HIVE自定义函数的扩展
作者简介
淳敏,物流架构师同时也是一位team leader,工作认真负责,曾在休假期间“面向大海编程”,不明觉厉
在Hive中,用户可以自定义一些函数,用于扩展HiveQL的功能。Hive 自定义函数主要包含以下三种:
- UDF(user-defined function) 单独处理一行,输出也是以行输出。许多Hive内置字符串,数学函数,时间函数都是这种类型。大多数情况下编写对应功能的处理函数就能满足需求。如:concat, split, length ,rand等。这种UDF主要有两种写法:继承实现UDF类和继承GenericUDF类(通用UDF)。
- UDAF(user-defined aggregate function) 用于处理多行数据并形成累加结果。一般配合group by使用。主要用于累加操作,常见的函数有max, min, count, sum,collect_set等。这种UDF主要有两种写法:继承实现 UDAF类和继承实现AbstractGenericUDAFResolver类。
- UDTF(user-defined table function) 处理一行数据产生多行数据或者将一列打成多列。 如explode, 通常配合Lateral View使用,实现列转行的功能。parse_url_tuple将一列转为多列。
Hive的UDF机制是需要用户实现: Resolver 和 Evaluator ,其中 Resolver 就用来处理输入,调用 Evaluator , Evaluator 就是具体功能的实现。
自定义UDF实现和调用机制
Hadoop提供了一个基础类 org.apache.hadoop.hive.ql.exec.UDF ,在这个类中含有了一个 UDFMethodResolver 的接口实现类 DefaultUDFMethodResolver 的对象。
public class UDF {
private UDFMethodResolver rslv;
public UDF() {
this.rslv = new DefaultUDFMethodResolver(this.getClass());
}
......
}
复制代码
在 DefaultUDFMethodResolver 中,提供了一个 getEvalMethod 的方法,从切面调用 UDF 的 evaluate 方法
public class DefaultUDFMethodResolver implements UDFMethodResolver {
private final Class<? extends UDF> udfClass;
public DefaultUDFMethodResolver(Class<? extends UDF> udfClass) {
this.udfClass = udfClass;
}
public Method getEvalMethod(List<TypeInfo> argClasses) throws UDFArgumentException {
return FunctionRegistry.getMethodInternal(this.udfClass, "evaluate", false, argClasses);
}
}
复制代码
自定义UDF的实现上以继承 org.apache.hadoop.hive.ql.exec.UDF 为基础,然后实现一个 evaluate 方法,该方法会被 DefaultUDFMethodResolver 对象执行。
Case Study: 判断坐标点是不是在图形中
public class DAIsContainPoint extends UDF {
public Boolean evaluate(Double longitude, Double latitude, String geojson) {
Boolean isContained = false;
try {
Polygon polygon = JTSHelper.parse(geojson);
Coordinate center = new Coordinate(longitude, latitude);
GeometryFactory factory = new GeometryFactory();
Point point = factory.createPoint(center);
isContained = polygon.contains(point);
}catch (Throwable e){
isContained = false;
}finally {
return isContained;
}
}
}
复制代码
完成了代码定义之后需要对其进行打包,编译成一个 jar ,注意: 最终的 jar 中需要包含所有依赖的 jar , maven 编译上推荐使用 maven-shade-plugin
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
复制代码
最后产生的 jar 文件需要在HIVE SQL中被引用
add jar hdfs://xxx/udf/ff8bd59f-d0a5-4b13-888b-5af239270869/udf.jar; create temporary function is_in_polygon as 'me.ele.breat.hive.udf.DAIsContainPoint'; select lat, lng, geojson, is_in_polygon(lat, lng, geojson) as is_in from example; 复制代码
自定义UDAF和MapReduce
在Hive的聚合计算中,采用MapReduce的方式来加快聚合的速度,而UDAF就是用来撰写聚合类自定义方法的扩展方式。关于MapReduce需要补充知识的请看这里,为了更好的说明白UDAF我们需要知道一下 MapReduce 的流程
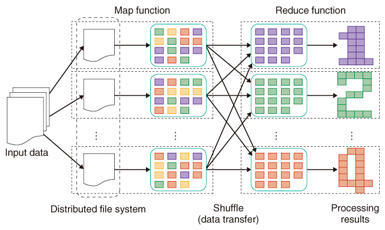
回到Hive中来,在UDAF的实现中,首先需要继承 org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver ,并实现 org.apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver2 接口。然后构造 GenericUDAFEvaluator 类,实现MapReduce的计算过程,其中有3个关键的方法
iterate merge terminate
然后再实现一个继承 AbstractGenericUDAFResolver 的类,重载其 getEvaluator 的方法,返回一个 GenericUDAFEvaluator 的实例
Case Study:合并地理围栏
public class DAJoinV2 extends AbstractGenericUDAFResolver implements GenericUDAFResolver2 {
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo genericUDAFParameterInfo)
throws SemanticException {
return new DAJoinStringEvaluator();
}
public GenericUDAFEvaluator getEvaluator(TypeInfo[] typeInfos) throws SemanticException {
if (typeInfos.length != 1) {
throw new UDFArgumentTypeException(typeInfos.length - 1,
"Exactly one argument is expected.");
}
if (typeInfos[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0,
"Only primitive type arguments are accepted but "
+ typeInfos[0].getTypeName() + " is passed.");
}
switch (((PrimitiveTypeInfo) typeInfos[0]).getPrimitiveCategory()) {
case STRING:
return new DAJoinStringEvaluator();
default:
throw new UDFArgumentTypeException(0,
"Only numeric or string type arguments are accepted but "
+ typeInfos[0].getTypeName() + " is passed.");
}
}
public static class DAJoinStringEvaluator extends GenericUDAFEvaluator {
private PrimitiveObjectInspector mInput;
private Text mResult;
// 存储Geometry join的值的类
static class PolygonAgg implements AggregationBuffer {
Geometry geometry;
}
//定义:UDAF的返回类型,确定了DAJoin自定义UDF的返回类型是Text类型
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
assert (parameters.length == 1);
super.init(m, parameters);
mResult = new Text();
mInput = (PrimitiveObjectInspector) parameters[0];
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
