Java数据结构基础
Collection
List(有序,可重复)
ArrayList
数组,线程不安全。
- 查询:带下标访问数组,O(1)
- 修改:由于arraylist不允许空的空间,当在一个arraylist的中间插入或者删除元素,需要遍历移动插入/删除位置到数组尾部的所有元素。另外arraylist需要扩容时,需要将实际存储的数组元素复制到一个新的数组去,因此一般认为修改的时间复杂度O(N)
扩容
/*minCapacity为原list长度*/
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
默认情况1.5倍增长
Vector
数组,线程安全(条件)
- 与ArrayList不同的是使用了同步(Synchronized),基本实现了线程安全
- 对象进行操作时,不加锁的话还是有问题,例如下面的例子
public Object deleteLast(Vector v){
int lastIndex = v.size()-1;
v.remove(lastIndex);
}
执行 deleteLast 操作时如果不加锁,可能会出现remove时size错误
- 扩容默认2倍增长
Stack堆栈
继承Vector
通过push、pop进行入栈,出栈
LinkedList
双向链表,线程不安全
- 查询,需要遍历链表,时间复杂度O(N)
- 修改,只需要修改1~2个节点的指针地址,时间复杂度O(1)
Set(无序,唯一)
HashSet
HashMap, 线程不安全
- 操作元素时间复杂度, O(1)
LinkedHashSet
LinkedHashMap,线程不安全
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
public LinkedHashSet() {super(16, .75f, true);}
}
//hashset.java中的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
- 操作元素 O(1)
- 由于底层结构是LinkedHashMap,可以记录元素之间插入的顺序
TreeSet
TreeMap, 线程不安全
- 由于是树结构,可以保证数据存储是有序的
- 操作元素时间复杂度,O(logN)
Queue队列
queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优
点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。 如果要使用前端而不移出该元素,使用
element()或者peek()方法。
1、没有实现的阻塞接口的LinkedList:
实现了java.util.Queue接口和java.util.AbstractQueue接口
内置的不阻塞队列: PriorityQueue 和 ConcurrentLinkedQueue
PriorityQueue 和 ConcurrentLinkedQueue 类在 Collection Framework 中加入两个具体集合实现。
PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。
ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大小, ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
2)实现阻塞接口的
java.util.concurrent 中加入了 BlockingQueue 接口和五个阻塞队列类。它实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
五个队列所提供的各有不同:
- ArrayBlockingQueue :一个由数组支持的有界队列。
- LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
- PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
- DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
- SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。
Map
HashMap
链表结构,Node结构
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
JDK 1.8新特性,当节点数大于8时,将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
