Java 垃圾回收权威指北
毫无疑问,GC(垃圾回收) 已经是现代编程语言标配,为了研究这个方向之前曾经写过四篇《深入浅出垃圾回收》博文来介绍其理论,之后也看了不少网络上关于 JDK GC 原理、优化的文章,质量参差不齐,其中理解有误的文字以讹传讹,遍布各地,更是把初学者弄的晕头转向。
不仅仅是个人开发者的文章,一些 大厂的官博 也有错误。
本文在实验+阅读 openjdk 源码的基础上,整理出一份相对来说比较靠谱的资料,供大家参考。
预备知识
术语
为方便理解 GC 算法时,需要先介绍一些常见的名词
- mutator,应用程序的线程
- collector,用于进行垃圾回收的线程
- concurrent(并发),指 collector 与 mutator 可以并发执行
- parallel(并行),指 collector 是多线程的,可以利用多核 CPU 工作
- young/old(也称Tenured) 代,根据大多数对象“朝生夕死”的特点,现代 GC 都是分代
一个 gc 算法可以同时具有 concurrent/parallel 的特性,或者只具有一个。
JDK 版本
- HotSpot 1.8.0_172
- openjdk8u (changeset: 2298:1c0d5a15ab4c)
为了方便查看当前版本 JVM 支持的选项,建议配置下面这个 alias
alias jflags='java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version'
然后就可以用 jflags | grep XXX 的方式来定位选项与其默认值了。
打印 GC 信息
-verbose:gc -Xloggc:/data/logs/gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause -XX:+PrintTenuringDistribution -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=50M -XX:+PrintPromotionFailure
JDK 中支持的 GC
Java 8 中默认集成了哪些 GC 实现呢? jflags 可以告诉我们
$ jflags | grep "Use.*GC"
bool UseAdaptiveGCBoundary = false {product}
bool UseAdaptiveSizeDecayMajorGCCost = true {product}
bool UseAdaptiveSizePolicyWithSystemGC = false {product}
bool UseAutoGCSelectPolicy = false {product}
bool UseConcMarkSweepGC = false {product}
bool UseDynamicNumberOfGCThreads = false {product}
bool UseG1GC = false {product}
bool UseGCLogFileRotation = false {product}
bool UseGCOverheadLimit = true {product}
bool UseGCTaskAffinity = false {product}
bool UseMaximumCompactionOnSystemGC = true {product}
bool UseParNewGC = false {product}
bool UseParallelGC = false {product}
bool UseParallelOldGC = false {product}
bool UseSerialGC = false {product}
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
肉眼筛选下,就知道有如下几个相关配置:
- UseSerialGC
- UseParNewGC,
- UseParallelGC
- UseParallelOldGC
- UseConcMarkSweepGC
- UseG1GC
每个配置项都会对应两个 collector ,表示对 young/old 的不同收集方式。而且由于 JVM 不断的演化,不同 collector 的组合方式其实很复杂。而且在 Java 7u4 后,UseParallelGC 与 UseParallelOldGC 其实是等价的,openjdk 中有如下代码:
// hotspot/src/share/vm/runtime/arguments.cpp#set_gc_specific_flags
// Set per-collector flags
if (UseParallelGC || UseParallelOldGC) {
set_parallel_gc_flags();
} else if (UseConcMarkSweepGC) { // Should be done before ParNew check below
set_cms_and_parnew_gc_flags();
} else if (UseParNewGC) { // Skipped if CMS is set above
