。但因为各个shard的业务量各有不同,我们会根据各个shard的业务量占比,自定义shard的分区编码,通过数据库中间件DAL将shard流量映射到不同的数据库集群,尽可能的保证各个集群的数据量均匀。
运单接入
运单接入模块负责跟上游系统对接,将上游配送请求转化成物流运单。运单接入模块是整个物流系统的入口模块,接入模块的稳定关乎整个物流,如何高效稳定地接入流量是该模块设计关键。
运单接入通过异步方式跟上游系统进行对接,上游系统通过接口方式将呼单请求提交至接入模块,接口逻辑只做必要的参数验证,参数验证通过后接入模块会将请求参数记录到数据库并返回成功。因处理呼单请求的业务逻辑非常复杂,涉及多个内外部接口调用,接入模块内部通过线程池异步方式处理呼单请求,通过消息将呼单请求处理结果反馈给上游系统。
设计关键点:
- 幂等:跟上游呼单系统约定请求唯一标识,当同一个呼单请求多次调用时,可通过唯一标识进行幂等处理,避免单子的重复生成。
- 单方面保证原则:跟上游系统约定呼单遵循单方面保证原则,上游保证呼单接口调用成功,呼单模块保证请求处理成功。呼单接口内部逻辑足够简洁,处理逻辑极为简单,当接口内部逻辑出错,返回系统异常给上游系统,上游系统可基于系统异常进行补偿重试,接口调用成功由上游系统保证。在接口逻辑中会保存请求数据,当线程池处理请求出错时,接入模块会有实时任务补偿处理请求任务,可保证呼单请求一定处理成功。
- 预处理:处理请求逻辑非常复杂,需在运单生成前准备好各种运单数据,包括当前运单所在地天气信息、商家用户骑行距离等依赖外部资源数据。外部资源调用一般耗时较大且不稳定,如在处理任务环节实时调用外部系统,非常影响任务处理效率。接入模块一般会基于呼单的前置动作触发呼单的数据预热,将预热好的数据进行缓存,在准备运单数据时从缓存获取即可。如:基于用户的下单动作就开始调用外部服务将天气、距离等信息获取缓存,用户从下单到支付再到商户呼叫物流配送中间时差必是秒级以上,所以预处理有足够的时间将数据预热好。同时,接入模块任务处理逻辑需要做好获取预热数据的降级逻辑。
- 线程池:接入模块曾经尝试过其他异步组件(如:MQ)处理异步任务,都因场景太关键,为减少关键链路上的依赖采用了线程池进行异步处理请求任务。在请求数据写入数据库成功后,会在try catch中尝试往线程池提交一个处理任务,当提交任务失败,直接忽略,接口仍然返回成功,会通过分钟级定时任务将未处理的请求拉起重新处理。通过线程池减少了接口逻辑中对其他消息中间件的外部依赖,纯内存操作,不会因内网、中间件问题等引起主流程阻塞。
- 补偿和隔离:当线程池任务处理慢会导致队列堵塞,队列满了会导致继续提交任务失败。我们增加了每分钟的任务做实时补偿,将超过一定时间未处理的任务重新拉起执行。为避免相互影响,不同的流量呼单会隔离到不同的集群,且补偿任务也发生在单独集群。
主流程抽象
运单中心提供基础的运单业务操作供各个上层系统调用,上游业务系统功能千变万化,运单系统如何做到能快速地支持各业务系统功能快速开发迭代又能保证关键链路的稳定是运单主流程设计的关键。
我们将主流程对运单的操作分为三类:状态类、信息类和属性类。状态类操作是基于运单基础状态机配置依赖方需要的操作,供依赖方操作运单状态。信息类是配置化提供依赖方修改运单信息的能力来修改运单基础属性信息。属性类是提供方便的数据接口,供依赖方回传非公共、非结构化的运单数据。运单通过三种流程抽象,基本可以涵盖大部分运单操作需求,避免频繁定制化需求开发。
运单的业务操作底层是对运单数据进行修改,只是不同的业务动作操作的字段和对应的业务校验不同而已。我们将运单数据修改抽象如下(伪代码)流程:为了防止并发问题,运单在修改数据过程中我们加了分布式锁;在锁内我们获取了运单的最新数据对象,然后copy成old和new两个新的内存对象并存储在threadlocal中;不同的业务逻辑会通过内存操作修改new对象的属性值,业务逻辑修改的是内存运单new对象,此时并未将修改提交至数据库;因为old对象描述的是修改前的运单数据,new对象描述的是业务逻辑修改后的运单数据,我们只需要在内存中compare出两个对象的变化,就能提炼出本次业务逻辑对运单数据的修改;我们基于修改的明细数据以最小事物形式提交至运单基础和查询数据库;同时我们还会触发运单redis缓存的删除,但设置的超时极短,避免影响主流程;最后我们会触发标准的运单topic消息发送。
lock(单号) {
...
1. get and copy
2. 业务逻辑
3. compare
4. db
5. redis
6. MQ
...
