中间件(WAS、WMQ)运维 9个常见难点解析
安装
1、was 负载均衡的机制的粘连性,was负载均衡异常?
有一个case系统,部署在was集群环境,应用是集群环境,有的时候当一个节点异常的时,客户端访问该系统就会抛出异常,按正常情况,该会话应该不会断或者断了再连接一次就会到另一个节点,但是好多时候不管客户端如何连接,都不行,该正常的客户端一直是正常的,不正常重启机器也不正常。当然其他新连接的节点也没啥问题,直到重启了故障节点的应用,原先不能正常访问的客户端才正常,就算当时清除浏览器缓存也不好使,哪位有这方面的经验可以多谈谈。
答:
1,这是故障转移,was有内部机制可以做到
1)内存到内存复制技术可以,缺点,因每台服务器共享session,所以占用内存比较大(如果server很少,可以考虑使用)。
2)存储到数据苦或者其他地方也可以实现。推荐使用,但是实现较复杂
2、如何大批量的完成WAS的安装和部署?有哪些工具和方法?
如:几百台或上千台WAS服务器的安装和部署
答:
1,wsadmin 去写脚本是个好办法,配合虚拟化去做。
2,还有上千台的已经不适合去用商业软件了,建议去考虑下开源的软件,或者云平台了。
3、was安装低版本升级需要注意哪些方面?需要重新缴费吗?
答:
1,was 6 官方已经不再提供支持,除非额外买服务。
2,从2018年4月开始,将不再支持Java SE 6 与 WebSphere Application Server 配合使用,建议更新为 Java SE 7 或 8
3,WAS V7.0.x 和 V8.0.x 和 Portal Server V8.0.x 于 April 30, 2018 End Of Service
低版本注意事项:
1,规划好磁盘空间,内存和CPU
2,规划好安装目录,尽量做到安装目录统一,规范。
3,了解好业务量大小,并发等等,方便你设计你的was部署方案。
4,调参数时注意结合实际,并没有完全统一的配置。
5,升级前当然要在测试环境测试后在惊醒生产,JDK版本,及WAS不通版本是有差异的。
巡检
1、针对WAS例行巡检,一般有哪些检查点?每个检查点判断的标准是什么?
例如:巡检WAS,需要检查文件系统、CPU是否高、线程过载、JVM性能、JDBC等方面是否正常。一般以磁盘空间未占满60%,CPU低,未发生线程过载等判断是否存在问题。
答:
1,WAS DM node server的进程状态,was自带状态命令。结合系统命令查看。
2,server的was_home/profiles/node/logs/server下:SystemOut.log SystemErr.log native_stderr.log native_stdout.log
3,was_home/profiles/node/logs/ffdc 日志
4,巡检需要查看JVM 参数设置、线程池参数设置,标准应该参照客户的规范或者以通用参数设置为标准,
5,如果有性能问题时需要查看系统运行情况:内存、CPU,如经常发生的内存泄露问题,有可能是堆内存(heap)或本地内存(native),这经常性的是一个过程性的问题,需要具体分析。
2、该如何分析Javacore(was中间件)
平常的故障中,一般都是需要分析javacore。也是够头疼的了。
一般在得到几个javacore文件之后,就想到可以用IBM Thread and Monitor Dump Analyzer for Java工具去协助分析,不过。。。好像没有找到如何分析的教程,看来很多文章,还是没有头绪。。
我们应该去关注那个Current Thread?还是Thread Detail里面的哪些线程捏?关注Blocked和僵死状态的线程??应该从那个开始着手呀?
答:
不能通过几句话说清楚点,需要知识积累,介绍几个文档:
1,IBM为javacore、GC和heapdump的提供了一个集成工具,叫IBMSupport Assistant
2,http://www-01.ibm.com/support/docview.wss?uid=swg21181068#2.1.1
3,IBMJava626.pdf 这本书去去看看,了解清楚了JVM。
3、我们ERP中WAS版本比较低,JVM设置256-1280,几乎每个月总会有JVM宕机重启发生,这正常吗?
WAS版本5.1。JVM宕机重启原因大多是由于内存溢出导致,曾经试着给堆扩容至2048,仍会有宕机发生,从网上搜了不少资料,有人也建议设置定时重启,这正常吗?不能从根本是杜绝WAS宕机重启吗?
