ThreadLocal之深度解读
微信公众号:如有问题或建议,请在下方留言;
最近更新:2019-01-12
前言
继上一篇文章《 Spring Cloud Netflix Zuul源码分析之请求处理篇 》中提到的RequestContext使用的两大神器之一:ThreadLocal,本文特此进行深入分析,为大家扫清知识障碍。
Hello World
在展开深入分析之前,咱们先来看一个官方示例:
出处来源于ThreadLocal类上的注释,其中main方法是笔者加上的。
1import java.util.concurrent.atomic.AtomicInteger;
2
3public class ThreadId {
4 // Atomic integer containing the next thread ID to be assigned
5 private static final AtomicInteger nextId = new AtomicInteger(0);
6
7 // Thread local variable containing each thread's ID
8 private static final ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() {
9 @Override
10 protected Integer initialValue() {
11 return nextId.getAndIncrement();
12 }
13 };
14
15 // Returns the current thread's unique ID, assigning it if necessary
16 public static int get() {
17 return threadId.get();
18 }
19
20 public static void main(String[] args) {
21 for (int i = 0; i < 5; i++) {
22 new Thread(new Runnable() {
23 @Override
24 public void run() {
25 System.out.println("threadName=" + Thread.currentThread().getName() + ",threadId=" + ThreadId.get());
26 }
27 }).start();
28 }
29 }
30}
复制代码
运行结果如下:
1threadName=Thread-0,threadId=0 2threadName=Thread-1,threadId=1 3threadName=Thread-2,threadId=2 4threadName=Thread-3,threadId=3 5threadName=Thread-4,threadId=4 复制代码
我问 :看完这个例子,您知道ThreadLocal是干什么的了吗?
您答 :不知道,没感觉,一个hello world的例子,完全激发不了我的兴趣。
您问 :那个谁,你敢不敢举一个生产级的、工作中真实能用的例子?
我答 :得,您是"爷",您说啥我就做啥。还记得《 Spring Cloud Netflix Zuul源码分析之请求处理篇 》中提到的RequestContext吗?这就是一个生产级的运用啊。Zuul核心原理是什么?就是将请求放入过滤器链中经过一个个过滤器的处理,过滤器之间没有直接的调用关系,处理的结果都是存放在RequestContext里传递的,而这个RequestContext就是一个ThreadLocal类型的对象啊!!!
1public class RequestContext extends ConcurrentHashMap<String, Object> {
2
3 protected static final ThreadLocal<? extends RequestContext> threadLocal = new ThreadLocal<RequestContext>() {
4 @Override
5 protected RequestContext initialValue() {
6 try {
7 return contextClass.newInstance();
8 } catch (Throwable e) {
9 throw new RuntimeException(e);
10 }
11 }
12 };
13
14 public static RequestContext getCurrentContext() {
15 if (testContext != null) return testContext;
16
17 RequestContext context = threadLocal.get();
18 return context;
19 }
20}
复制代码
以Zuul中前置过滤器DebugFilter为例:
1public class DebugFilter extends ZuulFilter {
2
3 @Override
4 public Object run() {
5 // 获取ThreadLocal对象RequestContext
6 RequestContext ctx = RequestContext.getCurrentContext();
7 // 它是一个map,可以放入数据,给后面的过滤器使用
8 ctx.setDebugRouting(true);
9 ctx.setDebugRequest(true);
10 return null;
11 }
12
13}
复制代码
您问 :那说了半天,它到底是什么,有什么用,能不能给个概念?
我答
:能!必须能!!!