过长的链表搜索性能降低,使用红黑树来提高查找性能。
hash值计算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对key的hash码高16位实现异或
a⊕b = (¬a ∧ b) ∨ (a ∧¬b)
如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
...
插入table时,下标index = (n - 1) & hash
在n较小时,hash码的低位的0和1不均匀,容易冲突导致碰撞。而通过上述XOR算法调整后,hash的低16位会变大,从而使得0和1分布更加均匀。
计算表容量
static final int MAXIMUM_CAPACITY = 1 << 30;
public HashMap(int initialCapacity, float loadFactor) {
/**省略此处代码**/
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
假设cap=37,则n=36, 100100
- 右移1, 010010,或结果=110110
- 右移2, 001101,或结果=111111
- 右移4, 000011,或结果=111111
- 右移8, 000000,或结果=111111
- 右移16, 000000,或结果=111111
结果为63,二进制或操作只有在两数都为0时,才为0,因此通过循环右移,或操作,实际是为了找到n的最高位,并将后面的数字全部全改写为1,从而实现返回大于等于initialCapacity的最小的2的幂。
扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) { //遍历旧链表
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //单节点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) //树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { //链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { //尾部指针hi
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
这段代码的含义是将oldTab[j]中的链表对半拆到newTab[j]和newTab[j + oldCap]
if ((e.hash & oldCap) == 0)怎么理解
我们知道oldTab中的index = (n - 1) & hash,假设n=8,则
newTab中的index = (16-1) & hash,那么在newTab中的index为index或者index + 8,那么e.hash & oldCap == 0 ,hash 必然为 X001000的形态才有可能,也就是说
if ((e.hash & oldCap) == 0)代表newindex == index的情况
loHead loTail/ hiTail hiHead 这2对指针
前面说了if ((e.hash & oldCap) == 0)表示newindex == index,那么lo指针指向的就是此类节点,hi指针指向剩下的节点
通过tail指针的移动,实现链表拆分以及各节点next指针的更新
HashTable
Dictionary, 线程安全
- 操作元素时间复杂度, O(1)
- synchronized 线程安全
写入数据
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) { //遍历链表
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
扩容
遍历,重新计算index,并填入newMap
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index]; //反转链表
newMap[index] = e;
}
}
}
TreeMap
红黑树是平衡二叉树排序树,我们来看下它的特性
红黑树特性
二叉排序树特性
- 是一棵空树,
-
或者是具有下列性质的二叉树
- 左子树也是二叉排序树,且非空左子树上所有结点的值均小于它的根结点的值
- 右子树也是二叉排序树,且非空右子树上所有结点的值均大于它的根结点的值
平衡二叉树特性
- 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1
- 左右两个子树都是一棵平衡二叉树。
红黑树的特性:
- 节点是红色或黑色。
- 根节点是黑色。