答:
1,首先你需要确认OOM是因为内存不够导致内存溢出还是因为应用代码不规范存在内存泄露。
2,内存也不是越大越好,需要和你你自己的环境。
3,JVM参数配置需要看你OS 平台 32 位有限制,64位理论上来说没有限制,但是考虑到GC时间 最好不要调的过大,而最小JVM内存如果太小则会频繁GC。
4,可以看下应用是否有内存泄露,注意下GC日志,分析下。
监控
1、WAS JVM使用率该如何合理监控?
如果只是监控WAS HEAP USED%,那告警频率太高,如果开启了GC,那么GC频率结合WAS HEAP USED%是否是个好的监控方法?那么GC频率的阀值该如何设置?
答:
这个并没有定论:JVM 堆内存太低会导致GC频繁,而JVM对内存太大,导致GC时间太长,影响应用访问,如果并发又比较大,又存在大对象、处理的数据量又比较大,应用对数据有没有特殊处理,那发生高CPU的问题会很频繁。
所以没有固定值,适合自己系统的需要测试喽!
可以开启详细垃圾回收,然后自己测试GC间隔时长,然后做出判断。
2、针对MQ的监控,一般有哪些指标值得我们去关注?请列举说明
如:MQ的队列深度、日志报错等
答:
MQ巡检一般情况关注三个方面。
1,错误日志。
A)qmgr 错误日志:默认目录 /var/mqm/qmgrs/
最新日志一般记录在AMQERR01.log中,查看该日志判断mq有什么问题。常见报错:AMQ9999通道异常终止错误,AMQ9526消息序列号不一致,AMQ9513达到通道连接数最大值,AMQ9207 收到主机消息无效,还有错误AMQ9206,AMQ9208,AMQ9209等。
除了上述错误,可以把平时运行中常见报错,记录下来,作为日后巡检的参考。
B)mq错误日志: /var/mqm/errors/AMQERR01.log,AMQERR02.log,AMQERR03.log,*FDC文件
这个目录等错误一般和软件运行有关的错误,如果有错误该重点关注,且详细分析每一条错误的原因。FDC文件则是mq软件运行有问题时的堆栈信息,可以通过这个文件判断是否mq本身的bug。
2,MQ运行状态
A)通道的状态,非running的状态都是有问题的。需要结合日志判断通道终止或者binding的原因。
B)队列深度,如果队列深度持续增长,没有下降的趋势需要重点关注。需要查队列增长的原因。不同的队列增长的原因也是不同的。如果是本地队列增长过快,查应用程序为什么没有取走消息。如果是传输队列,可能是通道或者网络有问题,消息无法传输
3,重点关注以下参数配置
A)tcp参数:
修改WebSphere MQ系统配置文件mqs.ini,增加如下一节:TCP:
KeepAlive=Yes
B)修改操作系统的TCP/IP参数:
tcp_keepidle保持TCP/IP连接的时间,单位为0.5秒,缺省值为14,400,即两个小时,我们可将它设为5分钟;
tcp_keepinittcp连接初始timeout值,单位为0.5秒,缺省值为150,我们可将它设为50;
tcp_keepintvl连接间隔,单位为0.5秒,缺省值为150,我们可将它设为50;
/usr/sbin/no -o tcp_keepidle=240 /usr/sbin/no -o tcp_keepinit=50 /usr/sbin/no -o tcp_keepintvl=50
需要注意的一点是通道两端的KeepAlive参数要保持协调一致,若发送端的KeepAlive值小于接收端的KeepAlive值,则当网络出现故障时,发送端的通道停下来之后,接收端的通道会仍然停不下来。
C)使用AdoptNewMCA
通过修改qm.ini文件的Channels一节进行修改,如:Channels:
AdoptNewMCA=ALL
当MQ接收到启动通道的请求,但是同时它发现与该通道对应的amqcrsta的进程已经存在,这时,该进程必须首先被停止,然后,通道才能启动。AdoptNewMCA的作用就是停止这种进程,并且为新的通道启动请求启动一个新的进程。
该属性可以将状态处于running状态的接收端通道强行终止,从而使发送端的通道启动或请求操作得以成功。
如果为某一通道指定了AdoptNewMCA的属性,但是新的通道由于"channel is already running"而启动失败,则它可以:
1) 新的通道通知之前的通道停止
2) 如果旧的通道在AdoptNewMCATimeout的时间间隔内没有接受该停止请求,相应的进程(或线程)被kill掉
3) 如果旧的通道经过步骤2仍未终止,则当第二个AdoptNewMCATimeout时间间隔到达时,MQ终止该通道,同时产生"channelin use"的错误。
D) 设置MaxChannels和MaxActiveChannels属性
MaxChannels和MaxActiveChannels分别代表队列管理器允许配置的通道的最大个数和允许同时运行的通道的个数,MaxChannels的缺省值是100,MaxActiveChannels的缺省值与MaxChannels相同。如果您的并发通道连接个数超过了100,您需要修改这两个参数。这对于大并发的Client/Server间通讯尤为重要。