//内存创建,用来存储mapper,combiner,reducer运算过程中的相加总和。
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
PolygonAgg polygonAgg = new PolygonAgg();
reset(polygonAgg);
return polygonAgg;
}
public void reset(AggregationBuffer aggregationBuffer) throws HiveException {
PolygonAgg polygonAgg = (PolygonAgg) aggregationBuffer;
GeometryFactory factory = new GeometryFactory();
polygonAgg.geometry = factory.createPolygon(new Coordinate[]{});
}
//map阶段:获取每个mapper,去进行merge
public void iterate(AggregationBuffer aggregationBuffer, Object[] objects)
throws HiveException {
assert (objects.length == 1);
merge(aggregationBuffer, objects[0]);
}
//在一个子的partial中combiner合并map返回结果
public Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {
return terminate(aggregationBuffer);
}
//combiner合并map返回结果
public void merge(AggregationBuffer aggregationBuffer, Object partial) throws HiveException {
if (partial != null) {
try {
PolygonAgg polygonAgg = (PolygonAgg) aggregationBuffer;
String geoJson = PrimitiveObjectInspectorUtils.getString(partial, mInput);
Polygon polygon = JTSHelper.parse(geoJson);
polygonAgg.geometry = polygonAgg.geometry.union(polygon);
} catch (Exception e){
}
}
}
//reducer合并所有combiner返回结果
public Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {
try {
PolygonAgg polygonAgg = (PolygonAgg) aggregationBuffer;
Geometry buffer = polygonAgg.geometry.buffer(0);
mResult.set(JTSHelper.convert2String(buffer.convexHull()));
return mResult;
}catch (Exception e) {
return "";
}
}
}
}
复制代码
打包之后将其用在HIVE SQL中执行
add jar hdfs://xxx/udf/ff8bd59f-d0a5-4b13-888b-5af239270869/udf.jar; create temporary function da_join as 'me.ele.breat.hive.udf.DAJoinV2'; create table udaf_example as select id, da_join(da_range) as da_union_polygon from example group by id 复制代码
自定义UDTF
在UDTF的实现中,首先需要继承 org.apache.hadoop.hive.ql.udf.generic.GenericUDTF ,实现 process , initialize 和 close 方法
-
initialize返回StructObjectInspector对象,决定最后输出的column的名称和类型 -
process是对每一个输入record进行处理,产生出一个新数组,传递到forward方法中进行处理 -
close关闭整个调用的回调处,清理内存
Case Study: 输入Polygon转成一组S2Cell
public class S2SimpleRegionCoverV2 extends GenericUDTF {
private final static int LEVEL = 16;
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
List<String> structFieldNames = Lists.newArrayList("s2cellid");
List<ObjectInspector> structFieldObjectInspectors = Lists.<ObjectInspector>newArrayList(
PrimitiveObjectInspectorFactory.javaLongObjectInspector);
return ObjectInspectorFactory
.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);
}
@Override
public void process(Object[] objects) throws HiveException {
String json = String.valueOf(objects[0]);
List<Long> s2cellids = toS2CellIds(json);
for (Long s2cellid: s2cellids){
forward(new Long[]{s2cellid});
}
}
public static List<Long> toS2CellIds(String json) {
GeometryFactory factory = new GeometryFactory();
GeoJsonReader reader = new GeoJsonReader();
Geometry geometry = null;
try {
geometry = reader.read(json);
} catch (ParseException e) {
geometry = factory.createPolygon(new Coordinate[]{});
}
List<S2Point> polygonS2Point = new ArrayList<S2Point>();
for (Coordinate coordinate : geometry.getCoordinates()) {
S2LatLng s2LatLng = S2LatLng.fromDegrees(coordinate.y, coordinate.x);
polygonS2Point.add(s2LatLng.toPoint());
}
List<S2Point> points = polygonS2Point;
if (points.size() == 0) {
return Lists.newArrayList();
}
ArrayList<S2CellId> result = new ArrayList<S2CellId>();
S2RegionCoverer
.getSimpleCovering(new S2Polygon(new S2Loop(points)), points.get(0), LEVEL, result);
List<Long> output = new ArrayList<Long>();
for (S2CellId s2CellId : result) {
output.add(s2CellId.id());
}
return output;
}
@Override
public void close() throws HiveException {
}
}
复制代码
在使用的时候和 lateral view 连在一起用
add jar hdfs://bipcluster/data/upload/udf/ff8bd59f-d0a5-4b13-888b-5af239270869/google_s2_udf.jar; create temporary function da_cover as 'me.ele.breat.hive.udf.S2SimpleRegionCoverV2'; drop table if exists temp.cm_s2_id_cover_list; create table temp.cm_s2_id_cover_list as select tb_s2cellid.s2cellid, source.shop_id from ( select geometry, shop_id from example) source lateral view da_cover(geometry) tb_s2cellid as s2cellid; 复制代码
正文到此结束
- 本文标签: https IO UI parse maven src HDFS ArrayList 代码 java value git NIO Region App tab build cat 架构师 Google rmi json struct plugin map CTO Hadoop example Lua IDE 实例 ip mapper sql rand 时间 编译 final js id 数据 Select mina http apr category 需求 apache list
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