What is this
它是啥?它是一个支持泛型的java类啊,抛开里面的静态内部类ThreadLocalMap不说,其实它没几行代码,不信,您自己去看看。它用来干啥?类上注释说的很明白:
- 它能让线程拥有了自己内部独享的变量
- 每一个线程可以通过get、set方法去进行操作
- 可以覆盖initialValue方法指定线程独享的值
- 通常会用来修饰类里private static final的属性,为线程设置一些状态信息,例如user ID或者Transaction ID
- 每一个线程都有一个指向threadLocal实例的弱引用,只要线程一直存活或者该threadLocal实例能被访问到,都不会被垃圾回收清理掉
爱提问的您,一定会有疑惑,demo里只是调用了ThreadLocal.get()方法,它如何实现这伟大的一切呢?这就是笔者下面要讲的内容,走着~~~
我有我的map
话不多说,我们来看get方法内部实现:
get()源码
1public T get() {
2 Thread t = Thread.currentThread();
3 ThreadLocalMap map = getMap(t);
4 if (map != null) {
5 ThreadLocalMap.Entry e = map.getEntry(this);
6 if (e != null) {
7 @SuppressWarnings("unchecked")
8 T result = (T)e.value;
9 return result;
10 }
11 }
12 return setInitialValue();
13}
复制代码
逻辑很简单:
- 获取当前线程内部的ThreadLocalMap
- map存在则获取当前ThreadLocal对应的value值
- map不存在或者找不到value值,则调用setInitialValue,进行初始化
setInitialValue()源码
1private T setInitialValue() {
2 T value = initialValue();
3 Thread t = Thread.currentThread();
4 ThreadLocalMap map = getMap(t);
5 if (map != null)
6 map.set(this, value);
7 else
8 createMap(t, value);
9 return value;
10}
复制代码
逻辑也很简单:
- 调用initialValue方法,获取初始化值【调用者通过覆盖该方法,设置自己的初始化值】
- 获取当前线程内部的ThreadLocalMap
- map存在则把当前ThreadLocal和value添加到map中
- map不存在则创建一个ThreadLocalMap,保存到当前线程内部
时序图
为了便于理解,笔者特地画了一个时序图,请看:
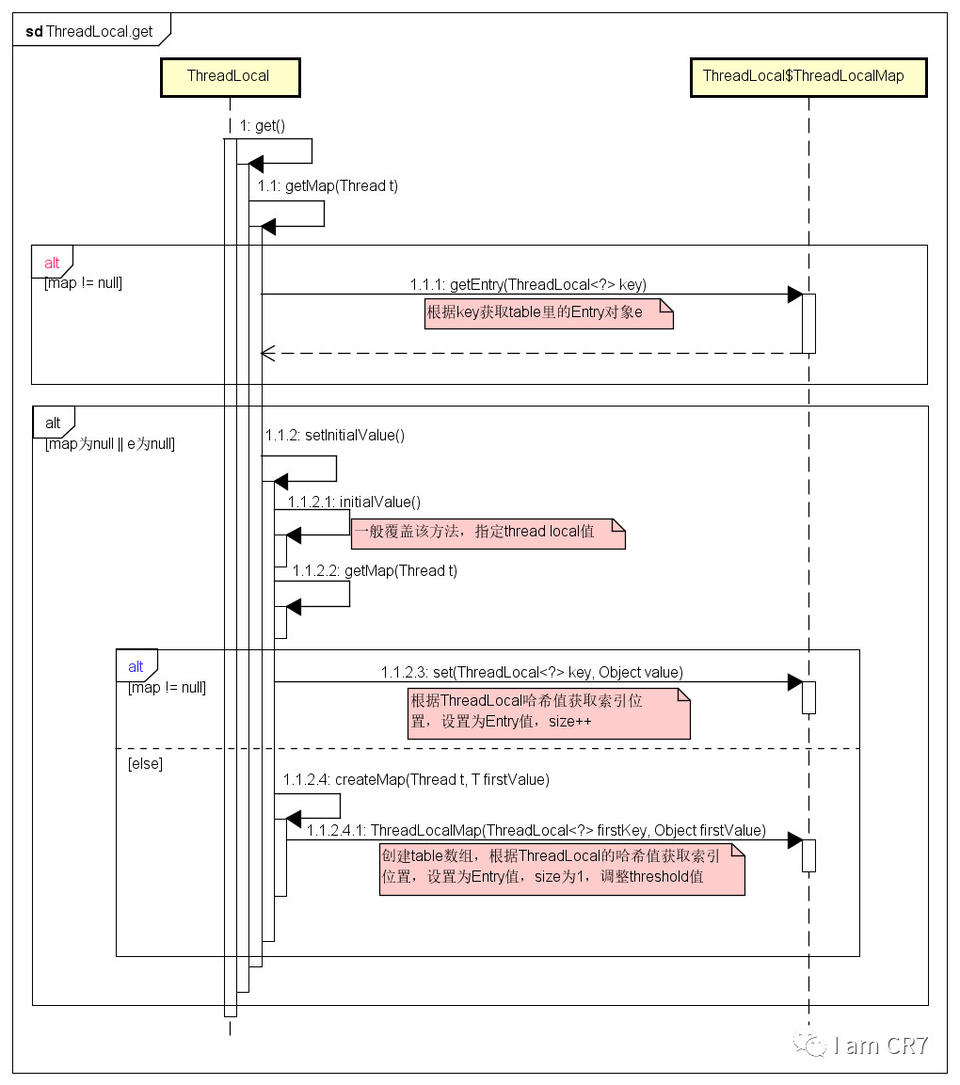
小结
至此,您能回答ThreadLocal的实现原理了吗?没错,map,一个叫做ThreadLocalMap的map,这是关键。每一个线程都有一个私有变量,是ThreadLocalMap类型。当为线程添加ThreadLocal对象时,就是保存到这个map中,所以线程与线程间不会互相干扰。总结起来,一句话:我有我的young,哦,不对,是我有我的map。弄清楚了这些,是不是使用的时候就自信了很多。但是,这是不是就意味着可以大胆的去使用了呢?其实,不尽然,有一个“大坑”在等着你。
神奇的remove
那个“大坑”指的就是因为ThreadLocal使用不当,会引发内存泄露的问题。笔者给出两段示例代码,来说明这个问题。
代码出处来源于Stack Overflow: stackoverflow.com/questions/1…
示例一:
1public class MemoryLeak {
2
3 public static void main(String[] args) {
4 new Thread(new Runnable() {
5 @Override
6 public void run() {
7 for (int i = 0; i < 1000; i++) {
8 TestClass t = new TestClass(i);
9 t.printId();
10 t = null;
11 }
12 }
13 }).start();
14 }
15
16 static class TestClass{
