服务器后台开服面试心得
去年的这个时候小编通过两个月的复习拿到了阿里巴巴的 offer,有一些运气,也有一些心得,借着跳槽季来临特此分享出来。
简单梳理一下我的复习思路,同时也希望和大家一起交流讨论,一起学习,如果不对之处欢迎指正一起学习。本文即是复习思路,亦可当做学习思路。

我大致把 JAVA 的复习分为如下几个方向。
- JVM;
- 排序算法和 Java 集合&工具类;
- 多线程和并发包;
- 存储相关:Redis 、Elastic Search、MySQL;
- 框架:Spring,SpringMVC,Spring Boot
- 分布式:Dubbo;
- 设计模式;
下面简单说一下如何复习上面的知识,首先明确,小编不会讲解具体的知识点,而是一个思路,纵观互联网上面的帖子、文章误人子弟的多一些,所以就不误人子弟了,而是推荐分析出知识点然后以看书为主。毕竟书是多方校对权威出版的读物。
JVM
JVM 是每一个开发人员必备的技能,推荐看国内比较经典的 JVM 书籍,里面包含JVM的内存接口,类的加载机制等基础知识,是不是觉得这些在面试中似曾相识?所以对于 JVM 方面的知识的巩固与其在网上看一些零零碎碎的文章不如啃一下这本书《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第 2 版)》。
当然了如果你的英文好强烈推荐看 Oracle 最新发布的 JAVA 虚拟机规范。在啃书的时候切记不能图快,你对知识的积累不是通过看书的数量来决定,而是看书的深度。所以在看每一章节的时候看到不懂的要配合网上的文章理解,并且需要看几篇文章理解,因为一篇文章很可能是错误的,小编认为文章的可信度顺序自建域名>*.github.io>SF>简书=博客园>CSDN>转载
排序算法和 Java 集合、工具类
这一个分类是每一个人必须掌握的并熟练使用的,那么为什么我把他们放在一起呢? 因为工具和集合类都源于算法,在准备算法复习之前你要理解,为什么要必考算法。正式因为排序算法和我们编程息息相关。举两个“栗子”。
你可以看一下Collections 中的mergeSort和sort 方法,你会发现 mergeSort 就是归并排序的实现,而 sort 方法结合了归并排序和插入排序,这样使得 sort 方法最差O(NlogN)最好可以达到O(N)的效果。那么只有你自己理解了排序方法的实现,才能更好的使用 JAVA 中的集合类啊?
第二个“栗子”,大家都听闻过 TopN 问题吧,经常在面试中遇到请写一下 TopN 的实现,说到算法它就是一个大顶堆,说到 JAVA 它是一个 PriorityQueue 的实现,那么你理解了 TopN 问题,知道他的时间复杂度,优缺点了,那么是不是就可以熟练运用 JAVA 的工具类写更高效的程序了?
之所以排序算法和 JAVA 集合&工具类 一样重要是因为它们和我们每天的编程息息相关。面试官总是问排序算法也不是在难为你,而是在考察你的编程功底。所以你需要对着排序算法和基本的算法配合 JAVA 的集合类、工具类仔细的研究一番,这样才能更深入的理解他们的关联关系。
多线程和并发包
多线程和并发包,重要性就不累述了,直接说一下学习方法。你首先要理解多线程不仅仅是 Thread 和 Runnable 那么简单,整个并发包下面的工具都是在为多线程服务。对于多线程的学习切不可看几篇面试文章,或者几个关键字 CountDownLatch,Lock 巴拉巴拉就以为理解了多线程的精髓,小编整理了一个大图
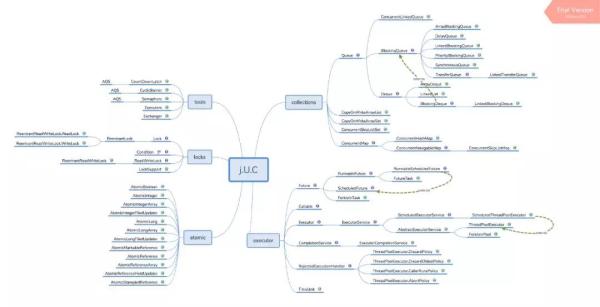
你需要针对这个大图或者自己梳理一个大图,对里面的类各个击破,他们的使用场景,优缺点。当然你需要配合源码看,源码就是大图里面的每一个源码,和上面讲的 JVM 一样,不要着急马上看完,而是看懂每一个地方是为什么。看的差不多你就会发现,其实他和 JAVA 集合类、工具类密不可分。那么自然把它列为重要知识点的原因不言而喻。
Redis、MySQL、ElasticSearch
存储相关相关都是我们平时常用的工具,Redis,MySQL,ElasticSearch。它的知识点分为两方面,一方面是你平时使用过程中积累的经验,另一方面是你对其的深入理解。所以对这个地方的建议就是通过书籍来巩固技术知识, 《Redis设计与实现 (数据库技术丛书)》,《高性能 MySQL》,《ElasticSearch 权威指南》这三本书不一定是该领域最好的书籍,但是如果你吃透了,对于你对知识的理解和程序的设计必定有很大帮助。书里面的内容太多,还是举两个“栗子”。