set_parnew_gc_flags();
} else if (UseG1GC) {
set_g1_gc_flags();
}
我们可以用 下面的代码 测试使用不同配置时,young/old 代默认所使用的 collector:
package gc;
// 省略 import 语句
public class WhichGC {
public static void main(String[] args) {
try {
List<GarbageCollectorMXBean> gcMxBeans = ManagementFactory.getGarbageCollectorMXBeans();
for (GarbageCollectorMXBean gcMxBean : gcMxBeans) {
System.out.println(gcMxBean.getName());
}
} catch (Exception exp) {
System.err.println(exp);
}
}
}
$ java gc.WhichGC # 两个输出分别表示 young/old 代的 collector PS Scavenge PS MarkSweep $ java -XX:+UseSerialGC gc.WhichGC Copy MarkSweepCompact $ java -XX:+UseParNewGC gc.WhichGC # 注意提示 Java HotSpot(TM) 64-Bit Server VM warning: Using the ParNew young collector with the Serial old collector is deprecated and will likely be removed in a future release ParNew MarkSweepCompact $ java -XX:+UseParallelGC gc.WhichGC PS Scavenge PS MarkSweep # 虽然名为 MarkSweep,但其实现是 mark-sweep-compact $ java -XX:+UseParallelOldGC gc.WhichGC # 与上面输出一致,不加 flag 时这样同样的输出 PS Scavenge PS MarkSweep $ java -XX:+UseConcMarkSweepGC gc.WhichGC # ParNew 中 Par 表示 parallel,表明采用并行方式收集 young 代 ParNew ConcurrentMarkSweep # 注意这里没有 compact 过程,也就是说 CMS 的 old 可能会产生碎片 $ java -XX:+UseG1GC gc.WhichGC G1 Young Generation G1 Old Generation
PS 开头的系列 collector 是 Java5u6 开始引入的。按照 R 大的说法 ,这之前的 collector 都是在一个框架内开发的,所以 young/old 代的 collector 可以任意搭配,但 PS 系列与后来的 G1 不是在这个框架内的,所以只能单独使用。
使用 UseSerialGC 时 young 代的 collector 是 Copy,这是单线程的,PS Scavenge 与 ParNew 分别对其并行化,至于这两个并行 young 代 collector 的区别呢?这里再引用 R 大的回复 :
- PS以前是广度优先顺序来遍历对象图的,JDK6的时候改为默认用深度优先顺序遍历,并留有一个UseDepthFirstScavengeOrder参数来选择是用深度还是广度优先。在JDK6u18之后这个参数被去掉,PS变为只用深度优先遍历。ParNew则是一直都只用广度优先顺序来遍历
- PS完整实现了adaptive size policy,而ParNew及“分代式GC框架”内的其它GC都没有实现完(倒不是不能实现,就是麻烦+没人力资源去做)。所以千万千万别在用ParNew+CMS的组合下用UseAdaptiveSizePolicy,请只在使用UseParallelGC或UseParallelOldGC的时候用它。
- 由于在“分代式GC框架”内,ParNew可以跟CMS搭配使用,而ParallelScavenge不能。当时ParNew GC被从Exact VM移植到HotSpot VM的最大原因就是为了跟CMS搭配使用。
- 在PS成为主要的throughput GC之后,它还实现了针对NUMA的优化;而ParNew一直没有得到NUMA优化的实现。
如果你对上面所说的 mark/sweep/compact 这些名词不了解,建议参考下面这篇文章:
- https://plumbr.io/handbook/garbage-collection-algorithms-implementations
其实原理很简单,和我们整理抽屉差不多,找出没用的垃圾,丢出去,然后把剩下的堆一边去。但是别忘了
The evil always comes from details!
怎么定义「没用」?丢垃圾时还允不允许同时向抽屉里放新东西?如果允许放,怎么区别出来,以防止被误丢?抽屉小时,一个人整理还算快,如果抽屉很大,多个人怎么协作?