E)Disconnect interval属性
DisconnectInterval(DISCINT)是发送和服务类型的通道所具有的一个参数,它的作用是:在它设置的时间间隔内,如果传输队列为空即通道上没有消息通过时,通道就会被停止。设置完Disconnect Interval参数之后,当发送方重起通道时,通道就会被正常启动。
Disconnect Interval的值会地影响通道的性能。如果把Disconnect Interval的值设置得非常小,会导致通道的频繁启动;反之,如果把Disconnect Interval的值设置得很大,则意味着即使通道上很长时间没有消息,系统资源也会被长期占用,从而影响系统的性能。因此,利用改变 Disconnect Interval的值,我们可以有效地改善通道的性能。
当传输队列中没有消息要传送时,发送方通道(SDR)、服务器通道(SVR)将在等待了该参数指定的时间间隔后断开连接,停止通道。该参数以秒为单位,定义新的通道时,如果没有特别指定,该参数会继承系统对象的属性,设为6000秒,约两个小时。亦通道连续两个小时没有消息发送后就会停止。DISCINT参数设定为0,通道永远不会停止。(注:有防火墙的不能设为0)
F) Heart Beat Interval属性
与Disconnect Interval(HBINT)相对应的是Heart BeatInterval这一参数(仅针对WebSphere MQ for AIX、HP-UX、OS/2、Sun Solaris、Windows NT/2000 V5.1以上)。它的作用是:在Heart Beat Interval指定的时间间隔内,如果传输队列上没有一直没有消息到达,发送方MCA会向接收方MCA发送一个心跳信号,据此给接收方通道以停止的机会,在这种情况下,它不必等待Disconnect Interval超时,也会将通道停止下来。同时,它会释放用来存贮大消息的内存空间并关闭接收方的队列。
为了使HeartBeat Interval和Disconnect Interval这两个参数更有效地发挥作用,一般情况下需要让Heart Beat Interval设置值小于Disconnect Interval设置值。
另外,如果我们使用的传输协议是TCP/IP,我们也可以利用设置TCP/IP的socket的SO_KEEPALIVE参数来实现这一功能。设置完 SO_KEEPALIVE参数,并设置时间间隔之后,TCP/IP本身就会定期去检测另一端连接的状态,如果对方连接已断开,通道也会被停止。在这里,TCP/IP的时间间隔也应小于WebSphere MQ通道的Disconnect Interval的值。
G) ShortRetry和LongRetry属性
在发送类型等类型的通道属性中,还有四个参数是与通讯恢复和通道连接有关的,它们是:shortrty,shorttmr,longrty,longtmr,它们的缺省值分别是:10,60,999999999,1200,分别代表短 重试时间间隔和次数以及长重试时间间隔和次数,它们的作用和含义在于当通道从running变为retrying状态时,按照这四个参数规定的时间间隔和次数进行通道重新连接的尝试,并且先进行短重试,短重试结束后,再进入长重试。
在设计这四个参数时,要注意以下两点:
1) 要确保短重试+长重试的时间〉故障恢复时间
例如:假设您估计您的系统故障恢复时间为1个小时,则要设置shorttmr(time of shortrty)+longtmr(time of shortrty)>2 hours这样,才能保证在故障恢复之后,通道仍然能够自动进行重新连接的尝试。
2) 重试间隔将影响自动恢复的效率
例如:如果您把短重试总时间设定为10分钟,而长重试时间间隔设为1小时,而网络在15分钟后,便已经恢复,可是此时,由于通道已经进入长重试阶段,它将在 1个小时之后,才能通过长重试恢复通道的正常运行。相反,也不必把重试间隔设置得太短,应根据需要和用户的实际情况进行适中的设置。
H) Batch size属性
通道的Batchsize(BATCHSZ)值是影响通道性能的一个关键参数。在MQ进行消息传输时,通道对消息的处理也是在同步点的控制之下并具有交易特性的,在以下条件满足时,它将统一提交一批消息:
当发送的消息个数达到BATCHSZ时;或传输队列为空,并且在BATCHINT指定的时间间隔内一直没有消息到达时。
缺省情况下,通道的Batchsz是50,这是一个较为合理和优化的设置。一个小的Batch size值会使每条消息占用大的资源。比如,假设我们在局域网的情况下,Batch size值越大,通道的性能越好。然而,在广域网环境下,要根据网络状况的好坏来设置该参数,若网络状况很差,Batch size值越大,可能会导致通道的性能越差。
优化
1、针对MQ和WAS的优化,一般从哪些方面去做,怎样判断性能瓶颈出现在哪里?