17 private int id;
18 private int[] arr;
19 private ThreadLocal<TestClass> threadLocal;
20 TestClass(int id){
21 this.id = id;
22 arr = new int[1000000];
23 threadLocal = new ThreadLocal<>();
24 threadLocal.set(this);
25 }
26
27 public void printId(){
28 System.out.println(threadLocal.get().id);
29 }
30 }
31}
复制代码
运行结果:
10 21 32 43 5...省略... 6440 7441 8442 9443 10444 11Exception in thread "Thread-0" java.lang.OutOfMemoryError: Java heap space 12 at com.gentlemanqc.MemoryLeak$TestClass.<init>(MemoryLeak.java:33) 13 at com.gentlemanqc.MemoryLeak$1.run(MemoryLeak.java:16) 14 at java.lang.Thread.run(Thread.java:745) 复制代码
对上述代码稍作修改,请看:
1public class MemoryLeak {
2
3 public static void main(String[] args) {
4 new Thread(new Runnable() {
5 @Override
6 public void run() {
7 for (int i = 0; i < 1000; i++) {
8 TestClass t = new TestClass(i);
9 t.printId();
10 t.threadLocal.remove();
11 }
12 }
13 }).start();
14 }
15
16 static class TestClass{
17 private int id;
18 private int[] arr;
19 private ThreadLocal<TestClass> threadLocal;
20 TestClass(int id){
21 this.id = id;
22 arr = new int[1000000];
23 threadLocal = new ThreadLocal<>();
24 threadLocal.set(this);
25 }
26
27 public void printId(){
28 System.out.println(threadLocal.get().id);
29 }
30 }
31}
复制代码
运行结果:
10 21 32 43 5...省略... 6996 7997 8998 9999 复制代码
一个内存泄漏,一个正常完成,对比代码只有一处不同:t = null改为了t.threadLocal.remove();哇,神奇的remove!!!笔者先留个悬念,暂且不去分析原因。我们先来看看上述示例中涉及到的两个方法:set()和remove()。
set(T value)源码
1public void set(T value) {
2 Thread t = Thread.currentThread();
3 ThreadLocalMap map = getMap(t);
4 if (map != null)
5 map.set(this, value);
6 else
7 createMap(t, value);
8}
复制代码
逻辑很简单:
- 获取当前线程内部的ThreadLocalMap
- map存在则把当前ThreadLocal和value添加到map中
- map不存在则创建一个ThreadLocalMap,保存到当前线程内部
remove源码
1public void remove() {
2 ThreadLocalMap m = getMap(Thread.currentThread());
3 if (m != null)
4 m.remove(this);
5}
复制代码
就一句话,获取当前线程内部的ThreadLocalMap,存在则从map中删除这个ThreadLocal对象。
小结
