Elasticsearch源码分析 | 单节点的启动和关闭
本文主要简要介绍Elasticsearch单节点的启动和关闭流程。Elasticsearch版本:6.3.2
相关文章
1、 Google Guice 快速入门
2、 Elasticsearch 中的 Guice
3、 教你编译调试Elasticsearch 6.3.2源码
4、 Elasticsearch 6.3.2 启动过程
创建节点
Elasticsearch的启动引导类为 Bootstrap 类,在创建节点 Node 对象之前,Bootstrap 会解析配置和进行一些安全检查等
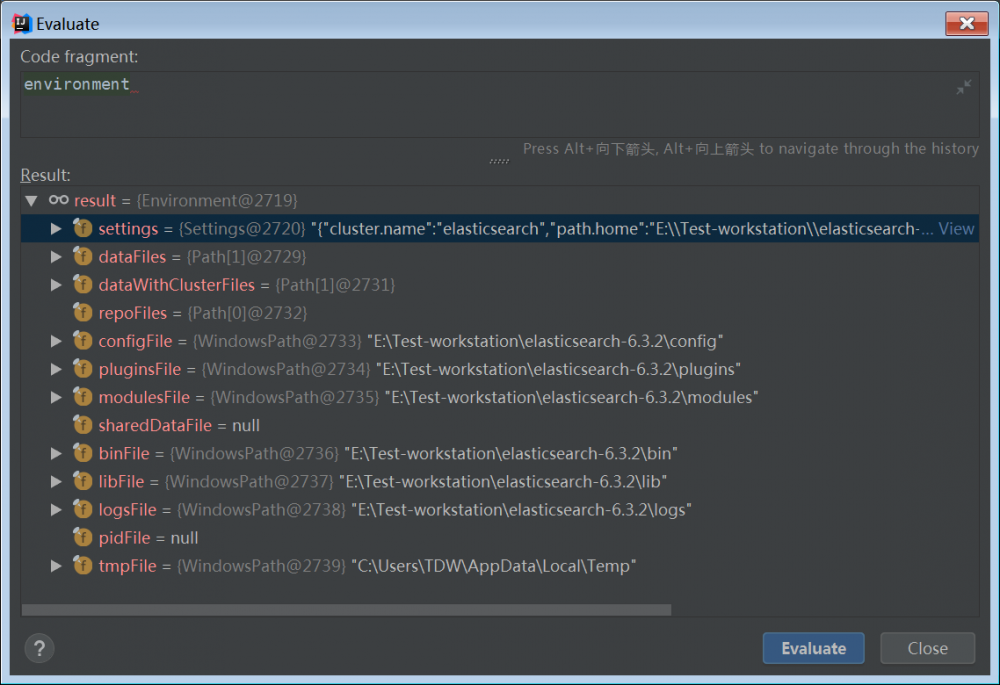
environment 对象主要是解析出来的配置信息
创建节点过程的主要工作是创建各个模块对象和服务对象, 完成 Guice 依赖绑定 ,获取并初始化探测器。
ModulesBuilder 用于统一管理 Module
ModulesBuilder modules = new ModulesBuilder();
ClusterModule clusterModule = new ClusterModule(settings, clusterService, clusterPlugins, clusterInfoService);
modules.add(clusterModule); // 将模块加入管理
//....
// 实例绑定
modules.add(b -> {
b.bind(Node.class).toInstance(this);
b.bind(NodeService.class).toInstance(nodeService);
b.bind(NamedXContentRegistry.class).toInstance(xContentRegistry);
b.bind(PluginsService.class).toInstance(pluginsService);
b.bind(Client.class).toInstance(client);
b.bind(NodeClient.class).toInstance(client);
b.bind(Environment.class).toInstance(this.environment);
b.bind(ThreadPool.class).toInstance(threadPool);
b.bind(NodeEnvironment.class).toInstance(nodeEnvironment);
// ....
