SpringBoot之MongoTemplate的查询可以怎么耍
学习一个新的数据库,一般怎么下手呢?基本的CURD没跑了,当可以熟练的增、删、改、查一个数据库时,可以说对这个数据库算是入门了,如果需要更进一步的话,就需要了解下数据库的特性,比如索引、事物、锁、分布式支持等
本篇博文为mongodb的入门篇,将介绍一下基本的查询操作,在Spring中可以怎么玩
原文可参看: 190113-SpringBoot高级篇MongoDB之查询基本使用姿势
I. 基本使用
0. 环境准备
在正式开始之前,先准备好环境,搭建好工程,对于这一步的详细信息,可以参考博文: 181213-SpringBoot高级篇MongoDB之基本环境搭建与使用
接下来,在一个集合中,准备一下数据如下,我们的基本查询范围就是这些数据
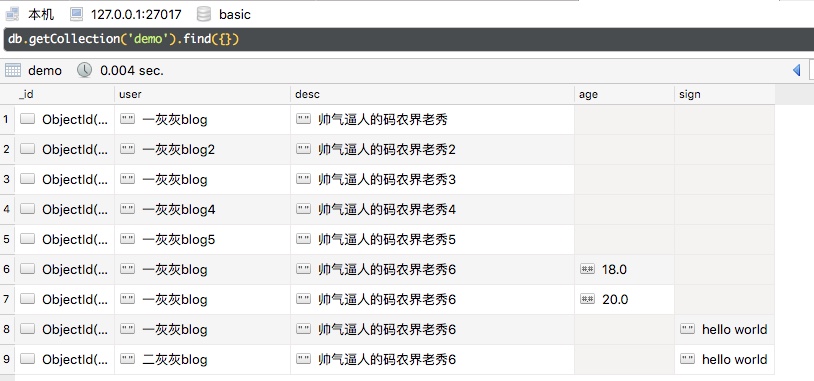
1. 根据字段进行查询
最常见的查询场景,比如我们根据查询 user=一灰灰blog 的数据,这里主要会使用 Query + Criteria 来完成
@Component
public class MongoReadWrapper {
private static final String COLLECTION_NAME = "demo";
@Autowired
private MongoTemplate mongoTemplate;
/**
* 指定field查询
*/
public void specialFieldQuery() {
Query query = new Query(Criteria.where("user").is("一灰灰blog"));
// 查询一条满足条件的数据
Map result = mongoTemplate.findOne(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | specialFieldQueryOne: " + result);
// 满足所有条件的数据
List<Map> ans = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | specialFieldQueryAll: " + ans);
}
}
上面是一个实际的case,从中可以知道一般的查询方式为:
-
Criteria.where(xxx).is(xxx)来指定具体的查询条件 - 封装Query对象
new Query(criteria) - 借助
mongoTemplate执行查询mongoTemplate.findOne(query, resultType, collectionName)
其中findOne表示只获取一条满足条件的数据;find则会将所有满足条件的返回;上面执行之后,删除结果如
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { } | specialFieldQueryOne: {_id=5c2368b258f984a4fda63cee, user=一灰灰blog, desc=帅气逼人的码农界老秀}
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { } | specialFieldQueryAll: [{_id=5c2368b258f984a4fda63cee, user=一灰灰blog, desc=帅气逼人的码农界老秀}, {_id=5c3afaf4e3ac8e8d2d39238a, user=一灰灰blog, desc=帅气逼人的码农界老秀3}, {_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}, {_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}]
2. and多条件查询
前面是只有一个条件满足,现在如果是要求同时满足多个条件,则利用 org.springframework.data.mongodb.core.query.Criteria#and 来斜街多个查询条件
/**
* 多个查询条件同时满足
*/
public void andQuery() {
Query query = new Query(Criteria.where("user").is("一灰灰blog").and("age").is(18));
Map result = mongoTemplate.findOne(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | andQuery: " + result);
}
删除结果如下
query: Query: { "user" : "一灰灰blog", "age" : 18 }, Fields: { }, Sort: { } | andQuery: {_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}
3. or或查询
and对应的就是or,多个条件中只要一个满足即可,这个与and的使用有些区别, 借助 org.springframework.data.mongodb.core.query.Criteria#orOperator 来实现,传参为多个 Criteria 对象,其中每一个表示一种查询条件
/**
* 或查询
*/
public void orQuery() {
// 等同于 db.getCollection('demo').find({"user": "一灰灰blog", $or: [{ "age": 18}, { "sign": {$exists: true}}]})
Query query = new Query(Criteria.where("user").is("一灰灰blog")
.orOperator(Criteria.where("age").is(18), Criteria.where("sign").exists(true)));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | orQuery: " + result);
// 单独的or查询
// 等同于Query: { "$or" : [{ "age" : 18 }, { "sign" : { "$exists" : true } }] }, Fields: { }, Sort: { }
query = new Query(new Criteria().orOperator(Criteria.where("age").is(18), Criteria.where("sign").exists(true)));
result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | orQuery: " + result);
}
执行后输出结果为
query: Query: { "user" : "一灰灰blog", "$or" : [{ "age" : 18 }, { "sign" : { "$exists" : true } }] }, Fields: { }, Sort: { } | orQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}]
query: Query: { "$or" : [{ "age" : 18 }, { "sign" : { "$exists" : true } }] }, Fields: { }, Sort: { } | orQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}, {_id=5c3b0538e3ac8e8d2d392390, user=二灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}]
4. in查询
标准的in查询case
/**
* in查询
*/
public void inQuery() {
// 相当于:
