Quartz原理解密
quartz是一个用java实现的开源任务调度框架,可以用来创建简单或者复杂的任务调度,并且可以提供许多企业级的功能,比如JTA以及集群等,是当今比较流行的JAVA任务调度框架。
1. 可以用来做什么
Quartz是一个任务调度框架,当遇到以下问题时:
- 想在每月25号,自动还款;
- 想在每年4月1日给当年自己暗恋的女神发一封匿名贺卡;
- 想每隔1小时,备份一下自己的各种资料。
那么总结起来就是,在一个有规律的时间点做一些事情,并且这个规律可以非常复杂,复杂到了需要一个框架来帮助我们。Quartz的出现就是为了解决这个问题,定义一个触发条件,那么其负责到了特定的时间点,触发相应的job干活。
2. 特点
- 强大的调度功能,例如丰富多样的调度方法,可以满足各种常规和特殊需求;
- 灵活的应用方式,比如支持任务调度和任务的多种组合,支持数据的多种存储(DB,RAM等;
- 支持分布式集群,在被Terracotta收购之后,在原来基础上进行了进一步的改造。
二、quartz基本原理
1. 核心元素
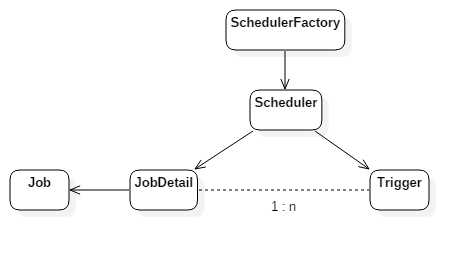
Quartz核心要素有Scheduler、Trigger、Job、JobDetail,其中trigger和job、jobDetail为元数据,而Scheduler为实际进行调度的控制器。
- Trigger
Trigger用于定义调度任务的时间规则,在Quartz中主要有四种类型的Trigger:SimpleTrigger、CronTrigger、DataIntervalTrigger和NthIncludedTrigger。
- Job&Jodetail
Quartz将任务分为Job、JobDetail两部分,其中Job用来定义任务的执行逻辑,而JobDetail用来描述Job的定义(例如Job接口的实现类以及其他相关的静态信息)。对Quartz而言,主要有两种类型的Job,StateLessJob、StateFulJob
- Scheduler
实际执行调度逻辑的控制器,Quartz提供了DirectSchedulerFactory和StdSchedulerFactory等工厂类,用于支持Scheduler相关对象的产生。
2. 核心元素间关系
3. 主要线程
在Quartz中,有两类线程,也即执行线程和调度线程,其中执行任务的线程通常用一个线程池维护。线程间关系如图1-2所示。
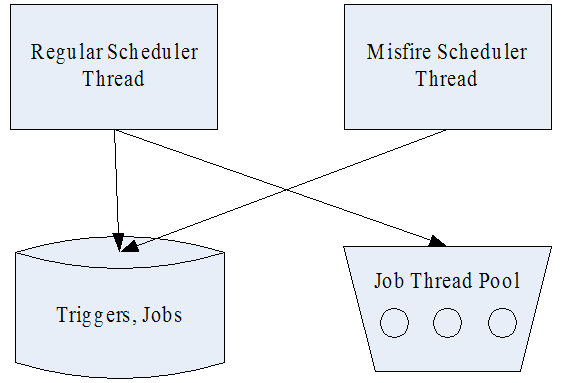
图 1-2
在quartz中,Scheduler调度线程主要有两个:regular Scheduler Thread(执行常规调度)和Misfire Scheduler Thread(执行错失的任务)。其中Regular Thread 轮询Trigger,如果有将要触发的Trigger,则从任务线程池中获取一个空闲线程,然后执行与改Trigger关联的job;Misfire Thraed则是扫描所有的trigger,查看是否有错失的,如果有的话,根据一定的策略进行处理。