核心流程指北
ParallelGC
SerialGC 采用的收集方式十分简单,没有并行、并发,一般用在资源有限的设备中。由于其简单,对其也没什么好说的,毕竟也没怎么用过 :-)
ParallelGC 相比之下,使用多线程来回收,这就有些意思了,比如
- 多个GC线程如何实现同步,需要注意一点,ParallelGC 运行时会 STW,因此不存在与 mutator 同步问题
- 回收时,并行度如何选择(也就是 GC 对应用本身的 overhead)
不过比较可惜,cpp 在大二写完几个 console 应用后,就一直没怎么用过了,因为也就没发去探究多个 GC 线程如何实现同步,大略扫一下 parNewGeneration.cpp 这个文件,大概是这样的:
每个 GC 线程对应一个 queue(叫 ObjToScanQueue),然后还支持不同 GC 线程间 steal,保证充分利用 cpu
// ParNewGeneration 构造方法
for (uint i1 = 0; i1 < ParallelGCThreads; i1++) {
ObjToScanQueue *q = new ObjToScanQueue();
guarantee(q != NULL, "work_queue Allocation failure.");
_task_queues->register_queue(i1, q);
}
// do_void 方法
while (true) {
......
// We have no local work, attempt to steal from other threads.
// attempt to steal work from promoted.
if (task_queues()->steal(par_scan_state()->thread_num(),
par_scan_state()->hash_seed(),
obj_to_scan)) {
bool res = work_q->push(obj_to_scan);
assert(res, "Empty queue should have room for a push.");
// if successful, goto Start.
continue;
// try global overflow list.
} else if (par_gen()->take_from_overflow_list(par_scan_state())) {
continue;
}
.......
}
下面还是重点说一下我们开发者能控制的选项,
-
-XX:MaxGCPauseMillis=<N>应用停顿(STW)的的最大时间 -
-XX:GCTimeRatio=<N>GC 时间占整个应用的占比,默认 99。需要注意的是,它是这么用的1/(1+N),即默认 GC 占应用时间 1%。这么说来这个选项的意思貌似正好反了!
其实不仅仅是这个,类似的还有NewRatioSurvivorRatio,喜欢八卦的可以看看 《我可能在跑一个假GC》
当然,上面两个指标是软限制,GC 会采用后面提到的自适应策略(Ergonomics)来调整 young/old 代大小来满足。
Ergonomics
每次 gc 后,会记录一些统计信息,比如 pause time,然后根据这些信息来决定
- 目标是否满足
- 是否需要调整代大小
可以通过 -XX:AdaptiveSizePolicyOutputInterval=N 来打印出每次的调整,N 表示每隔 N 次 GC 打印。
默认情况下,一个代增长或缩小是按照固定百分比,这样有助于达到指定大小。默认增加以 20% 的速率,缩小以 5%。也可以自己设定
-XX:YoungGenerationSizeIncrement=<Y> -XX:TenuredGenerationSizeIncrement=<T> -XX:AdaptiveSizeDecrementScaleFactor=<D> # 如果增长的增量是 X,那么减少的减量则为 X/D
当然,一般情况下是不需要自己设置这三个值的,除非你有明确理由。
使用场景
ParallelGC 另一个名字就表明了它的用途:吞吐量 collector。主要用在对延迟要求低,更看重吞吐量的应用上。
我们公司的数据导入导出、跑报表的定时任务,用的就是这个 GC。(能提供数据导入导出的都是良心公司呀!)