讲到这里,ThreadLocal最常用的四种方法都已经说完了,细心的您是不是已经发现,每一个方法都离不开一个类,那就是ThreadLocalMap。所以,要更好的理解ThreadLocal,就有必要深入的去学习这个map。
无处不在的ThreadLocalMap
还是老规矩,先来看看类上的注释,翻译过来就是这么几点:
- ThreadLocalMap是一个自定义的hash map,专门用来保存线程的thread local变量
- 它的操作仅限于ThreadLocal类中,不对外暴露
- 这个类被用在Thread类的私有变量threadLocals和inheritableThreadLocals上
- 为了能够保存大量且存活时间较长的threadLocal实例,hash table entries采用了WeakReferences作为key的类型
- 一旦hash table运行空间不足时,key为null的entry就会被清理掉
我们来看下类的声明信息:
1static class ThreadLocalMap {
2
3 // hash map中的entry继承自弱引用WeakReference,指向threadLocal对象
4 // 对于key为null的entry,说明不再需要访问,会从table表中清理掉
5 // 这种entry被成为“stale entries”
6 static class Entry extends WeakReference<ThreadLocal<?>> {
7 /** The value associated with this ThreadLocal. */
8 Object value;
9
10 Entry(ThreadLocal<?> k, Object v) {
11 super(k);
12 value = v;
13 }
14 }
15
16 /**
17 * The initial capacity -- MUST be a power of two.
18 */
19 private static final int INITIAL_CAPACITY = 16;
20
21 /**
22 * The table, resized as necessary.
23 * table.length MUST always be a power of two.
24 */
25 private Entry[] table;
26
27 /**
28 * The number of entries in the table.
29 */
30 private int size = 0;
31
32 /**
33 * The next size value at which to resize.
34 */
35 private int threshold; // Default to 0
36
37 /**
38 * Set the resize threshold to maintain at worst a 2/3 load factor.
39 */
40 private void setThreshold(int len) {
41 threshold = len * 2 / 3;
42 }
43
44 /**
45 * Construct a new map initially containing (firstKey, firstValue).
46 * ThreadLocalMaps are constructed lazily, so we only create
47 * one when we have at least one entry to put in it.
48 */
49 ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
50 table = new Entry[INITIAL_CAPACITY];
51 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
52 table[i] = new Entry(firstKey, firstValue);
53 size = 1;
54 setThreshold(INITIAL_CAPACITY);
55 }
56}
复制代码
当创建一个ThreadLocalMap时,实际上内部是构建了一个Entry类型的数组,初始化大小为16,阈值threshold为数组长度的2/3,Entry类型为WeakReference,有一个弱引用指向ThreadLocal对象。
为什么Entry采用WeakReference类型?