Query query = new Query(Criteria.where("age").in(Arrays.asList(18, 20, 30)));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | inQuery: " + result);
}
输出
query: Query: { "age" : { "$in" : [18, 20, 30] } }, Fields: { }, Sort: { } | inQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
5. 数值比较
数值的比较大小,主要使用的是 get , gt , lt , let
/**
* 数字类型,比较查询 >
*/
public void compareBigQuery() {
// age > 18
Query query = new Query(Criteria.where("age").gt(18));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | compareBigQuery: " + result);
// age >= 18
query = new Query(Criteria.where("age").gte(18));
result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | compareBigQuery: " + result);
}
/**
* 数字类型,比较查询 <
*/
public void compareSmallQuery() {
// age < 20
Query query = new Query(Criteria.where("age").lt(20));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | compareSmallQuery: " + result);
// age <= 20
query = new Query(Criteria.where("age").lte(20));
result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | compareSmallQuery: " + result);
}
输出
query: Query: { "age" : { "$gt" : 18 } }, Fields: { }, Sort: { } | compareBigQuery: [{_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
query: Query: { "age" : { "$gte" : 18 } }, Fields: { }, Sort: { } | compareBigQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
query: Query: { "age" : { "$lt" : 20 } }, Fields: { }, Sort: { } | compareSmallQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}]
query: Query: { "age" : { "$lte" : 20 } }, Fields: { }, Sort: { } | compareSmallQuery: [{_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
6. 正则查询
牛逼高大上的功能
/**
* 正则查询
*/
public void regexQuery() {
Query query = new Query(Criteria.where("user").regex("^一灰灰blog"));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | regexQuery: " + result);
}
输出
query: Query: { "user" : { "$regex" : "^一灰灰blog", "$options" : "" } }, Fields: { }, Sort: { } | regexQuery: [{_id=5c2368b258f984a4fda63cee, user=一灰灰blog, desc=帅气逼人的码农界老秀}, {_id=5c3afacde3ac8e8d2d392389, user=一灰灰blog2, desc=帅气逼人的码农界老秀2}, {_id=5c3afaf4e3ac8e8d2d39238a, user=一灰灰blog, desc=帅气逼人的码农界老秀3}, {_id=5c3afafbe3ac8e8d2d39238b, user=一灰灰blog4, desc=帅气逼人的码农界老秀4}, {_id=5c3afb0ae3ac8e8d2d39238c, user=一灰灰blog5, desc=帅气逼人的码农界老秀5}, {_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}, {_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}]
7. 查询总数
统计常用,这个主要利用的是 mongoTemplate.count 方法
/**
* 查询总数
*/
public void countQuery() {
Query query = new Query(Criteria.where("user").is("一灰灰blog"));
long cnt = mongoTemplate.count(query, COLLECTION_NAME);
System.out.println("query: " + query + " | cnt " + cnt);
}
输出
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { } | cnt 5
8. 分组查询
这个对应的是mysql中的group查询,但是在mongodb中,更多的是通过聚合查询,可以完成很多类似的操作,下面借助聚合,来看一下分组计算总数怎么玩
/*
* 分组查询
*/
public void groupQuery() {
// 根据用户名进行分组统计,每个用户名对应的数量
// aggregate([ { "$group" : { "_id" : "user" , "userCount" : { "$sum" : 1}}}] )
Aggregation aggregation = Aggregation.newAggregation(Aggregation.group("user").count().as("userCount"));
AggregationResults<Map> ans = mongoTemplate.aggregate(aggregation, COLLECTION_NAME, Map.class);
System.out.println("query: " + aggregation + " | groupQuery " + ans.getMappedResults());
}
注意下,这里用 Aggregation 而不是前面的 Query 和 Criteria ,输出如下
query: { "aggregate" : "__collection__", "pipeline" : [{ "$group" : { "_id" : "$user", "userCount" : { "$sum" : 1 } } }] } | groupQuery [{_id=一灰灰blog, userCount=5}, {_id=一灰灰blog2, userCount=1}, {_id=一灰灰blog4, userCount=1}, {_id=二灰灰blog, userCount=1}, {_id=一灰灰blog5, userCount=1}]
9. 排序
sort,比较常见的了,在mongodb中有个有意思的地方在于某个字段,document中并不一定存在,这是会怎样呢?