一般利用自适应策略就能满足需求。线上的日志大概这样子:
2018-12-27T22:14:19.006+0800: 5433.841: [GC (Allocation Failure) [PSYoungGen: 606785K->3041K(656896K)] 746943K->143356K(2055168K), 0.0157837 secs] [Times: user=0.03 sys=0.01, real=0.02 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.02 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:21:36.581+0800: 5871.417: [GC (Allocation Failure) [PSYoungGen: 615905K->3089K(654848K)] 756220K->143504K(2053120K), 0.0157796 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:28:51.669+0800: 6306.505: [GC (Allocation Failure) [PSYoungGen: 615953K->3089K(660992K)] 756368K->143664K(2059264K), 0.0178418 secs] [Times: user=0.03 sys=0.01, real=0.02 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:36:17.738+0800: 6752.573: [GC (Allocation Failure) [PSYoungGen: 624145K->2896K(658944K)] 764720K->143576K(2057216K), 0.0144179 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:43:40.208+0800: 7195.043: [GC (Allocation Failure) [PSYoungGen: 623952K->2976K(665088K)] 764632K->143720K(2063360K), 0.0135656 secs] [Times: user=0.03 sys=0.01, real=0.02 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:48:59.110+0800: 7513.945: [GC (Allocation Failure) [PSYoungGen: 632224K->5393K(663040K)] 772968K->146241K(2061312K), 0.0230613 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
2018-12-27T22:54:05.871+0800: 7820.706: [GC (Allocation Failure) [PSYoungGen: 634641K->4785K(669696K)] 775489K->147601K(2067968K), 0.0173448 secs] [Times: user=0.04 sys=0.01, real=0.02 secs]
UseAdaptiveSizePolicy actions to meet *** reduced footprint ***
GC overhead (%)
Young generation: 0.01 (attempted to shrink)
Tenured generation: 0.00 (attempted to shrink)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
CMS
CMS 相比于 ParallelGC,支持并发式的回收,虽然个别环节还是需要 STW,但相比之前已经小了很多;另一点不同是 old 代在 sweep 后,没有 compact 过程,而是通过 freelist 来将空闲地址串起来。CMS 具体流程还是参考下面的文章:
- https://plumbr.io/handbook/garbage-collection-algorithms-implementations/concurrent-mark-and-sweep
上述文章会针对 gc 日志里面的每行含义做解释,务必弄清楚每一个数字含义,这是今后调试优化的基础。网站找了个 比较详细的图 供大家参考:
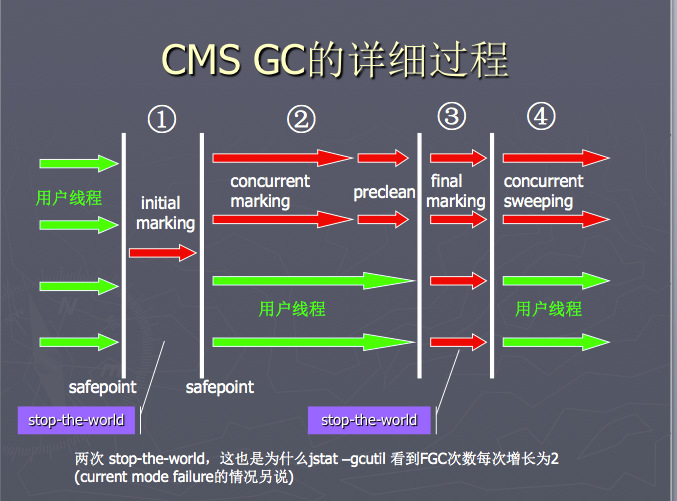
之前在有赞的同事阿杜写过一篇 《不可错过的CMS学习笔记》 推荐大家看看,主要是文章的思路比较欣赏,带着问题去探索。重申下 CMS 的特点:
- CMS 作用于 old 区,与 mutator 并发执行(因为是多线程的,所以也是并行的);默认与 young 代 ParNew 算法一起工作
下面重点说一下 CMS 中误传最广的 CMF 与内存碎片问题。
Concurrent mode failure
在每次 young gc 开始前,collector 都需要确保 old 代有足够的空间来容纳新晋级的对象(通过之前GC的统计估计),如果判断不足,或者当前判断足够,但是真正晋级对象时空间不够了(即发生 Promotion failure),那么就会发生 Concurrent mode failure(后面简写 CMF),CMF 发生时,不一定会进行 Full GC,而是这样的:
如果这时 CMS 会正在运行,则会被中断,然后根据 UseCMSCompactAtFullCollection、CMSFullGCsBeforeCompaction 和当前收集状态去决定后面的行为