4. 数据存储
Quartz中的trigger和job需要存储下来才能被使用。Quartz中有两种存储方式:RAMJobStore,JobStoreSupport,其中RAMJobStore是将trigger和job存储在内存中,而JobStoreSupport是基于jdbc将trigger和job存储到数据库中。RAMJobStore的存取速度非常快,但是由于其在系统被停止后所有的数据都会丢失,所以在集群应用中,必须使用JobStoreSupport。其中表结构如表1-1所示。
| Table name | Description |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的Trigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
| QRTZ_SIMPROP_TRIGGERS |
三、quartz集群原理
一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。这就意味着你必须对每个节点分别启动或停止。Quartz集群中,独立的Quartz节点并不与另一其的节点或是管理节点通信,而是通过相同的数据库表来感知到另一Quartz应用的,如图1-3所示。
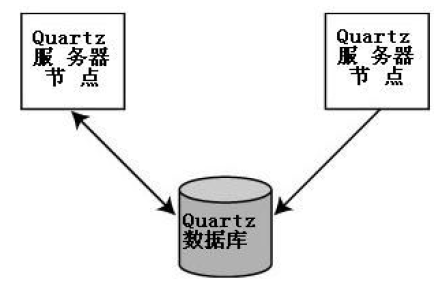
四、quartz主要流程
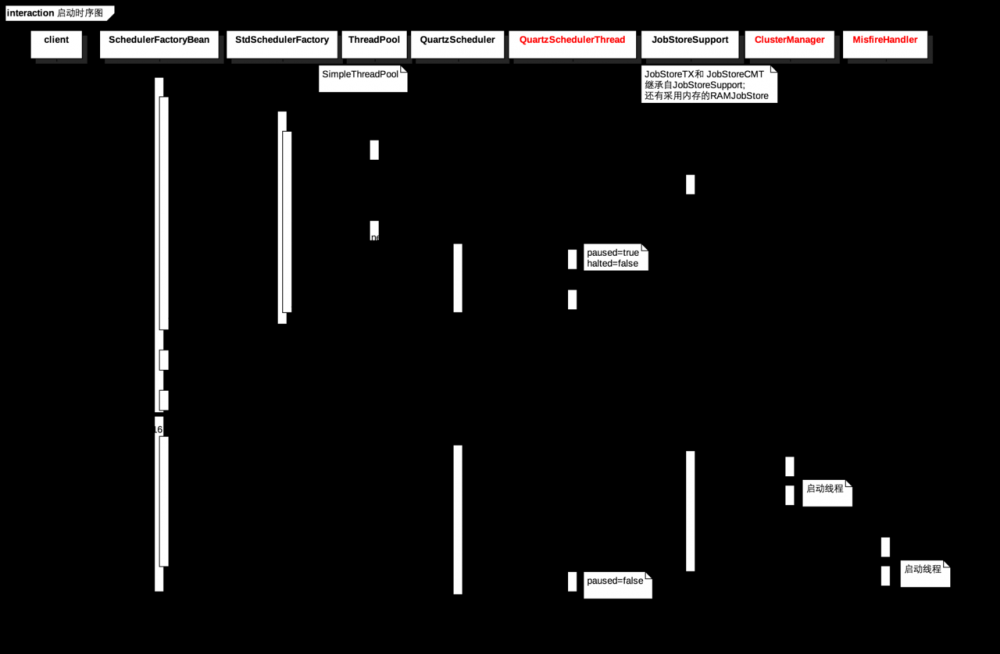
1. 启动流程
若quartz是配置在spring中,当服务器启动时,就会装载相关的bean。SchedulerFactoryBean实现了InitializingBean接口,因此在初始化bean的时候,会执行afterPropertiesSet方法,该方法将会调用SchedulerFactory(DirectSchedulerFactory 或者 StdSchedulerFactory,通常用StdSchedulerFactory)创建Scheduler。SchedulerFactory在创建quartzScheduler的过程中,将会读取配置参数,初始化各个组件,关键组件如下:
-
ThreadPool:一般是使用SimpleThreadPool,SimpleThreadPool创建了一定数量的WorkerThread实例来使得Job能够在线程中进行处理。WorkerThread是定义在SimpleThreadPool类中的内部类,它实质上就是一个线程。在SimpleThreadPool中有三个list:workers-存放池中所有的线程引用,availWorkers-存放所有空闲的线程,busyWorkers-存放所有工作中的线程; 线程池的配置参数如下所示:
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool org.quartz.threadPool.threadCount=3 org.quartz.threadPool.threadPriority=5