}
复制代码
状态类运单流程抽象
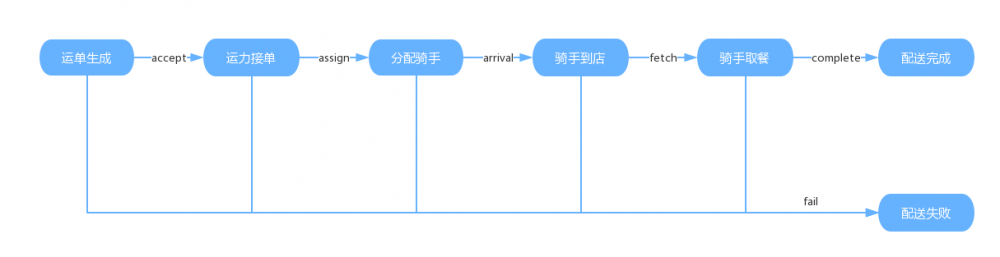
运单基础状态机定义运单最细粒度的可跳转状态,仅允许正向不可跳跃的状态流转。由于业务的多样化,运单不仅需要提供基础的运单状态操作接口,还需要提供同状态或跨越式运单状态操作接口,且需要保证操作的原子性。如骑手端需要支持骑手快速取餐和转单业务,快速取餐业务场景是运单还未分配骑手,骑手直接到店将运单取走进行配送,对于运单需要支持运单状态从待分配骑手到骑手取餐配送中的状态跳转;转单业务是支持骑手间转单,对于运单属于同状态跳转,有可能当前运单是待到店、待取餐或配送中。要支持如上两个业务场景运单基础操作动作无法满足,若业务方自行组装业务逻辑串行调用运单基础操作接口,逻辑上无法保证业务动作的原子性。类似业务场景较多且非常杂,如何做到运单即不理解业务又能支持花式的业务逻辑是状态类运单流程抽象的关键。
首先我们封装了运单的基础操作动作,如:accept()、assign()、arrival()等几个基础的运单操作,每个基础的运单操作都会定义标准的输入、内部业务校验、数据影响。将不同的业务场景抽象成不同的操作code,配置操作code允许的起始状态和终止状态,内部执行时我们会根据基础状态机串行执行基础运单操作,同时我们会merge基础运单操作的参数描述对应到操作code。这样,业务方有不同的业务需求时,我们只需要配置业务操作允许的起终点状态,生成业务操作code和对应的参数描述,通过公共api调用传入对应的操作code和参数即可完成业务调用。
基础运单操作示例:
assign(a, b) {
//业务逻辑
}
arrival(b, c) {
//业务逻辑
}
fetch(b, d) {
//业务逻辑
}
...
复制代码
快速取餐业务操作配置示例:
| 业务操作code | 起点状态列表 | 终点状态列表 | 参数列表 |
|---|---|---|---|
| quick_fetch | [assign] | [fetch] | a,b,c,d |
| ... | [...] | [...] | ... |
代码逻辑执行示例:
state_api(code, orderid, map{a, b, c, d}) {
...
lock(orderid) {
1. get and copy
2.{
assign(a, b);
arrival(b, c);
fetch(b, d);
}
3. compare
4. db
5. redis
6. MQ
}
...
}
复制代码
信息修改类运单流程抽象
运单信息修改类操作主要应对业务场景需要修改运单基础属性信息的需求,如业务场景需要修改用户电话号码或商家经纬度等。运单内部定义运单可修改域对应的基础修改方法和参数描述,业务场景code只需要配置业务操作code跟可修改域之间的关联关系即可,一个业务场景需修改多个数据域只需要关联多个可即可。
属性域基础操作方法示例:
customer(a, b) {
Order.Customer.class.getMethod("setA", Object.class).invoke(new.getCustomer(), a);
Order.Customer.class.getMethod("setB", Object.class).invoke(new.getCustomer(), b);
}
merchant(c, d) {
Order.Merchant.class.getMethod("setC", Object.class).invoke(new.getMerchant(), c);
Order.Merchant.class.getMethod("setD", Object.class).invoke(new.getMerchant(), d);
}
...
复制代码
业务修改操作配置示例:
| 业务操作code | 操作列表 | 参数列表 |
|---|---|---|
| modify_customer | [customer] | a,b |
| modify_merchant | [merchant] | c,d |
| modify_customer_and_merchant | [customer, merchant] | a,b,c,d |
| ... | [...] | ... |
代码逻辑执行示例:
modify_api(code, orderid, map{a, b, c, d}) {
...
lock(orderid) {
1. get and copy
2.{
customer(a, b);
merchant(c, d);
}
3. compare
4. db
5. redis
6. MQ
}
...
}
复制代码
属性类运单流程抽象
运单作为物流履约的数据基础,业务方很多场合依赖运单存储一些个性化数据,我们将这类数据存储在运单的一个单独kv数据块中,以非结构化方式储存。为了防止kv数据种类过多,不被业务方滥用,key由运单侧定义,当需求方需要添加新的key时需要申请,运单侧确认合理性后方可线上使用。另外,由于需求方添加属性场景非常多,我们要求需求方根据业务场景定义key,同时支持追加方式添加key数据,尽可能把一类数据存储在一块,避免kv数据泛滥。同时,我们也会根据数据使用场合在运单查询时结构化部分数据的返回,避免多方使用公共kv数据时各方都需要理解数据结构而进行解析,数据查询篇幅会详细讲解kv数据的查询逻辑。
kv方法示例:
addition(orderid, key, value) {
//add kv
}
append_addition(orderid, key, map/<string, string/>) {
//merge kv
}
...
复制代码
代码逻辑执行示例:
append_addition_api(orderid, key, map{a, b, c, d}) {
...
lock(orderid) {
1. get and copy
2.{
append/_additiont(orderid, key, map{a, b, c, d});
}
3. compare
4. db
5. redis
6. MQ
}
...
}
复制代码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