有两种选择:
- 使用跟Serial Old GC一样的LISP2算法的mark-compact来做 Full GC,或
- 用CMS自己的mark-sweep来做不并发的(串行的)old generation GC (这种串行的模式在 openjdk 中称为 foreground collector,与此对应,并发模型的 CMS 称为 background collector)
UseCMSCompactAtFullCollection默认为true,CMSFullGCsBeforeCompaction默认是0,这样的组合保证CMS默认不使用foreground collector,而是用Serial Old GC的方式来进行 Full GC,而且在 JDK9 中,彻底去掉了这两个参数以及 foreground GC 模式,具体见: JDK-8010202: Remove CMS foreground collection ,所以这两个参数就不需要再去用了。
这里还需要注意,上述两个备选策略的异同,它们所采用的算法与作用范围均不同:
- Serial Old GC的算法是mark-compact(也可以叫做mark-sweep-compact,但要注意它不是“mark-sweep”)。具体算法名是LISP2。它收集的范围是整个GC堆,包括Java heap的young generation和old generation,以及non-Java heap的permanent generation。因而其名 Full GC
- CMS的foreground collector的算法就是普通的mark-sweep。它收集的范围只是CMS的old generation,而不包括其它generation。因而它在HotSpot VM里不叫做Full GC
解决 CMF 的方式,一般是尽早执行 CMS,可以通过下面两个参数设置:
-XX:CMSInitiatingOccupancyFraction=60 -XX:+UseCMSInitiatingOccupancyOnly
上述两个参数缺一不可,第一个表示 old 区占用量超过 60% 时开始执行 CMS,第二个参数禁用掉 JVM 的自适应策略,如果不设置这个 JVM 可能会忽略第一个参数。
上述关于 CMF 解释主要参考
- R 大的这个帖子
- http://blog.ragozin.info/2011/10/java-cg-hotspots-cms-and-heap.html
- 自己的消耗吸收,如果有误肯定是我的(请留言指出),与 R 大 无关
内存碎片
Promotion failure 一般是由于 heap 内存碎片过多导致检测空间足够,但是真正晋级时却没有足够连续的空间,监控 old 代碎片可以用下面的选项
-XX:+PrintGCDetails -XX:+PrintPromotionFailure -XX:PrintFLSStatistics=1
这时的 gc 日志大致是这样的
592.079: [ParNew (0: promotion failure size = 2698) (promotion failed): 135865K->134943K(138240K), 0.1433555 secs] Statistics for BinaryTreeDictionary: ------------------------------------ Total Free Space: 40115394 Max Chunk Size: 38808526 Number of Blocks: 1360 Av. Block Size: 29496 Tree Height: 22
重点是 Max Chunk Size 这个参数,如果这个值一直在减少,那么说明碎片问题再加剧。解决碎片问题可以按照下面步骤:
- 尽可能提供较大的 old 空间,但是最好不要超过 32G, 超过了就没法用压缩指针了 。
- 尽早执行 CMS,即修改 initiating occupancy 参数
- 减少 PLAB,我具体还没试过,可参考 Java GC, HotSpot’s CMS promotion buffers 这篇文章
- 应用尽量不要去分配巨型对象
调优
说到优化,让很多人望而却步,一方便有人不断在说“不要过早优化”,另一方面在真正有问题时,不知道如何入手。这里说个人的一些经验供大家参考。
既然提到 GC 优化,首先要明确衡量 GC 的几个指标,LinkedIn 在这方面值得借鉴,在 Tuning Java Garbage Collection for Web Services 提出了从 gc 日志中可以获知的 5 个指标:
- Allocation Rate: the size of the young generation divided by the time between young generation collections
- Promotion Rate: the change in usage of the old gen over time (excluding collections)
- Survivor Death Ratio: when looking at a log, the size of survivors in age N divided by the size of survivors in age N-1 in the previous collection
- Old Gen collection times: the total time between a CMS-initial-mark and the next CMS-concurrent-reset. You’ll want both your ‘normal’ and the maximum observed