-
JobStore:分为存储在内存的RAMJobStore和存储在数据库的JobStoreSupport(包括JobStoreTX和JobStoreCMT两种实现,JobStoreCMT是依赖于容器来进行事务的管理,而JobStoreTX是自己管理事务),若要使用集群要使用JobStoreSupport的方式;
-
QuartzSchedulerThread:用来进行任务调度的线程,在初始化的时候paused=true,halted=false,虽然线程开始运行了,但是paused=true,线程会一直等待,直到start方法将paused置为false;
另外,SchedulerFactoryBean还实现了SmartLifeCycle接口,因此初始化完成后,会执行start()方法,该方法将主要会执行以下的几个动作:
- 创建ClusterManager线程并启动线程:该线程用来进行集群故障检测和处理,将在下文详细讨论;
- 创建MisfireHandler线程并启动线程:该线程用来进行misfire任务的处理,将在下文详细讨论;
- 置QuartzSchedulerThread的paused=false,调度线程才真正开始调度;
Quartz的整个启动流程如图1-4所示。
2. QuartzSchedulerThread线程
QuartzSchedulerThread线程是实际执行任务调度的线程,其中主要代码如下。
while (!halted.get()) {
int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
triggers = qsRsrcs.getJobStore().acquireNextTriggers(now + idleWaitTime,
Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
long triggerTime = triggers.get(0).getNextFireTime().getTime();
long timeUntilTrigger = triggerTime - now;
while (timeUntilTrigger > 2) {
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
}
List<TriggerFiredResult> bndle = qsRsrcs.getJobStore().triggersFired(triggers);
for (int i = 0; i < res.size(); i++) {
JobRunShell shell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle);
shell.initialize(qs);
qsRsrcs.getThreadPool().runInThread(shell);
}
}
复制代码
- 先获取线程池中的可用线程数量(若没有可用的会阻塞,直到有可用的);