Java垃圾回收时,看一个对象需不需要回收,就是看这个对象是否可达。什么是可达,就是能不能通过引用去访问到这个对象。(当然,垃圾回收的策略远比这个复杂,这里为了便于理解,简单给大家说一下)。
jdk1.2以后,引用就被分为四种类型:强引用、弱引用、软引用和虚引用。强引用就是我们常用的Object obj = new Object(),obj就是一个强引用,指向了对象内存空间。当内存空间不足时,Java垃圾回收程序发现对象有一个强引用,宁愿抛出OutofMemory错误,也不会去回收一个强引用的内存空间。而弱引用,即WeakReference,意思就是当一个对象只有弱引用指向它时,垃圾回收器不管当前内存是否足够,都会进行回收。反过来说,这个对象是否要被垃圾回收掉,取决于是否有强引用指向。ThreadLocalMap这么做,是不想因为自己存储了ThreadLocal对象,而影响到它的垃圾回收,而是把这个主动权完全交给了调用方,一旦调用方不想使用,设置ThreadLocal对象为null,内存就可以被回收掉。
内存溢出问题解答
至此,该做的铺垫都已经完成了,此时,我们可以来看看上面那个内存泄漏的例子。示例中执行一次for循环里的代码后,对应的内存状态:
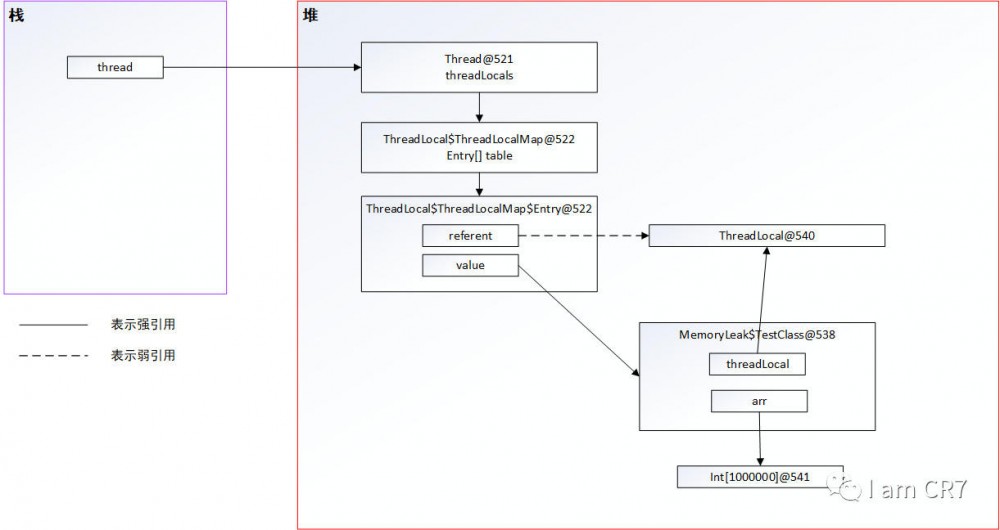
- t为创建TestClass对象返回的引用,临时变量,在一次for循环后就执行出栈了
- thread为创建Thread对象返回的引用,run方法在执行过程中,暂时不会执行出栈
调用t=null后,虽然无法再通过t访问内存地址MemoryLeak
1不能识别此Latex公式: 2TestClass@538,但是当前线程依旧存活,可以通过thread指向的内存地址,访问到Thread对象,从而访问到ThreadLocalMap对象,访问到value指向的内存空间,访问到arr指向的内存空间,从而导致Java垃圾回收并不会回收int[1000000]@541这一片空间。那么随着循环多次之后,不被回收的堆空间越来越大,最后抛出java.lang.OutOfMemoryError: Java heap space。 3 4您问:那为什么调用t.threadLocal.remove()就可以呢? 5 6我答:这就得看remove方法里究竟做了什么了,请看: 7
image
8 是不是恍然大悟?来看下调用 remove 方法之后的内存状态:
9
image
10 因为 remove 方法将referent和 value 都被设置为 null ,所以ThreadLocal@ 540 和Memory
复制代码
TestClass@538对应的内存地址都变成不可达,Java垃圾回收自然就会回收这片内存,从而不会出现内存泄漏的错误。
小结
呼应文章开头提到的《 Spring Cloud Netflix Zuul源码分析之请求处理篇 》,其中就有一个非常重要的类:ZuulServlet,它就是典型的ThreadLocal在实际场景中的运用案例。请看:
1public void service(javax.servlet.ServletRequest servletRequest, javax.servlet.ServletResponse servletResponse) throws ServletException, IOException {
2 try {
3 init((HttpServletRequest) servletRequest, (HttpServletResponse) servletResponse);
4 RequestContext context = RequestContext.getCurrentContext();
5 context.setZuulEngineRan();
6
7 try {
8 preRoute();
9 } catch (ZuulException e) {