/**
* 排序查询
*/
public void sortQuery() {
// sort查询条件,需要用with来衔接
Query query = Query.query(Criteria.where("user").is("一灰灰blog")).with(Sort.by("age"));
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | sortQuery " + result);
}
输出结果如下,对于没有这个字段的document也被查出来了
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { "age" : 1 } | sortQuery [{_id=5c2368b258f984a4fda63cee, user=一灰灰blog, desc=帅气逼人的码农界老秀}, {_id=5c3afaf4e3ac8e8d2d39238a, user=一灰灰blog, desc=帅气逼人的码农界老秀3}, {_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}, {_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
10. 分页
数据量多的时候,分页查询比较常见,用得多就是limit和skip了
/**
* 分页查询
*/
public void pageQuery() {
// limit限定查询2条
Query query = Query.query(Criteria.where("user").is("一灰灰blog")).with(Sort.by("age")).limit(2);
List<Map> result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | limitPageQuery " + result);
// skip()方法来跳过指定数量的数据
query = Query.query(Criteria.where("user").is("一灰灰blog")).with(Sort.by("age")).skip(2);
result = mongoTemplate.find(query, Map.class, COLLECTION_NAME);
System.out.println("query: " + query + " | skipPageQuery " + result);
}
输出结果表明,limit用来限制查询多少条数据,skip则表示跳过前面多少条数据
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { "age" : 1 } | limitPageQuery [{_id=5c2368b258f984a4fda63cee, user=一灰灰blog, desc=帅气逼人的码农界老秀}, {_id=5c3afaf4e3ac8e8d2d39238a, user=一灰灰blog, desc=帅气逼人的码农界老秀3}]
query: Query: { "user" : "一灰灰blog" }, Fields: { }, Sort: { "age" : 1 } | skipPageQuery [{_id=5c3b003ee3ac8e8d2d39238f, user=一灰灰blog, desc=帅气逼人的码农界老秀6, sign=hello world}, {_id=5c3afb1ce3ac8e8d2d39238d, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=18.0}, {_id=5c3b0031e3ac8e8d2d39238e, user=一灰灰blog, desc=帅气逼人的码农界老秀6, age=20.0}]
11. 小结
上面给出的一些常见的查询姿势,当然并不全面,比如我们如果需要查询document中的部分字段怎么办?比如document内部结果比较复杂,有内嵌的对象或者数组时,嵌套查询可以怎么玩?索引什么的又可以怎么利用起来,从而优化查询效率?如何通过传说中自动生成的 _id 来获取文档创建的时间戳?
先留着这些疑问,后面再补上
II. 其他
0. 项目
- 工程: spring-boot-demo
- module: mongo-template
- 相关博文: 181213-SpringBoot高级篇MongoDB之基本环境搭建与使用
1. 一灰灰Blog
- 一灰灰Blog个人博客 https://blog.hhui.top
- 一灰灰Blog-Spring专题博客 http://spring.hhui.top
一灰灰的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
2. 声明
尽信书则不如,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 微博地址:小灰灰Blog
- QQ: 一灰灰/3302797840
3. 扫描关注
一灰灰blog

知识星球
正文到此结束
热门推荐










相关文章

近期评论
-
Traveling from China to Turkey becomes more manageable once you apply for the Turkey Visa for Chinese Citizens online. This process is designed to streamline entry requirements and reduce travel stress. Chinese citizens can fill out the form easily, upload the needed documents, and complete the process from home. Once the visa is approved, it's emailed directly, making it easy to carry and show when needed. The system supports efficient travel planning and helps travelers focus on the excitement of their trip. Whether you're exploring local markets or relaxing at beach resorts, secure your visa ensures everything starts on the right path.
-
已加上
-
-
??? 我的链接居然被你干掉了?
-
666 666
-
666
-
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