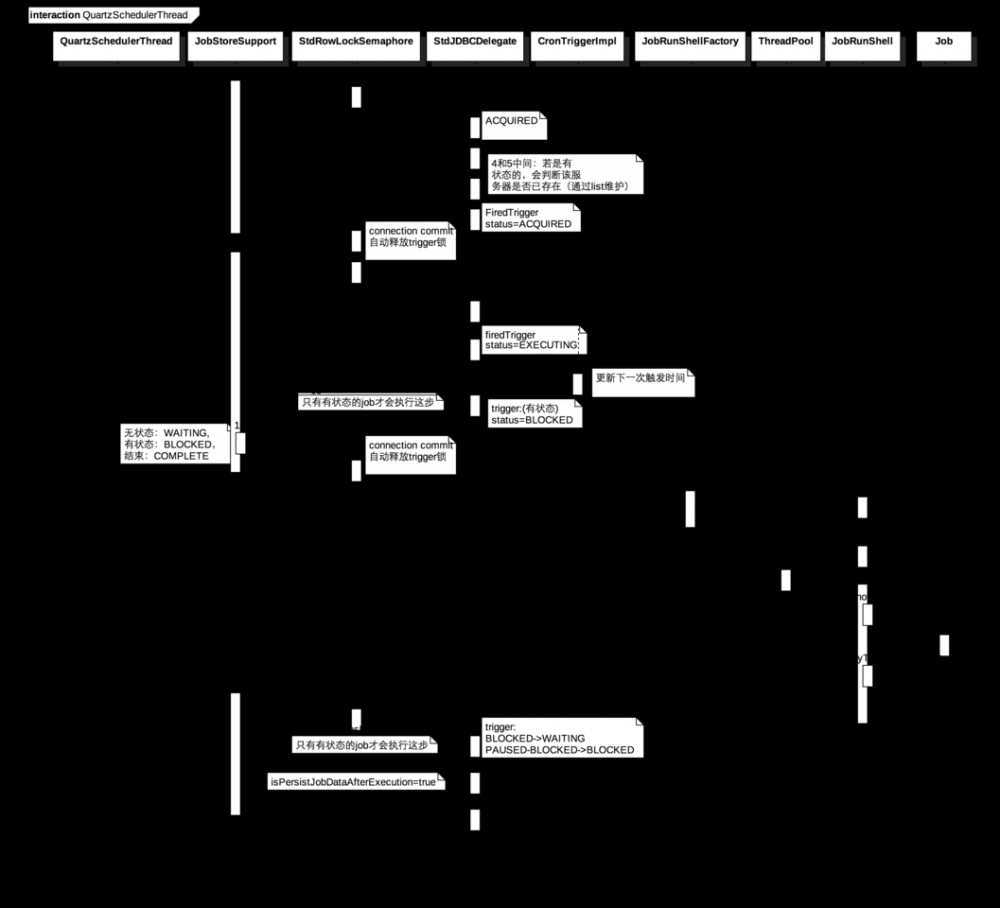
- 获取30m内要执行的trigger(即acquireNextTriggers): 获取trigger的锁,通过select …for update方式实现;获取30m内(可配置)要执行的triggers(需要保证集群节点的时间一致),若@ConcurrentExectionDisallowed且列表存在该条trigger则跳过,否则更新trigger状态为ACQUIRED(刚开始为WAITING);插入firedTrigger表,状态为ACQUIRED;(注意:在RAMJobStore中,有个timeTriggers,排序方式是按触发时间nextFireTime排的;JobStoreSupport从数据库取出triggers时是按照nextFireTime排序);
- 等待直到获取的trigger中最先执行的trigger在2ms内;
- triggersFired:
- 更新firedTrigger的status=EXECUTING;
- 更新trigger下一次触发的时间;
- 更新trigger的状态:无状态的trigger->WAITING,有状态的trigger->BLOCKED,若nextFireTime==null ->COMPLETE;
- commit connection,释放锁;
- 针对每个要执行的trigger,创建JobRunShell,并放入线程池执行:
- execute:执行job
- 获取TRIGGER_ACCESS锁
- 若是有状态的job:更新trigger状态:BLOCKED->WAITING,PAUSED_BLOCKED->BLOCKED
- 若@PersistJobDataAfterExecution,则updateJobData
- 删除firedTrigger
- commit connection,释放锁
调度线程的执行流程如图1-5所示。
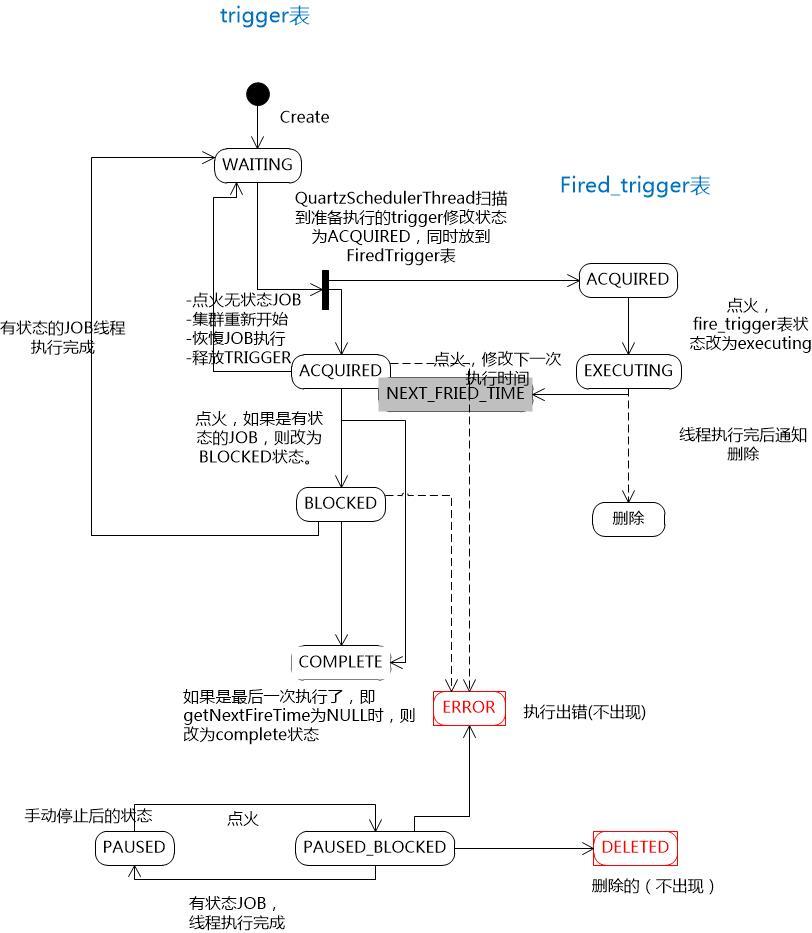
调度过程中Trigger状态变化如图1-6所示。
3. MisfireHandler线程
下面这些原因可能造成 misfired job:
- 系统因为某些原因被重启。在系统关闭到重新启动之间的一段时间里,可能有些任务会被 misfire;
- Trigger 被暂停(suspend)的一段时间里,有些任务可能会被 misfire;
- 线程池中所有线程都被占用,导致任务无法被触发执行,造成 misfire;
- 有状态任务在下次触发时间到达时,上次执行还没有结束;为了处理 misfired job,Quartz 中为 trigger 定义了处理策略,主要有下面两种:
- MISFIRE_INSTRUCTION_FIRE_ONCE_NOW:针对 misfired job 马上执行一次;