10 error(e);
11 postRoute();
12 return;
13 }
14 try {
15 route();
16 } catch (ZuulException e) {
17 error(e);
18 postRoute();
19 return;
20 }
21 try {
22 postRoute();
23 } catch (ZuulException e) {
24 error(e);
25 return;
26 }
27
28 } catch (Throwable e) {
29 error(new ZuulException(e, 500, "UNHANDLED_EXCEPTION_" + e.getClass().getName()));
30 } finally {
31 RequestContext.getCurrentContext().unset();
32 }
33}
复制代码
您有没有发现,一次HTTP请求经由前置过滤器、路由过滤器、后置过滤器处理完成之后,都会调用一个方法,没错,就是在finally里,RequestContext.getCurrentContext().unset()。走进RequestContext一看:
1public void unset() {
2 threadLocal.remove();
3}
复制代码
看到没有,神器的remove又出现了。讲到这里,您是否get到ThreadLocal正确的使用"姿势"呢?
ThreadLocalMap之番外篇
笔者之前写过关于TreeMap和HashMap的文章,凡是Map的实现,都有自己降低哈希冲突和解决哈希冲突的方法。在这里,ThreadLocalMap是如何处理的呢?请往下看。
如何降低哈希冲突
回顾ThreadLocalMap添加元素的源码:
- 方式一:构造方法
1ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
2 table = new Entry[INITIAL_CAPACITY];
3 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
4 table[i] = new Entry(firstKey, firstValue);
5 size = 1;
6 setThreshold(INITIAL_CAPACITY);
7}
复制代码
- 方式二:set方法
1private void set(ThreadLocal<?> key, Object value) {
2
3 Entry[] tab = table;
4 int len = tab.length;
5 int i = key.threadLocalHashCode & (len-1);
6
7 for (Entry e = tab[i];
8 e != null;
9 e = tab[i = nextIndex(i, len)]) {
10 ThreadLocal<?> k = e.get();
11
12 if (k == key) {
13 e.value = value;
14 return;
15 }
16
17 if (k == null) {
18 replaceStaleEntry(key, value, i);
19 return;
20 }
21 }
22
23 tab[i] = new Entry(key, value);
24 int sz = ++size;
25 if (!cleanSomeSlots(i, sz) && sz >= threshold)
26 rehash();
27}
复制代码
其中i就是ThreadLocal在ThreadLocalMap中存放的索引,计算方式为:key.threadLocalHashCode & (len-1)。我们先来看threadLocalHashCode是什么?
