Index R 时序数仓技术架构
-
IndexR是由舜飞科技研发的实时OLAP系统。于 2017 年 1 月初正式开源,目前已经更新至 0.6.1 版本,其作者认为IndexR具有以下特点:
-
超大数据集,低查询延时(超大数据集由HDFS保证,查询低延迟由MPP架构的Drill和IndexR专门设计的存储格式保证)
-
准实时 (和Druid实时摄入的思路类似,从Kafka实时摄入数据)
-
高可用,易扩展(架构设计简单,只有一种节点,可以轻易横向扩展)
-
易维护(支持Schema在线更新)
-
SQL支持 (由Drill支持,实际上Drill也是利用Calcite实现的) 与Hadoop生态整合(Hive,Kafka,Spark, Zookeeper, HDFS)
2 IndexR技术架构
- IndexR作为Drill插件嵌入了Drillbit进程,下图是IndexR的服务部署图,可以看到IndexR只是做了优化数据索引的操作。
- Drill是一个类似Presto的MPP数据库,Drillbit是一个类似Presto Work节点的常驻进程,和Hadoop的DN进程混部,可以利用HDFS的短路读的特性。Zookeeper主要用来存储表和segment的一些元信息。IndexR的架构图如下:
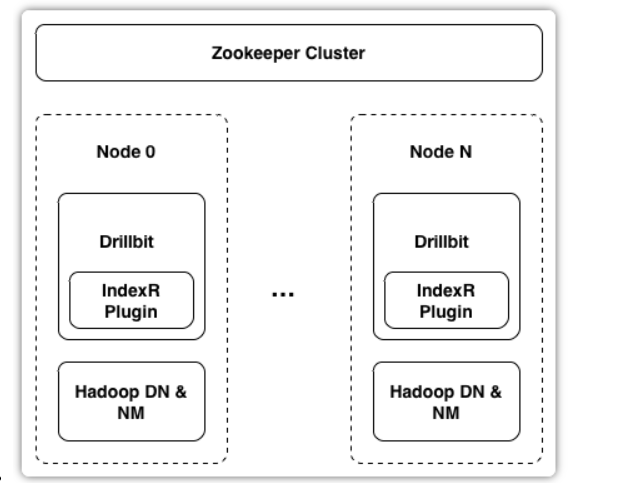
-
IndexR支持从Kafka实时读取数据。IndexR支持通过Drill,Hive,Spark查询数据,不过Hive,Spark只能查询历史数据,Drill可以同时查询实时数据和历史数据。
-
IndexR存储体系
Table:表是对用户可见的概念,用户的查询需要指定Table。 Segment:1个Table由多个Segment组成,Segment自解释,自带索引,是实时数据和离线数据转换的纽带,实时的segment和离线的segment具体结构稍有不同。 Column: IndexR是列式存储的,即某一列的数据会集中存放在一起。某一列的索引和数据是存放在一起的。 Pack: 列数据在内部会进一步细分为Pack,每个Pack有65536行记录,Pack是基本的IO和索引单位。 Row: 表示一行数据。实时数据摄入和离线导入的时候数据都是以行为单位加入一个segment的。 复制代码
-
Segment的元数据包括:行数,列数,每列的MAX和MIN值,每列的name, type,每列的各种索引的偏移量等。
-
Segment 文件由4部分组成:版本号,Segment的元数据,所有Column 和 Pack的倒排索引。
-
一个Column包含多个Pack,每个Pack由DataPackNode,PackRSIndex,PackExtIndex,DataPack4部分组成,但是存储的时候是先存储所有Pack的索引数据,再存储所有Pack的实际数据,这样的好处是可以通过只读取索引文件来快读过滤掉不必要的Pack,来减少随机IO。
3 IndexR适合的经典场景
- 需要在海量数据之上做快速的统计分析查询。
- 要求入库速度非常快,并且需要实时分析。
- 存放超大量历史明细数据库。比如网站浏览信息,交易信息,安保数据,电力行业数据,物联网设备采集数据等。这类数据通常量非常大,数据内容复杂,存放时间比较久,且希望在需要时可以比较快速的根据各种条件做明细查询,或者在一定范围内做复杂的分析。这种情况下可以充分发挥IndexR的低成本,可扩展,适合超大数据集的优势。
- IndexR在开源之后,我们已经看到有不少使用案例,包括国内外的不同团队。有意思的是,有些团队的使用方式比较特别,比如用于存放超大量(单表千亿级别)的复杂明细数据,做历史数据的明细查询。IndexR不仅可以用于多维分析,商业智能等OLAP经典领域,还可以用于物联网,舆情监控,人群行为分析等新兴方向。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