如:怎样合理的配置WAS的线程数和JVM的大小?怎么发现和处理性能瓶颈?
答:
MQ:
MQ一般不存在性能问题,对内存和CPU消耗比较少。
一般可以从以下几个方面对MQ进行性能优化:
1,MQ的API中最耗CPU的是MQCONN、MQDISC、MQOPEN和MQCLOSE,尽量避免必要地重复使用,最好做相关的连接池(自己开发这块调用的话),批量消息使用一个MQCOMIT。只发送一条消息时用MQPUT1,性能消耗最小。
2,消息大小最好能少于8K,IBM的人说8K就是一个槛,大于它性能就越来越差。非重要的、不可丢失的消息,使用非持久性,非持久性消息只会在内存中,不会记日志,性能比持久性的消息高10倍。
3,日志分文件系统,/var/mqm/log和/var/mqm分别保存在不同的文件系统中,能提高I/O效率。日志文件尽量最大化,个数最小化,可减少日志文件切换频率,我们生产上好象就是主日志64M,5个。
4,根据自己系统真实情况修改qm.ini中的默认配置,比如说:MaxChannels、MaxActiveChannels和PipeLineLength,当通道连接量大的时候应该改大MaxChannels、MaxActiveChannels。设置MCA采用多个线程的方式来传输消息需修改PipeLineLength
WAS:
1,WAS一般调优的话针对JVM、线程池、DataSource 连接池,
2,参数怎么调,需要根据实际应用去测试
一般初始化调参可以试着设置为以下:
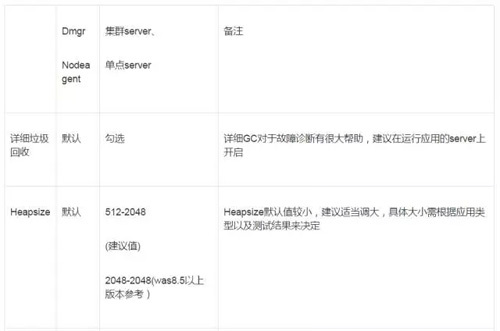

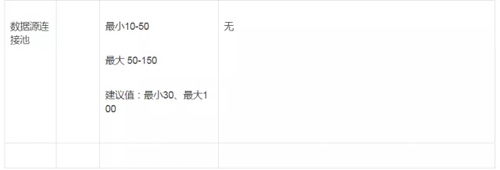
3,需要结合监控数据和实际,去分析系统的瓶颈和优化的方法。
正文到此结束
- 本文标签: https 安装 TCP 开发 core MQ JDBC 测试 ip apr 时间 操作系统 src 垃圾回收 连接池 协议 集群 代码 参数 client IO JVM 服务器 heartbeat cat API 软件 详细分析 Service session 部署 web db 进程 管理 解析 dataSource 线程池 性能优化 并发 java node 线程 数据 App 同步 文章 bug retry 目录 windows UI CTO 开源 http id 测试环境 云 IBM 负载均衡 配置 空间 性能问题 主机 文件系统 缓存 虚拟化 aix
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