- Young Gen collection times: both normal and maximum. These are just the “total collection time” entries in the logs Old Gen Buffer:
the promotion rate*the maximum Old Gen collection time*(1 + a little bit)
直接从纯文本的 gc 日志中得出这 5 项指标比较困难,还好有个比较好用的开源工具 gcplot ,借助 docker,一行命令即可启动
docker run -d -p 8080:80 gcplot/gcplot
实战
利用 gcplot,我对公司内部 API 服务进行了一次优化,效果较为明显:
优化前的配置:Xmx/Xms 均为 4G,CMSInitiatingOccupancyFraction=60,下面是使用 gcplot 得到的一些数据
| Percentiles | STW Pause (ms) |
|---|---|
| 50% | 22.203 |
| 90% | 32.872 |
| 95% | 40.255 |
| 99% | 76.724 |
| 99.9% | 317.584 |
- STW Pause per Minute: 3.396 secs
- STW Events per Minute: 133
| Promoted Total | 17.313 GB |
|---|---|
| Promotion Rate (MB/Sec) | 5.99 |
| Allocated Total | 5.053 TB |
| Allocation Rate (MB/Sec) | 1273.73 |
优化后的配置:Xmx/Xms 均为 4G, NewRatio 为 1, CMSInitiatingOccupancyFraction=80。
这么修改主要是增加 young 区空间,因为对于 Web 服务来说,除了一些 cache 外,没什么常驻内存的对象;通过把 OccupancyFraction 调大,延迟 CMS 发生频率,还是基于前面的推论,大多数对象不会晋级到 old 代,所以发生碎片的概率也不会怎么大。下面是优化后的相关参数,也证明了上面的猜想
| percentiles | STW pause(ms) |
|---|---|
| 50% | 19.75 |
| 90% | 30.334 |
| 95% | 35.441 |
| 99% | 53.5 |
| 99.9% | 120.008 |
- STW Pause per Minute: 826.607 ms
- STW Events per Minute: 38
| Promoted Total | 6.182 GB |
|---|---|
| Promotion Rate (MB/Sec) | 0.29 |
| Allocated Total | 28.254 TB |
| Allocation Rate (MB/Sec) | 1121.29 |
参考资料
虽然本文一开始指出 LinkedIn 文章中存在理解误差,但是那篇文章的思路还是值得解决,下面再次给出链接
- https://engineering.linkedin.com/garbage-collection/garbage-collection-optimization-high-throughput-and-low-latency-java-applications
- 段子手王四哥对上面文章的指正: 难道他们说的都是真的?
- 江南白衣的 关键业务系统的JVM参数推荐 ,说到这里就不得不提 vjtools 了,我目前主要用了 vjtop。
总结
上面基本把 ParallelGC 与 CMS 核心点过了一遍,然后顺带介绍了下优化,主要还是熟悉 GC 日志中的每个指标含义,理解透后再去决定是否需要优化。关于 G1 本文没有过多介绍,主要是用的确实不多,后面会尝试把服务升级到 G1 后再来写写它。
本文一开始就说网络上关于 GC 的误解很多,本文可能也是这样的,虽然我已经尽可能保证“正确”,但还是需要大家带着辩证的眼光来看。元芳,你怎么看?
扩展阅读
- https://www.infoq.com/articles/G1-One-Garbage-Collector-To-Rule-Them-All
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html
- https://blogs.oracle.com/jonthecollector/did-you-know
- https://dzone.com/articles/how-tame-java-gc-pauses
- https://mechanical-sympathy.blogspot.com/2013/07/java-garbage-collection-distilled.html
- https://www.oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf
正文到此结束
- 本文标签: HTML id https final UI ask 时间 ORM 构造方法 源码 Collections Oracle 自适应 IDE 文章 初学者 垃圾回收 ip 开发 配置 统计 需求 bean Full GC 测试 Docker grep 同步 数据 ACE App Collection 质量 缩小 网站 src 代码 Service JVM web Select tar 开源 调试 http CTO IO db 参数 cat dist 多线程 Action java 遍历 模型 总结 开发者 ECS 空间 cache 并发 tab list 线程 build API queue
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