- 每个叶节点(NIL节点,空节点)是黑色的。
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
查找
基于递归的思想处理
/*查找大于等于K的最小节点*/
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp < 0) { //key < p.key
if (p.left != null)
p = p.left;
else
return p;
} else if (cmp > 0) { key > p.key
if (p.right != null) {
p = p.right;
} else { //叔节点
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) {
ch = parent;
parent = parent.parent;
}
return parent;
}
} else
return p;
}
return null;
}
/*查找小于等于K的最大节点, 原理类似,省略*/
final Entry<K,V> getFloorEntry(K key) {
...
}
/*查找大于K的最大节点, 原理类似,省略*/
final Entry<K,V> getHigherEntry(K key) {
...
}
/*查找小于K的最大节点, 原理类似,省略*/
final Entry<K,V> getLowerEntry(K key) {
...
}
恢复平衡
插入/删除节点会破坏红黑树的平衡,为了恢复平衡,可以进行2类操作:旋转和着色
旋转
左旋
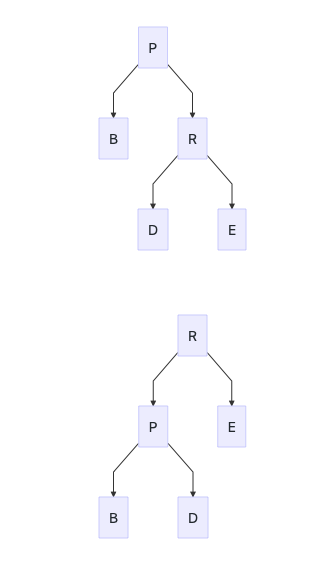
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
Entry<K,V> r = p.right;
p.right = r.left;
if (r.left != null)
r.left.parent = p;
r.parent = p.parent;
if (p.parent == null)
root = r;
else if (p.parent.left == p)
p.parent.left = r;
else
p.parent.right = r;
r.left = p;
p.parent = r;
}
}
右旋
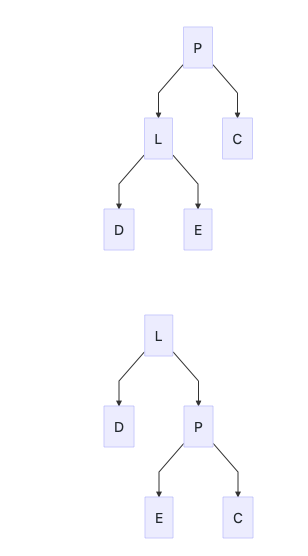
插入节点
插入节点总是为红色
场景分析
-
情形1: 新节点位于树的根上,没有父节点
- 将新节点(根节点设置为黑色)
-
情形2: 新节点的父节点是黑色
- 无处理
-
情形3:新节点的父节点是红色,分3类情况
- 3A: 当前节点的父节点是红色,且当前节点的祖父节点的另一个子节点(叔叔节点)也是红色。
- 3B: 当前节点的父节点是红色,叔叔节点是黑色,且当前节点是其父节点的右孩子
- 3C: 当前节点的父节点是红色,叔叔节点是黑色,且当前节点是其父节点的左孩子
总结
- ==为了保证红黑树特性5,插入的节点需要是红色==
- ==根节点是红色或者黑色,都不影响红黑树特性5,也就是说当父节点和叔节点均为红色时,可以通过将互换祖父与父、叔节点的颜色来上朔不平衡,并最终通过将根节点从红色设置为黑色来解决不平衡==
- ==当叔节点为黑色,父节点为红色时,按照上述思路将父节点与祖父节点颜色互换后,必然会使得当前节点所在的子树黑色节点过多而影响红黑树特性5,因此需要通过旋转将黑色节点向相反方向转移,以平衡根的两侧==
3A
当前节点的父节点是红色,且当前节点的祖父节点的另一个子节点(叔叔节点)也是红色。
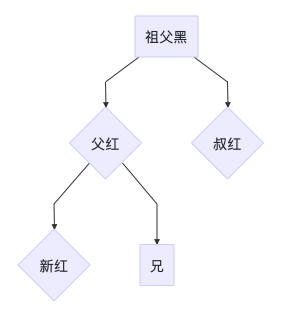
处理思路:
- 父节点与叔节点变黑色
- 祖父节点变红色
- 当前节点转换为祖父节点,迭代处理
graph TD
1[祖父红]-->2[父黑]
1-->3[叔黑]
2-->4{新红}
2-->5[兄]
3B
当前节点的父节点是红色,叔叔节点是黑色,且当前节点是其父节点的右孩子
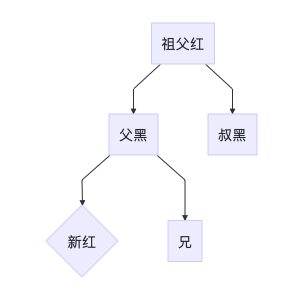
处理思路:
- 左旋/右旋父节点
- 后续操作见3C
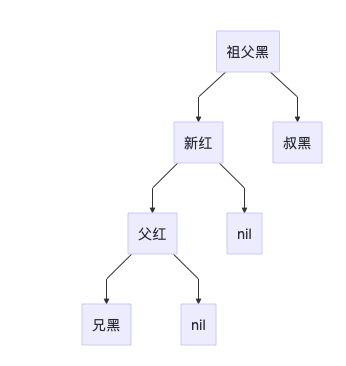
3C
当前节点的父节点是红色,叔叔节点是黑色,且当前节点是其父节点的左孩子
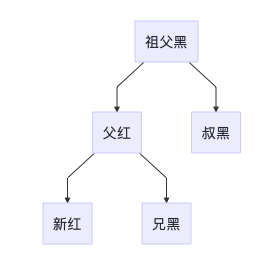
处理思路
- 父节点设置为黑色
- 祖父节点设置为红色
- 右旋/左旋祖父节点
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED; //新插入的节点为红色