1private final int threadLocalHashCode = nextHashCode(); 复制代码
也就是说,每一个ThreadLocal都会根据nextHashCode生成一个int值,作为哈希值,然后根据这个哈希值&(数组长度-1),从而获取到哈希值的低N位(以len为16,16-1保证低四位都是1,从而获取哈希值本身的低四位值),从而获取到在数组中的索引位置。那它是如何降低哈希冲突的呢?玄机就在于这个nextHashCode方法。
1private static AtomicInteger nextHashCode = new AtomicInteger();
2
3private static final int HASH_INCREMENT = 0x61c88647;
4
5private static int nextHashCode() {
6 return nextHashCode.getAndAdd(HASH_INCREMENT);
7}
复制代码
0x61c88647是什么?转化为十进制是1640531527。2654435769转换成int类型就是-1640531527。2654435769等于(根号5-1)/2乘以2的32次方。(根号5-1)/2是什么?是黄金分割数,近似为0.618。也就是说0x61c88647理解为一个黄金分割数乘以2的32次方。有什么好处?它可以神奇的保证nextHashCode生成的哈希值,均匀的分布在2的幂次方上,且小于2的32次方。来看例子:
1public class ThreadLocalHashCodeTest {
2
3 private static AtomicInteger nextHashCode =
4 new AtomicInteger();
5
6 private static final int HASH_INCREMENT = 0x61c88647;
7
8 private static int nextHashCode() {
9 return nextHashCode.getAndAdd(HASH_INCREMENT);
10 }
11
12 public static void main(String[] args){
13 for (int i = 0; i < 16; i++) {
14 System.out.print(nextHashCode() & 15);
15 System.out.print(" ");
16 }
17 System.out.println();
18 for (int i = 0; i < 32; i++) {
19 System.out.print(nextHashCode() & 31);
20 System.out.print(" ");
21 }
22 System.out.println();
23 for (int i = 0; i < 64; i++) {
24 System.out.print(nextHashCode() & 63);
25 System.out.print(" ");
26 }
27 }
28}
复制代码
输出结果:
10 7 14 5 12 3 10 1 8 15 6 13 4 11 2 9 216 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0 7 14 21 28 3 10 17 24 31 6 13 20 27 2 9 316 23 30 37 44 51 58 1 8 15 22 29 36 43 50 57 0 7 14 21 28 35 42 49 56 63 6 13 20 27 34 41 48 55 62 5 12 19 26 33 40 47 54 61 4 11 18 25 32 39 46 53 60 3 10 17 24 31 38 45 52 59 2 9 复制代码
看见没有,元素索引值完美的散列在数组当中,并没有出现冲突。
如何解决哈希冲突
ThreadLocalMap采用黄金分割数的方式,大大降低了哈希冲突的情况,但是这种情况还是存在的,那如果出现,它是怎么解决的呢?请看:
1private void set(ThreadLocal<?> key, Object value) {
2
3 Entry[] tab = table;
4 int len = tab.length;
5 int i = key.threadLocalHashCode & (len-1);
6
7 // 出现哈希冲突
8 for (Entry e = tab[i];
9 e != null;
10 e = tab[i = nextIndex(i, len)]) {
11 ThreadLocal<?> k = e.get();
12
13 // 如果是同一个对象,则覆盖value值
14 if (k == key) {
15 e.value = value;
16 return;
17 }
18
19 // 如果key为null,则替换它的位置
20 if (k == null) {
21 replaceStaleEntry(key, value, i);
22 return;
23 }
24
25 // 否则往后一个位置找,直到找到空的位置
26 }
27
28 tab[i] = new Entry(key, value);
29 int sz = ++size;
30 if (!cleanSomeSlots(i, sz) && sz >= threshold)
31 rehash();
32}
复制代码
当出现哈希冲突时,它的做法看是否是同一个对象或者是是否可以替换,否则往后移动一位,继续判断。
1private static int nextIndex(int i, int len) {
2 return ((i + 1 < len) ? i + 1 : 0);
3}
复制代码
扩容
通过set方法里的代码,我们知道ThreadLocalMap扩容有两个前提:
- !cleanSomeSlots(i, sz)
- size >= threshold
元素个数大于阈值进行扩容,这个很好理解,那么还有一个前提是什么意思呢?我们来看cleanSomeSlots()做了什么:
1private boolean cleanSomeSlots(int i, int n) {
2 boolean removed = false;
3 Entry[] tab = table;
4 int len = tab.length;
5 do {
6 i = nextIndex(i, len);
7 Entry e = tab[i];
8 if (e != null && e.get() == null) {
9 n = len;
10 removed = true;
11 i = expungeStaleEntry(i);
12 }
13 } while ( (n >>>= 1) != 0);
14 return removed;
15}
复制代码
方法上注释写的很明白,从当前插入元素位置,往后扫描数组中的元素,判断是否是“stale entry”。在前面将ThreadLocalMap类声明信息的时候讲过,“stale entry”表示的是那些key为null的entry。cleanSomeSlots方法就是找到他们,调用expungeStaleEntry方法进行清理。如果找到,则返回true,否则返回false。
您问 :为什么扩容要看它的返回值呢?
