DOM4J 解析 XML 之忽略转义字符
项目开发需要手动合入几十种语言的翻译到 string.xml 中,这是一件非常痛苦的事情:Copy、Paste,Copy、Paste,Copy、Paste... 人都快疯了!被逼无奈写了个自动替换翻译的工具。原理很简单:解析 Excel中的翻译,替换到 Xml 中。Excel 解析用 jxl.jar,Xml 解析与修改用 DOM,一顿操作,一天就写完了!正高兴呢,赶紧使用 git diff 查看修改对比,一看坏事了:“坑爹呢!一点也不完美啊!原字符串中的转义字符全被转义了好嘛!难道还要手动还回去嘛!像我这样优(懒)秀(惰)的人根本无法容忍好嘛!” 所以,本文记录如何使用 DOM4J(上面不是说用 DOM 解析吗?这里怎么又成 DOM4J 了?忽悠谁呢!) 解析 XML 并让其忽略转义字符。
为什么不用 DOM
谁说我没用 DOM,我一上来就用的 DOM 好嘛!毕竟 JDK 自带的啊!但是用了后,用户体验贼差好嘛!稍微贴下使用方法:
package com.yuloran;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException, TransformerException {
// 1. 解析
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
Document document = documentBuilder.parse(new InputSource(new InputStreamReader(new FileInputStream("strings.xml"), "UTF-8")));
// 2. 遍历
NodeList strings = document.getElementsByTagName("string");
for (int i = 0; i < strings.getLength(); i++) {
Node item = strings.item(i);
System.out.print(String.format("Element:[tag:%s, content:%s] ", item.getNodeName(), item.getTextContent()));
NamedNodeMap attributes = item.getAttributes();
for (int j = 0; j < attributes.getLength(); j++) {
Node attr = attributes.item(j);
System.out.println(String.format("Attr:[key:%s, value:%s]", attr.getNodeName(), attr.getNodeValue()));
}
}
// 3. 保存
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.transform(new DOMSource(document), new StreamResult("strings_copy.xml"));
}
}
复制代码
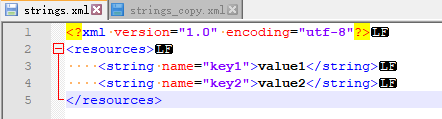
strings.xml:
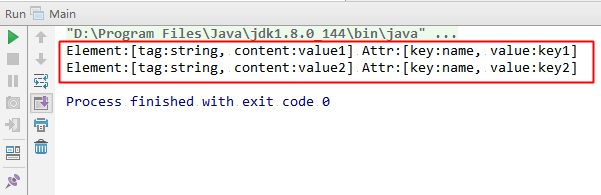
解析日志:
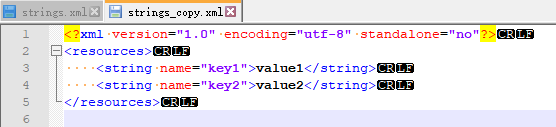
strings_copy.xml:
DOM 解析保存 XML 文件的问题:
document.setXmlStandalone(true);
所以,我不用 DOM,而是用 DOM4J。用了 DOM4J 这些问题都将成为浮云!
DOM4J 解析
太简单啦!直接阅读官方指南即可!我从未见过如此简洁明了的 API 文档!
DOM4J jar 包及依赖下载:
-
点我下载 dom4j-2.1.0.jar
注意看截图:
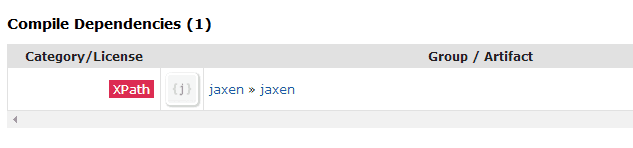
如果工程中 dom4j 是 maven 依赖,就不需要手动下载 jaxen.jar。如果是 jar 依赖,还需要下载 jaxen.jar,否则编译时会找不到类。
-
点我下载 jaxen-1.1.6.jar
DOM4J 使用示例
package com.yuloran;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.xml.sax.InputSource;
import java.io.*;
import java.util.List;
public class Main {
public static void main(String[] args) throws DocumentException, IOException {
// 1. 解析
SAXReader reader = new SAXReader();
Document document = reader.read(new InputSource(new InputStreamReader(new FileInputStream("strings.xml"), "UTF-8")));
// 2. 遍历
List<Node> list = document.selectNodes("/resources/string[@name]");
for (Node node : list) {
System.out.print(String.format("Element:[tag:%s, content:%s] ", node.getName(), node.getText()));
System.out.println(String.format("Attr:[name@%s]", node.valueOf("@name")));
}
// 3.保存
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("strings_dom4j.xml"), "UTF-8");
XMLWriter xmlWriter = new XMLWriter(writer);
// 忽略 Element 对象中的转义字符
xmlWriter.setEscapeText(false);
xmlWriter.write(document);
xmlWriter.close();
}
}
复制代码
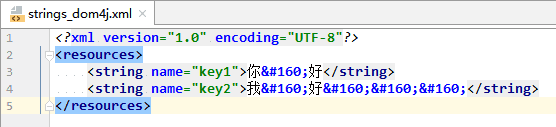
strings_dom4j.xml:
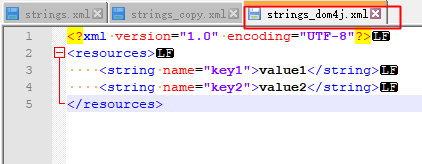
怎么样?看看这输出,一点毛病没有!