- MISFIRE_INSTRUCTION_DO_NOTHING:忽略 misfired job,等待下次触发;默认是MISFIRE_INSTRUCTION_SMART_POLICY,该策略在CronTrigger中=MISFIRE_INSTRUCTION_FIRE_ONCE_NOW线程默认1分钟执行一次;在一个事务中,默认一次最多recovery 20个;
执行流程:
- 若配置(默认为true,可配置)成获取锁前先检查是否有需要recovery的trigger,先获取misfireCount;
- 获取TRIGGER_ACCESS锁;
- hasMisfiredTriggersInState:获取misfired的trigger,默认一个事务里只能最大20个misfired trigger(可配置),misfired判断依据:status=waiting,next_fire_time < current_time-misfirethreshold(可配置,默认1min)
- notifyTriggerListenersMisfired
- updateAfterMisfire:获取misfire策略(默认是MISFIRE_INSTRUCTION_SMART_POLICY,该策略在CronTrigger中=MISFIRE_INSTRUCTION_FIRE_ONCE_NOW),根据策略更新nextFireTime;
- 将nextFireTime等更新到trigger表;
- commit connection,释放锁8.如果还有更多的misfired,sleep短暂时间(为了集群负载均衡),否则sleep misfirethreshold时间,后继续轮询;
misfireHandler线程执行流程如图1-7所示:
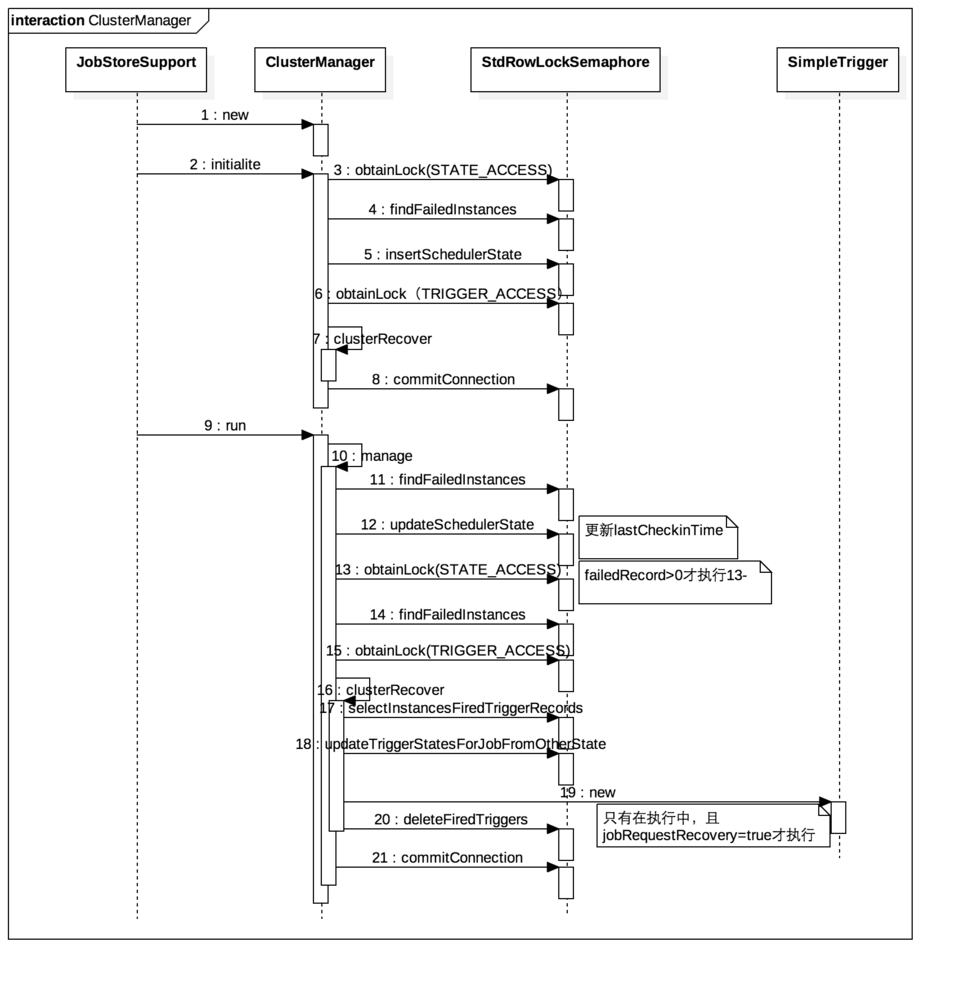
4. ClusterManager集群管理线程
初始化:
failedInstance=failed+self+firedTrigger表中的schedulerName在scheduler_state表中找不到的(孤儿)
线程执行:
每个服务器会定时(org.quartz.jobStore.clusterCheckinInterval这个时间)更新SCHEDULER_STATE表的LAST_CHECKIN_TIME,若这个字段远远超出了该更新的时间,则认为该服务器实例挂了;
注意:每个服务器实例有唯一的id,若配置为AUTO,则为hostname+current_time
线程执行的具体流程:
- 检查是否有超时的实例failedInstances;
- 更新该服务器实例的LAST_CHECKIN_TIME; 若有超时的实例:
- 获取STATE_ACCESS锁;
- 获取超时的实例failedInstances;
- 获取TRIGGER_ACCESS锁;
- clusterRecover:
- 针对每个failedInstances,通过instanceId获取每个实例的firedTriggers;
- 针对每个firedTrigger:
- 更新trigger状态:
- BLOCKED->WAITING
- PAUSED_BLOCKED->PAUSED
- ACQUIRED->WAITING