我答
:因为一旦找到,就调用expungeStaleEntry方法进行清理。
1private int expungeStaleEntry(int staleSlot) {
2 Entry[] tab = table;
3 int len = tab.length;
4
5 // expunge entry at staleSlot
6 tab[staleSlot].value = null;
7 tab[staleSlot] = null;
8 size--;
9
10 // 省略
11}
复制代码
看到没有,size会减一,那么添加元素导致size加1,cleanSomeSlots一旦找到,则会清理一个或者多个元素,size减去的最少为1,所以返回true,自然就没有必要再判断size是否大于等于阈值了。
好了,前提条件一旦满足,则调用rehash方法,此时还未扩容:
1private void rehash() {
2 // 先清理stale entry,会导致size变化
3 expungeStaleEntries();
4
5 // 如果size大于等于3/4阈值,则扩容
6 if (size >= threshold - threshold / 4)
7 resize();
8}
复制代码
哈哈,这里才是真正的扩容,要进行扩容:
- 当前插入元素的位置,往后没有需要清理的stale entry
- size大于等于阈值
- 清理掉stale entry之后,size大于等于3/4阈值
既然搞清楚了条件,那么满足后,又是如何扩容的呢?
1private void resize() {
2 Entry[] oldTab = table;
3 int oldLen = oldTab.length;
4 int newLen = oldLen * 2;
5 // 新建一个数组,按照2倍长度扩容
6 Entry[] newTab = new Entry[newLen];
7 int count = 0;
8
9 for (int j = 0; j < oldLen; ++j) {
10 Entry e = oldTab[j];
11 if (e != null) {
12 ThreadLocal<?> k = e.get();
13 if (k == null) {
14 e.value = null; // Help the GC
15 } else {
16 // key不为null,重新计算索引位置
17 int h = k.threadLocalHashCode & (newLen - 1);
18 while (newTab[h] != null)
19 h = nextIndex(h, newLen);
20 // 插入新的数组中索引位置
21 newTab[h] = e;
22 count++;
23 }
24 }
25 }
26
27 // 阈值为长度的2/3
28 setThreshold(newLen);
29 size = count;
30 table = newTab;
31}
复制代码
两倍长度扩容,重新计算索引,扩容的同时也顺便清理了key为null的元素,即stale entry,不再存入扩容后的数组中。
补充
不知您有没有注意到,ThreadLocalMap中出现哈希冲突时,它是线性探测,直到找到空的位置。这种效率是非常低的,那为什么Java大神们写代码时还要这么做呢?笔者认为取决于它采用的哈希算法,正因为nextHashCode(),保证了冲突出现的可能性很低。而且ThreadLocalMap在处理过程中非常注意清理"stale entry",及时释放出空余位置,从而降低了线性探测带来的低效。
总结
本文讲了这么多,主要是为了让大家明白ThreadLocal应该如何正确的使用,以及使用它背后的原理。后面番外篇,纯属兴趣部分,您可以对比之前笔者《HashMap之元素插入》里面的内容,发散思考。笔者深知水平有限,如有任何意见建议,还请您留言指出,感激不尽!!!最后,感谢大家一如既往的支持,祝近安,祁琛,2019年1月12日。

正文到此结束
- 本文标签: 源码 cat 注释 Java类 Atom Netflix 哈希算法 翻译 线程 时间 总结 微信公众号 Spring cloud 构造方法 tar 代码 final 神器 bug 索引 java NSA value 文章 id ConcurrentHashMap spring https IDE key ACE 垃圾回收 HashMap struct 数据 实例 删除 IO 回答 servlet UI CTO http Service 提问 tab map 空间 src Action zuul tk
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