}
);
injector = modules.createInjector(); // 生成注入器
主要的服务类简介如下:
| 服务 | 简介 |
|---|---|
| ResourceWatcherService | 通用资源监视服务 |
| HttpServerTransport | HTTP传输服务,提供Rest接口服务 |
| SnapshotsService | 快照服务 |
| SnapshotShardsService | 负责启动和停止shard级快照 |
| IndicesClusterStateService | 根据收到的集群状态信息,处理相关索引 |
| Discovery | 集群拓扑管理 |
| RoutingService | 处理路由(节点之间迁移shard) |
| ClusterService | 集群管理服务,主要处理集群任务,发布集群状态 |
| NodeConnectionsService | 节点连接管理服务 |
| MonitorService | 提供进程级、系统级、文件系统和JVM的监控服务 |
| GatewayService | 负责集群元数据持久化与恢复 |
| SearchService | 处理搜索请求 |
| TransportService | 底层传输服务 |
| plugins | 插件 |
| IndicesService | 负责创建、删除索引等索引操作 |
启动节点
启动节点的主要工作是启动各个模块的服务对象,服务对象从注入器 injector 中取出来,然后调用它们的 start 方法,服务对象的 start 方法的工作基本是初始化内部数据、创建线程池、启动线程池等,详细的流程留到后面的文章中再介绍。
injector.getInstance(MappingUpdatedAction.class).setClient(client); injector.getInstance(IndicesService.class).start(); injector.getInstance(IndicesClusterStateService.class).start();
在启动 Discovery 和 ClusterService 之前,还会调用 validateNodeBeforeAcceptingRequests 方法来检测环境外部,外部环境主要是JVM、操作系统相关参数,将一些影响性能的配置标记为错误以引起用户的重视。
环境检测
节点的环境检测代码都封装在 BootstrapChecks 类中,BootstrapChecks 类通过责任链模式对十几个检测项进行检测,关于责任链模式可以翻看这篇文章《 设计模式之责任链模式及典型应用 》
这里的责任链模式中的抽象处理者由 BootstrapCheck 接口扮演,它定义了一个处理方法 check ,而每个检查项则是具体处理者,都有对应的一个静态类,具体的检查则在 check 接口中完成
以第一个检查项 “堆大小检查” 为例,从 JvmInfo 类中获取配置的堆的初始值和最大值进行比较,不相等则格式化提示信息,最后返回检查结果
static class HeapSizeCheck implements BootstrapCheck {
@Override
public BootstrapCheckResult check(BootstrapContext context) {
final long initialHeapSize = getInitialHeapSize();
final long maxHeapSize = getMaxHeapSize();
if (initialHeapSize != 0 && maxHeapSize != 0 && initialHeapSize != maxHeapSize) {
final String message = String.format(Locale.ROOT,
"initial heap size [%d] not equal to maximum heap size [%d]; " +
"this can cause resize pauses and prevents mlockall from locking the entire heap",
getInitialHeapSize(), getMaxHeapSize());
return BootstrapCheckResult.failure(message);
} else {
return BootstrapCheckResult.success();
}
}
long getInitialHeapSize() {
return JvmInfo.jvmInfo().getConfiguredInitialHeapSize();
}
long getMaxHeapSize() {
return JvmInfo.jvmInfo().getConfiguredMaxHeapSize();
}
}
把所有检查项的对象添加到一个 List 链中
static List<BootstrapCheck> checks() {
final List<BootstrapCheck> checks = new ArrayList<>();
checks.add(new HeapSizeCheck());
final FileDescriptorCheck fileDescriptorCheck
= Constants.MAC_OS_X ? new OsXFileDescriptorCheck() : new FileDescriptorCheck();
checks.add(fileDescriptorCheck);
checks.add(new MlockallCheck());
if (Constants.LINUX) {
checks.add(new MaxNumberOfThreadsCheck());
}
if (Constants.LINUX || Constants.MAC_OS_X) {
checks.add(new MaxSizeVirtualMemoryCheck());
}
if (Constants.LINUX || Constants.MAC_OS_X) {
checks.add(new MaxFileSizeCheck());
}
if (Constants.LINUX) {
checks.add(new MaxMapCountCheck());
}
checks.add(new ClientJvmCheck());
checks.add(new UseSerialGCCheck());
checks.add(new SystemCallFilterCheck());
checks.add(new OnErrorCheck());
checks.add(new OnOutOfMemoryErrorCheck());
checks.add(new EarlyAccessCheck());
checks.add(new G1GCCheck());
checks.add(new AllPermissionCheck());
return Collections.unmodifiableList(checks);
}
for 循环分别调用 check 方法进行检查,有些检查项检查不通过是可以忽略的,如果有不能忽略的错误则会抛出异常
for (final BootstrapCheck check : checks) {
final BootstrapCheck.BootstrapCheckResult result = check.check(context);
if (result.isFailure()) {
if (!(enforceLimits || enforceBootstrapChecks) && !check.alwaysEnforce()) {
ignoredErrors.add(result.getMessage());
} else {
errors.add(result.getMessage());
}
}
}
那么检查项有哪些呢?