忽略转义字符
其实这是 SAX(Simple Application Interface For Xml) 解析的问题,SAX 解析 XML 时,会自动将元素文本中的转义字符转义,导致最后将 Document 对象保存为文件时,无法将原转义字符写回:
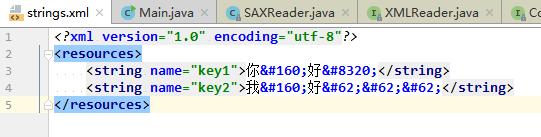
原文件:
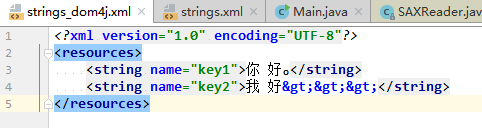
DOM4J 解析再写回:
所以,我们需要实现一个过滤器,每当 SAX 解析一个转义字符,我们就将其原样写回:
reader.setXMLFilter(new XMLFilterImpl() {
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String text = new String(ch, start, length);
System.out.println("text is: " + text);
if (length == 1) {
if ((int) ch[0] == 160) {
char[] escape = " ".toCharArray();
super.characters(escape, 0, escape.length);
return;
}
}
super.characters(ch, start, length);
}
});
复制代码
再配合 xmlWriter.setEscapeText(false); 即可原样输出原 Xml 文件中的转义字符:
// 3.保存
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("strings_dom4j.xml"), "UTF-8");
XMLWriter xmlWriter = new XMLWriter(writer);
xmlWriter.setEscapeText(false);
xmlWriter.write(document);
xmlWriter.close();
复制代码
测试结果:
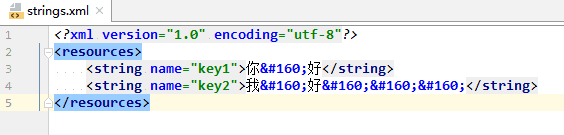
日志:
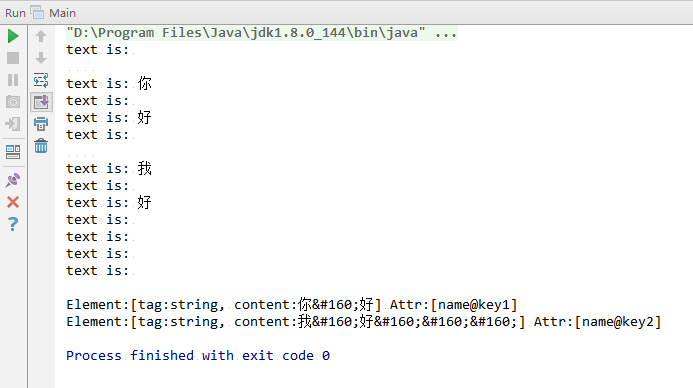
strings_dom4j.xml:
其它的转义字符也是同样的处理方法。可以将要忽略的转义字符放到配置文件中,做工具的时候从配置中读取要忽略的转义字符,这样更灵活。
总结
本文只写了最终的解决方案,实际上探索这个解决方案的过程还是比较复杂的。需求小众,没什么资料,只能看源码,猜接口,反正我是不相信这样的解析框架是没有暴露用户自行处理字符串的接口的。果然还是可以通过 characters() 方法,只是 SAXReader 没有暴露 ContentHandler 接口,内部封装成了 SAXContentHandler,characters() 方法则暴露到了 XMLFilter 接口中,哈,一番好找。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