- 若firedTrigger不是ACQUIRED状态(在执行状态),且jobRequestRecovery=true: 创建一个SimpleTrigger,存储到trigger表,status=waiting,MISFIRE_INSTR=MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY.
- 删除firedTrigger
- 更新trigger状态:
clusterManager线程执行时序图如图1-8所示:
五、注意问题
- 时间同步问题
Quartz实际并不关心你是在相同还是不同的机器上运行节点。当集群放置在不同的机器上时,称之为水平集群。节点跑在同一台机器上时,称之为垂直集群。对于垂直集群,存在着单点故障的问题。这对高可用性的应用来说是无法接受的,因为一旦机器崩溃了,所有的节点也就被终止了。对于水平集群,存在着时间同步问题。
节点用时间戳来通知其他实例它自己的最后检入时间。假如节点的时钟被设置为将来的时间,那么运行中的Scheduler将再也意识不到那个结点已经宕掉了。另一方面,如果某个节点的时钟被设置为过去的时间,也许另一节点就会认定那个节点已宕掉并试图接过它的Job重运行。最简单的同步计算机时钟的方式是使用某一个Internet时间服务器(Internet Time Server ITS)。
- 节点争抢Job问题
因为Quartz使用了一个随机的负载均衡算法,Job以随机的方式由不同的实例执行。Quartz官网上提到当前,还不存在一个方法来指派(钉住) 一个 Job 到集群中特定的节点。
- 从集群获取Job列表问题
当前,如果不直接进到数据库查询的话,还没有一个简单的方式来得到集群中所有正在执行的Job列表。请求一个Scheduler实例,将只能得到在那个实例上正运行Job的列表。Quartz官网建议可以通过写一些访问数据库JDBC代码来从相应的表中获取全部的Job信息。
正文到此结束
- 本文标签: db description 代码 锁 删除 SimpleTrigger RAMJobStore tab tar 管理 参数 http TriggerListeners 线程池 JDBC 服务器 数据 list src Calendars Jobs bus 备份 负载均衡 UI 实例 Connection trigger DirectSchedulerFactory 高可用 update https 配置 Select 企业 Job StdSchedulerFactory 分布式 java struct 集群 CTO 同步 JobDetail JobStores id spring ip 线程 时间 开源 任务调度 Listeners IO rmi shell 数据库 需求 总结 Quartz CronTrigger bean
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
666 666
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