-
堆大小检查:如果开启了bootstrap.memory_lock,则JVM在启动时将锁定堆的初始大小,若配置的初始值与最大值不等,堆变化后无法保证堆都锁定在内存中 -
文件描述符检查:ES进程需要非常多的文件描述符,所以须配置系统的文件描述符的最大数量ulimit -n 65535 -
内存锁定检查:ES允许进程只使用物理内存,若使用交换分区可能会带来很多问题,所以最好让ES锁定内存 -
最大线程数检查:ES进程会创建很多线程,这个数最少需2048 -
最大虚拟内存检查 -
最大文件大小检查:段文件和事务日志文件可能会非常大,建议这个数设置为无限 -
虚拟内存区域最大数量检查 -
JVM Client模式检查 -
串行收集检查:ES默认使用 CMS 垃圾回收器,而不是 Serial 收集器 -
系统调用过滤器检查 -
OnError与OnOutOfMemoryError检查 -
Early-access检查:ES最好运行在JVM的稳定版本上 -
G1GC检查
顺便一提,JvmInfo 则是 利用了 JavaSDK 自带的 ManagementFactory 类来获取JVM信息 的,获取的 JVM 属性如下所示
long pid; // 进程ID String version; // Java版本 String vmName; // JVM名称 String vmVersion; // JVM版本 String vmVendor; // JVM开发商 long startTime; // 启动时间 long configuredInitialHeapSize; // 配置的堆的初始值 long configuredMaxHeapSize; // 配置的堆的最大值 Mem mem; // 内存信息 String[] inputArguments; // JVM启动时输入的参数 String bootClassPath; String classPath; Map<String, String> systemProperties; // 系统环境变量 String[] gcCollectors; String[] memoryPools; String onError; String onOutOfMemoryError; String useCompressedOops; String useG1GC; // 是否使用 G1 垃圾回收器 String useSerialGC; // 是否使用 Serial 垃圾回收器
keepAlive 线程
在启动引导类 Bootstrap 的 start 方法中,启动节点之后还会启动一个 keepAlive 线程
private void start() throws NodeValidationException {
node.start();
keepAliveThread.start();
}
// CountDownLatch 初始值为 1
private final CountDownLatch keepAliveLatch = new CountDownLatch(1);
Bootstrap() {
keepAliveThread = new Thread(new Runnable() {
@Override
public void run() {
try {
keepAliveLatch.await(); // 一直等待直到 CountDownLatch 减为 0
} catch (InterruptedException e) {
// bail out
}
}
}, "elasticsearch[keepAlive/" + Version.CURRENT + "]");
keepAliveThread.setDaemon(false); // false 用户线程
// keep this thread alive (non daemon thread) until we shutdown
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
// 当进程收到关闭 SIGTERM 或 SIGINT 信号时,CountDownLatch 减1
keepAliveLatch.countDown();
}
});
}
if (addShutdownHook) {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
try {
IOUtils.close(node, spawner);
LoggerContext context = (LoggerContext) LogManager.getContext(false);
Configurator.shutdown(context);
} catch (IOException ex) {
throw new ElasticsearchException("failed to stop node", ex);
}
}
});
}
keepAliveThread 线程本身不做具体的工作。主线程执行完启动流程后会退出,keepAliveThread 线程是唯一的用户线程, 作用是保持进程运行 。在Java程序中,一个进程至少需要有一个用户线程,当用户线程为零时将退出进程。
做个试验,将 keepAliveThread.setDaemon(false); 中的 false 改为 true ,会发现Elasticsearch启动后马上就停止了
[2019-01-08T01:28:47,522][INFO ][o.e.n.Node ] [1yGidog] started [2019-01-08T01:28:47,525][INFO ][o.e.n.Node ] [1yGidog] stopping ...
