Jackson自定义反序列化Deserializer
在之前的文章里总结过 《Spring中三大JSON框架的使用》 ,里面有提到Jackson的一些基本用法。最近遇到一个问题,就是需要把请求中的字符串进行一个 trim ,下面看一下怎么做。
一、自定义String类型的Deserializer
前面介绍过Jackson的核心就是 ObjectMapper ,通过它来决定反序列化时的一些规则。除了提供的一些 configure 方法来指定基础类型字段的解析规则,还可以通过注册 Module 来指定复杂类型(例如自定义的Class等)的解析规则。下面直接看代码,如何对 String 类型的字段解析后,去除头尾的空格。
@Component
@Primary
public class CustomObjectMapperextends ObjectMapper{
public CustomObjectMapper(){
setPropertyNamingStrategy(PropertyNamingStrategy.SNAKE_CASE);
configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
setSerializationInclusion(JsonInclude.Include.NON_NULL);
// ...省略其他configure代码
SimpleModule module = new SimpleModule();
// 添加一个自定义Deserializer
module.addDeserializer(String.class, new StdScalarDeserializer<String>(String.class) {
@Override
public String deserialize(JsonParser p, DeserializationContext ctxt)
throws IOException, JsonProcessingException {
return p.getValueAsString() == null ? null : p.getValueAsString().trim(); // 去掉头尾空格
}
});
//
this.registerModule(module);
}
}
可以看到,其实非常简单。
二、Deserializer的原理
2.1 deserialize方法的内部实现
看到上面自定义的Deserializer,就会想到一个问题,在没有自定义 String 类型的字段解析前,Jackson也是可以解析字符串类型的字段,自定义的时候也就很简单重写了一个 deserialize 方法,会不会导致解析出现什么其他的错误?
为了解答这个问题,要从Jackson的 Default Deserializer 说起,看下Jackson里面都有哪些 StdDeserializer 。
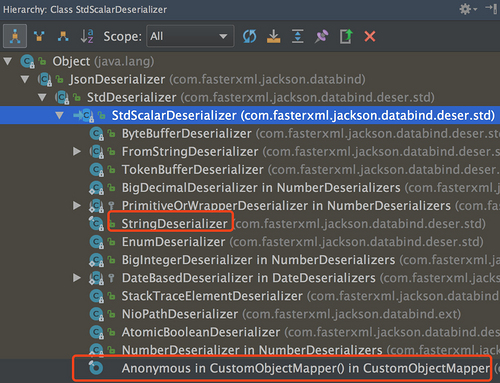
可以看到我们自定义的Deserializer也在最下面。
还是以 String 类型为例,Jackson自带一个 StringDeserializer ,先看一下它是怎么反序列化字符串的,它的 deserialize 方法源码如下( Jackson-2.8.8 )。
@Override
public String deserialize(JsonParser p, DeserializationContext ctxt)throws IOException
{
if (p.hasToken(JsonToken.VALUE_STRING)) {
return p.getText();
}
JsonToken t = p.getCurrentToken();
// [databind#381]
if (t == JsonToken.START_ARRAY) {
return _deserializeFromArray(p, ctxt);
}
// need to gracefully handle byte[] data, as base64
if (t == JsonToken.VALUE_EMBEDDED_OBJECT) {
Object ob = p.getEmbeddedObject();
if (ob == null) {
return null;
}
if (ob instanceof byte[]) {
return ctxt.getBase64Variant().encode((byte[]) ob, false);
}
// otherwise, try conversion using toString()...
return ob.toString();
}
// allow coercions for other scalar types
String text = p.getValueAsString();
if (text != null) {
return text;
}
return (String) ctxt.handleUnexpectedToken(_valueClass, p);
}
可以看到比我们自定义的 deserialize 方法要复杂一些,仔细看会发现,它主要是考虑了多种情况,当传入的原始序列化的数据是一个 JsonToken.VALUE_STRING 时,那就简单的返回一个字符串;当原始的序列化的数据是一个 ARRAY (带有 [] )或者 OBJECT (带有 {} )时,而对应的反序列化的字段又是一个 String 时,它会相应地把 ARRAY 或者 OBJECT 转换成 [...] 或者 {...} 这样的字符串再返回。
所以可以确定的是,我们自定义的 deserialize 方法,在遇到原始数据不是一个简单的 VALUE_STRING 时,会返回 null 。具体在业务中是否可以接受,这个就要看个人需求了,请大家注意这一点。
2.2 如何调用Deserializer
再看一下Jackson是如何决定使用哪一个Deserializer来反序列化数据。简单看一下源代码( 2.8.8版本 ),在 BeanDeserializerFactory.java 中有一个 createBeanDeserializer 方法,这里我不贴代码了,简单说一下逻辑:
- 根据字段的Type(这里是
String),查找CustomBeanDeserializer,如果找到了,那么直接返回。 - 如果没有Custom的
Deserializer,那么就查找StdDeserializer,按照上面贴的Jackson自带的Deserializer,这里就会返回StringDeserializer了。
因此可以确认如果对 String 类型的字段自定义了一个 Deserializer ,那么Jackson便 不再会使用自带的 StringDeserializer 去反序列化数据了。 如果想要确认这一点,在ide里面debug一下,便可证实。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

