深入了解 Java 的 volatile 关键字
说 volatile 之前,先来聊聊 Java 的内存模型。
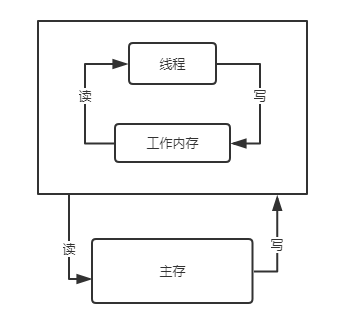
在 Java 内存模型中,规定了所有的变量都是存储在主内存当中,而每个线程都有属于自己的工作内存。线程的工作内存保存了被该内存使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取,赋值等)都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
对于单线程的程序,这样的规定没有任何影响;但是对于多线程的程序,便可能导致,某个线程已经改变了主内存中的变量,而另一个线程还在使用其工作内存中的变量,因此造成了数据的不一致。
二. 可见性
volatile 可以保证数据的可见性,前面说到对于多线程的程序可能会造成数据不一致,但是当一个变量加上 volatile 之后,便可以保证,其他线程读取到的该变量都是最新值。
这是因为每当对该变量进行写操作时,都会使得其他线程工作变量中的该变量的拷贝失效,而迫使线程们都重新去主内存读取
我们来看看实例:
public class TestThread extends Thread {
private volatile boolean isRunning = true;
public void setRunning(boolean running) {
isRunning = running;
}
@Override
public void run() {
int i = 1;
while (isRunning) {
i++;
}
System.out.println(i);
}
}
复制代码
public class Test {
public static void main(String[] args) throws InterruptedException {
TestThread thread = new TestThread ();
thread.start();
Thread.sleep(3000);
thread.setRunning(false);
}
}
复制代码
当 isRunning 变量没有添加 volatile 变量时,该程序会发生死循环,因为 setRunning(false) 并没有影响到 thread 所在线程的工作内存(这时该线程看到的值仍然是 true)
当我们为变量添加上 volatile 之后, setRunning(false) 执行完毕,thread 所在线程的工作内存的变量拷贝便就此作废,必须去主内存获取最新的值,死循环也因此不会再发生了
值得注意的是,当我们在循环中添加了打印语句,或者 sleep 方法等,这时无论有没有 volatile,都会停止循环,如:
while (isRunning) {
i++;
System.out.println(i);
}
复制代码
这是因为,JVM 会尽力保证内存的可见性,原本的代码中,程序一直处于死循环,这时 JVM 没有办法强制要求 CPU 分出时间去保证可见性;但是当加上打印语句之后,CPU 便会分出时间去处理这件事情,并保证了可见性;但是,与之不同的是,volatile 是强制保证可见性的。
三. 原子性
volatile 没有办法保证操作的原子性的
直接上代码:
public class AtomicTest {
private static volatile int race = 0;
private static void increase() {
race++;
}
private static final int THREADS_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
increase();
}
});
threads[i].start();
}
//等待所有累加线程都结束
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(race);
}
}
复制代码
这段代码摘自《深入理解 Java 虚拟机》12 章,当 race 没有 volatile 关键字的加持时,最终的打印结果经常会小于 10000,而有了 volatile,这段程序变不再出现这种情况。
假设两个线程 1 和 2,它们俩先后读取了 race 的值(初始值为 0),由于它们都还没有进行写操作,因此两个线程这时看到的值都是 0,因此便使得之后两次自增操作的结果是 1,而不是 2
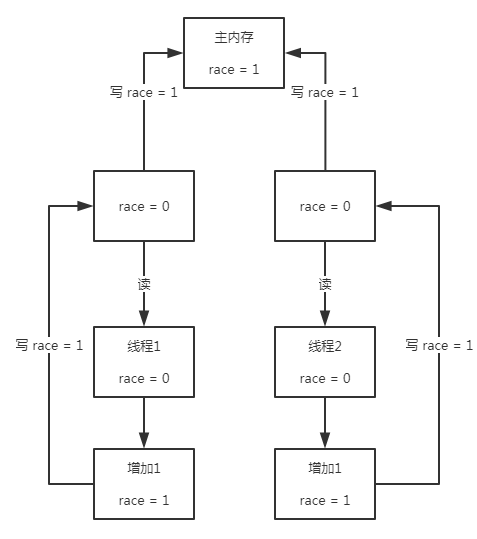
刚刚说到 volatile 变量在进行写操作的时候,会让其他线程对应的工作内存中的拷贝失效,使得需要直接去主存中读取变量,而上例中线程 1 在进行写操作之前,线程 2 便已经执行了读操作,因此没办法影响线程 2 的读取,因此也不会更新为最新的数据了
四. 有序性
volatile 可以在一定程度上禁止指令重排序
//x、y为非volatile变量 //flag为volatile变量 x = 2; //语句1 y = 0; //语句2 flag = true; //语句3 x = 4; //语句4 y = -1; //语句5 复制代码
flag 变量添加上 volatile 关键字以后,语句 1,2 不会排在 3 的后面执行,当然 4,5 也不会在 3 的前面执行
但是 1 和 2, 3 和 4 之间的顺序没办法干预,这也是我们说“一定程度改变”的原因
上个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited){
sleep()
}
doSomethingwithconfig(context); //出错,context 可能还没有初始化
复制代码
面对这样的例子的时候,如果 inited 是非 volatile 变量,那么因为重排序的关系,有可能出错;但是加上 volatile 后便不用担心了
五. 使用场景
1. 状态变量:
比如上面给出的可见性的代码例子
while (isRunning) {
i++;
}
复制代码
对于这种用于标记状态的变量,volatile 是非常好用的
2. 双重检验:
最经典的就是单例模式的双重检验实现,如果忘了的刚好复习一下:
public class Singleton {
private volatile static Singleton singleton;
private Singleton() {
}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
复制代码
这里的 volatile,是为了保证 singleton = new Singleton(); 操作的有序性,因为 singleton = new Singleton(); 并不是原子操作,做了 3 件事
- 给 singleton 分配内存
- 调用 Singleton 的构造函数来初始化成员变量
- 将 singleton 对象指向分配的内存空间(执行完这步 singleton 就为非 null 了)
但是由于重排序的原因,1-2-3 的顺序可能变成 1-3-2,如果是后者,在 singleton 变成非 null 时(即第三步),如果第二个线程开始进入第一个判断 if (singleton == null) ,那么便会直接返回 true,然而事实上 singleton 还没有完成初始化
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