关闭节点
关闭的顺序大致为:
- 关闭快照和HTTPServer,不再响应用户REST请求
- 关闭集群拓扑管理,不再响应ping请求
- 关闭网络模块,让节点离线
- 执行各个插件的关闭流程
- 关闭IndicesService,这期间需要等待释放的资源最多,时间最长
public static void close(final Exception ex, final Iterable<? extends Closeable> objects) throws IOException {
Exception firstException = ex;
for (final Closeable object : objects) {
try {
if (object != null) {
object.close();
}
} catch (final IOException | RuntimeException e) {
if (firstException == null) {
firstException = e;
} else {
firstException.addSuppressed(e);
}
}
}
// ...
}
private Node stop() {
if (!lifecycle.moveToStopped()) {
return this;
}
Logger logger = Loggers.getLogger(Node.class, NODE_NAME_SETTING.get(settings));
logger.info("stopping ...");
injector.getInstance(ResourceWatcherService.class).stop();
if (NetworkModule.HTTP_ENABLED.get(settings)) {
injector.getInstance(HttpServerTransport.class).stop();
}
injector.getInstance(SnapshotsService.class).stop();
injector.getInstance(SnapshotShardsService.class).stop();
// stop any changes happening as a result of cluster state changes
injector.getInstance(IndicesClusterStateService.class).stop();
// close discovery early to not react to pings anymore.
// This can confuse other nodes and delay things - mostly if we're the master and we're running tests.
injector.getInstance(Discovery.class).stop();
// we close indices first, so operations won't be allowed on it
injector.getInstance(RoutingService.class).stop();
injector.getInstance(ClusterService.class).stop();
injector.getInstance(NodeConnectionsService.class).stop();
nodeService.getMonitorService().stop();
injector.getInstance(GatewayService.class).stop();
injector.getInstance(SearchService.class).stop();
injector.getInstance(TransportService.class).stop();
pluginLifecycleComponents.forEach(LifecycleComponent::stop);
// we should stop this last since it waits for resources to get released
// if we had scroll searchers etc or recovery going on we wait for to finish.
injector.getInstance(IndicesService.class).stop();
logger.info("stopped");
return this;
}
节点的关闭当然没那么简单。更多细节敬请期待。
参考:
张超.Elasticsearch源码解析与优化实战
后记
欢迎评论、转发、分享,您的支持是我最大的动力
更多内容可访问我的个人博客: http://laijianfeng.org
关注【小旋锋】微信公众号,及时接收博文推送

转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 whirlys@163.com
正文到此结束
- 本文标签: 实例 物理内存 编译 final tar 线程池 UI 时间 IO linux REST 索引 tab src 集群 Bootstrap Action 解析 文件系统 root 锁 Watcher 文章 配置 代码 plugin 插件 Elasticsearch 源码 client cat IDE Transport App 虚拟内存 update 开发 CountDownLatch https 博客 map Google ORM list id classpath build 进程 message 数据 CTO 垃圾回收 java 操作系统 JVM ip 删除 安全 多线程 constant Collections Master 启动过程 Connection 线程 微信公众号 调试 设计模式 Collection rmi 参数 ArrayList node http confuse 管理 Service
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