第一个“栗子”,使用 Redis 切不可只用他当做 key-value 缓存数据库。小编了解到它的5种基本类型中一种类型叫做 sorted set。sorted set 里 items 内容大于 64 的时候同时使用了 hash 和 skiplist 两种设计实现。这也会为了排序和查找性能做的优化。添加和删除都需要修改 skiplist,所以复杂度为 O(log(n))。 但是如果仅仅是查找元素的话可以直接使用 hash,其复杂度为 O(1) ,其他的 range 操作复杂度一般为 O(log(n)),当然如果是小于 64 的时候,因为是采用了 ziplist 的设计,其时间复杂度为 O(n)。这样以后查询和更新阅读都变得简单,那是不是可以用其实现 TopN 的需求呢?这样类似的需求就不需要你查数据,再在内存里面计算和操作了。比如我们简单的周排行,月排行都可以考虑使用这个数据结构实现,当然并不一定这是最好的解决方案,而是提供了一种解题思路。
另一个“栗子”,PriorityQueue 是优先队列我们上文已经了解,那么 ElasticSearch 的 query 也是用的优先队列分别在每一个分片上面获取,然后再合并优先队列你了解吗?这个“栗子”告诉我们其实算法是想通的,你理解一个便可以举一反三触类旁通。
框架
一谈框架就想起来 Spring,一说 Spring 就想起来 IOC,AOP。因为大家都在用这个框架,所以对于框架也不需要看一些其他的,直接就深入了解一下 Spring 就可以了。通过上面的叙述你已经了解了小编的思路,看什么都要看他的实现原理,所以直接推荐你一本书《Spring 技术内幕》然后对着自己现有的 Spring 项目 Debug,从请求的流转梳理知识点。Spring 出来这么久大家对基本的知识已经了然于胸,重要的是看其解决问题的思路和原理,栗子又来了。
比如需要实现在 Bean 刚刚初始化的时候做一些操作,是不是需要使用InitializingBean?那么具体怎么使用,它的原理是什么,Spring Bean 的生命周期是什么样子,通过具体的使用场景逐步展开说明。这样复习效果会更好一些,然后再逐步的思考每一个知识点里面涉及的更多的知识点,比如 AOP 里面的 Proxy 都是基于什么原理实现,有什么优缺点。
分布式
这是一个老生常谈的话题,也是这几年比较火的话题,说起分布式就一定和 Dubbo 有关系,但是不能仅仅就理解到 Dubbo。首先我们需要思考它解决的问题,为什么要引入 Dubbo 这个概念。
随着业务的发展、用户量的增长,系统数量增多,调用依赖关系也变得复杂,为了确保系统高可用、高并发的要求,系统的架构也从单体时代慢慢迁移至服务SOA时代,应运而生的 Dubbo 出现了,它作为 RPC 的出现使得我们搭建微服务项目变得简单,但是我们不仅仅要思考 Dubbo带来的框架支撑。同时需要思考服务的幂等、分布式事务、服务之间的 Trace 定位、分布式日志、数据对账、重试机制等,与此同时考虑 MQ 对系统的解耦和压力的分担、数据库分布式部署和分库分表、限流、熔断等机制。所以最终总结是不仅仅要看 Dubbo 的使用、原理同时还要思考上下游和一些系统设计的问题,这块相对的知识点较多,可以针对上面抛出来的点各个击破。
设计模式
设计模式很多,但是常用的就几种,这个地方可以分两个地方准备。
1、学以致用,设计模式不是背出来的,而是用出来了。平时多注意思考当前项目的设计,是否可以套用设计模式,当然必须先理解每一个设计模式存在的意义。
2、在现有框架中思考设计模式的体现,上面已经讲过框架怎么学习,用 Spring 举例,它里面用了超过9种设计模式,你都知道用到哪里了吗?如果不知道,试着把他们找出来,同时思考为什么这么设计,全部找到以后,基本的设计模式的用法和原理你也就都理解了。
正文到此结束
- 本文标签: 希望 JVM 微服务 服务器 线程 SOA CTO 总结 文章 MQ 集合类 对账 zip 数据库 redis 域名 开发 ACE bug 重试机制 java Oracle 数据 设计模式 SpringMVC 生命 AOP Elasticsearch 幂等 spring https UI 时间 list 博客 Collection 高可用 限流 mysql git sql 需求 value 删除 IO 高并发 缓存 ip 阿里巴巴 GitHub key http ioc 分布式 Proxy 部署 互联网 SDN Collections src bean Spring Boot CountDownLatch 并发 源码 压力 多线程 分布式事务 dubbo queue
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