while (x != null && x != root && x.parent.color == RED) {
// x的父节点 == x的父-父-左子节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
// y为x的叔节点
if (colorOf(y) == RED) { //叔节点为红色, 3A
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else { //叔节点为黑色
if (x == rightOf(parentOf(x))) { //3B
x = parentOf(x);
rotateLeft(x);
}
//3C
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) { //3A
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) { //3C
x = parentOf(x);
rotateRight(x);
}
//3B
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
删除节点
情况分析
- 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就OK了。
- 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯一子节点顶替它的位置。
- 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。在这里,后继节点相当于替身,在将后继节点的内容复制给"被删除节点"之后,再将后继节点删除。这样就巧妙的将问题转换为"删除后继节点"的情况了,下面就考虑后继节点。 在"被删除节点"有两个非空子节点的情况下,它的后继节点不可能是双子非空。既然"的后继节点"不可能双子都非空,就意味着"该节点的后继节点"要么没有儿子,要么只有一个儿子。若没有儿子,则按"情况①"进行处理;若只有一个儿子,则按"情况② "进行处理。
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// 情况3 将p的值赋予后继节点s,并转换为删除s
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
}
// 情况2
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) {
root = null; //p是根节点
} else { //情况1
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
重新平衡
删除节点x,根据上文分析,x有0或1个子节点
- x是红色节点,那么删除它不会破坏平衡
-
如果x是黑色
- 4A 兄节点为红色
- 4B 兄节点的两个子节点均为黑色
- 4C 兄节点的远端子节点为黑色,另一个为红色或无
- 4D 兄节点的远端子节点为红色,另一个为红色或无
- 兄节点及其子树的黑色节点应该比X多一个
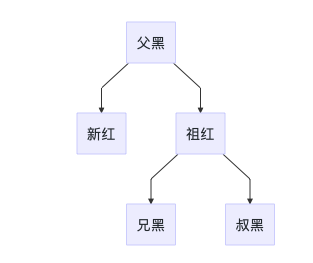
4A 兄节点为红色
处理方法:
- 兄节点设置为黑色
- 父节点设置为红色
- 左旋/右旋父节点,变形为B/C/D情况
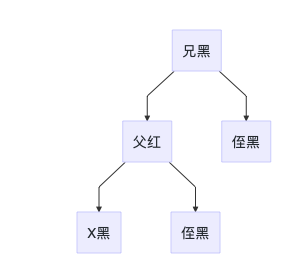
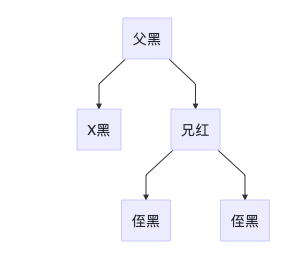
4B 兄节点的两个子节点均为黑色
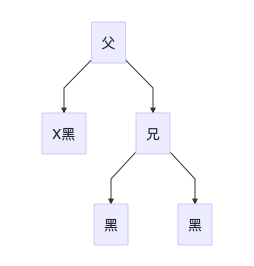
处理方法:
- 兄节点设置为红色
- x设置为父节点,上溯不平衡
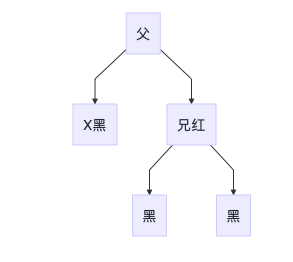
4C 远端侄节点为黑色,另一个为红色或无
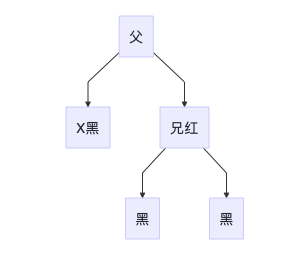
处理方法
- 近端侄节点设置为黑色
- 兄节点设置为红色
- 右旋/左旋兄节点
- 转换为4D处理
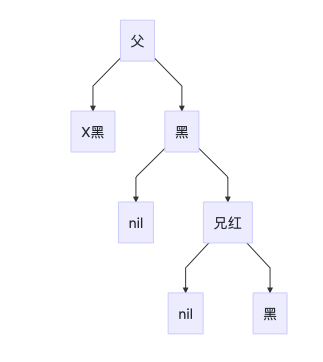
4D 兄节点为黑色,远端侄节点为红色,一个为红色或无
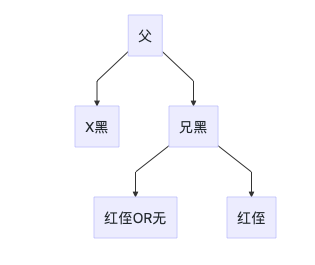
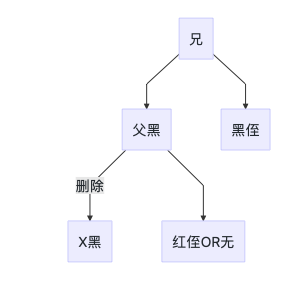
处理方法
- 将父节点的颜色赋予兄节点
- 将父节点设置为黑色
- 将远端侄节点的颜色设置为黑色
- 左旋父节点
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

