Netty系列(二):谈谈ByteBuf
前言
在网络传输过程中,字节是最基本也是最小的单元。JAVA NIO有提供一个ByteBuffer容器去装载这些数据,但是用起来会有点复杂,经常要在读写间进行切换以及不支持动态扩展等等。而netty为我们提供了一个ByteBuf组件,功能是很强大的,本文主要对ByteBuf进行一些讲解,中间会穿插着和ByteBuffer进行对比。
优势
ByteBuf与ByteBuffer的相比的优势:
- 读和写用不同的索引。
- 读和写可以随意的切换,不需要调用flip()方法。
- 容量能够被动态扩展,和StringBuilder一样。
- 用其内置的复合缓冲区可实现透明的零拷贝。
- 支持方法链。
- 支持引用计数。count == 0,release。
- 支持池。
下面将会对每一种优势进行详细的解读。
读写索引
ByteBuffer读写同用position索引,利用flip()方法切换读写模式,而ByteBuf读写分不同的索引,读用readIndex,写用writeIndex,这样可以更加方便我们进行操作,省去了flip这一步骤。ByteBuffer与ByteBuf两种读写模型会在下面用图解形式给大家进行说明。
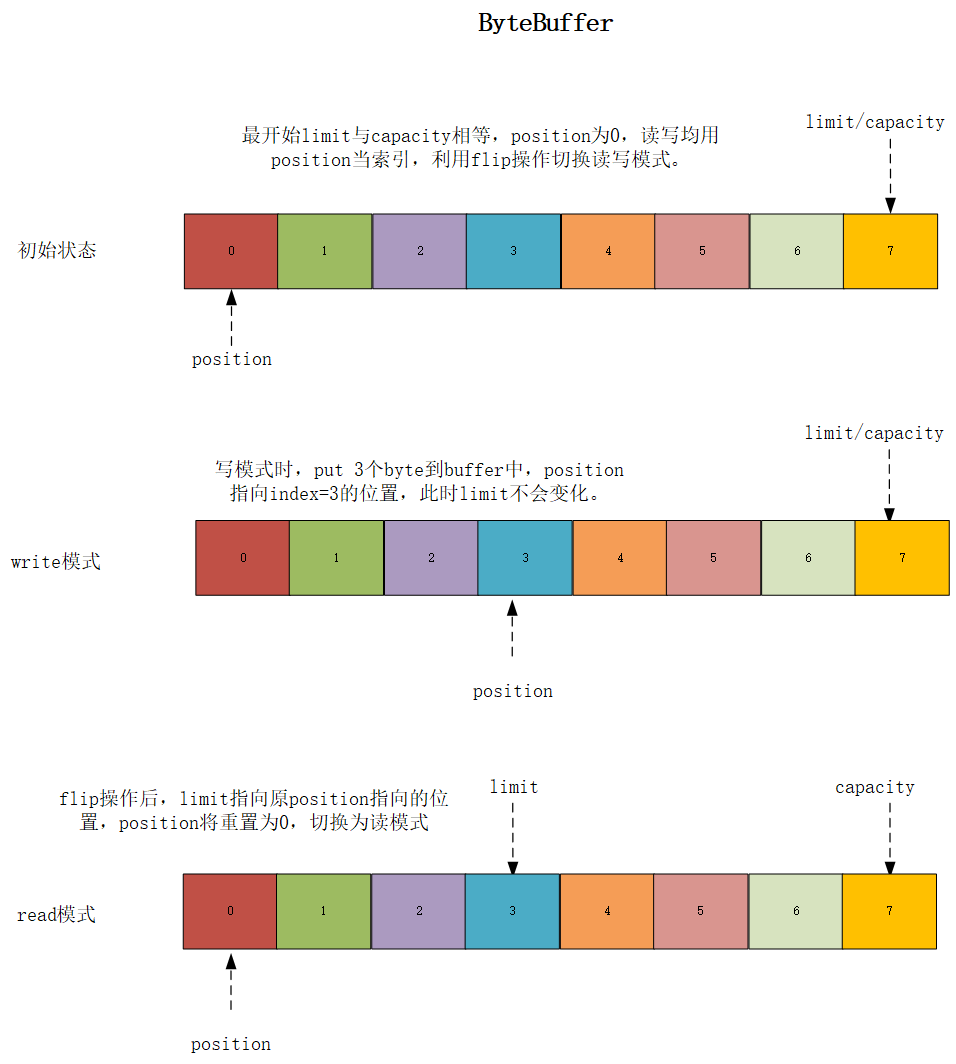
可以根据下面简单的代码自行测试一下:
1 ByteBuffer byteBuffer = ByteBuffer.allocate(8);
2 System.err.println("startPosition: " + byteBuffer.position() + ",limit: " + byteBuffer.limit() + ",capacity: " + byteBuffer.capacity());
3 byteBuffer.put("abc".getBytes());
4 System.err.println("writePosition: " + byteBuffer.position() + ",limit: " + byteBuffer.limit() + ",capacity: " + byteBuffer.capacity());
5 byteBuffer.flip();
6 System.err.println("readPosition: " + byteBuffer.position() + ",limit: " + byteBuffer.limit() + ",capacity: " + byteBuffer.capacity());
复制代码
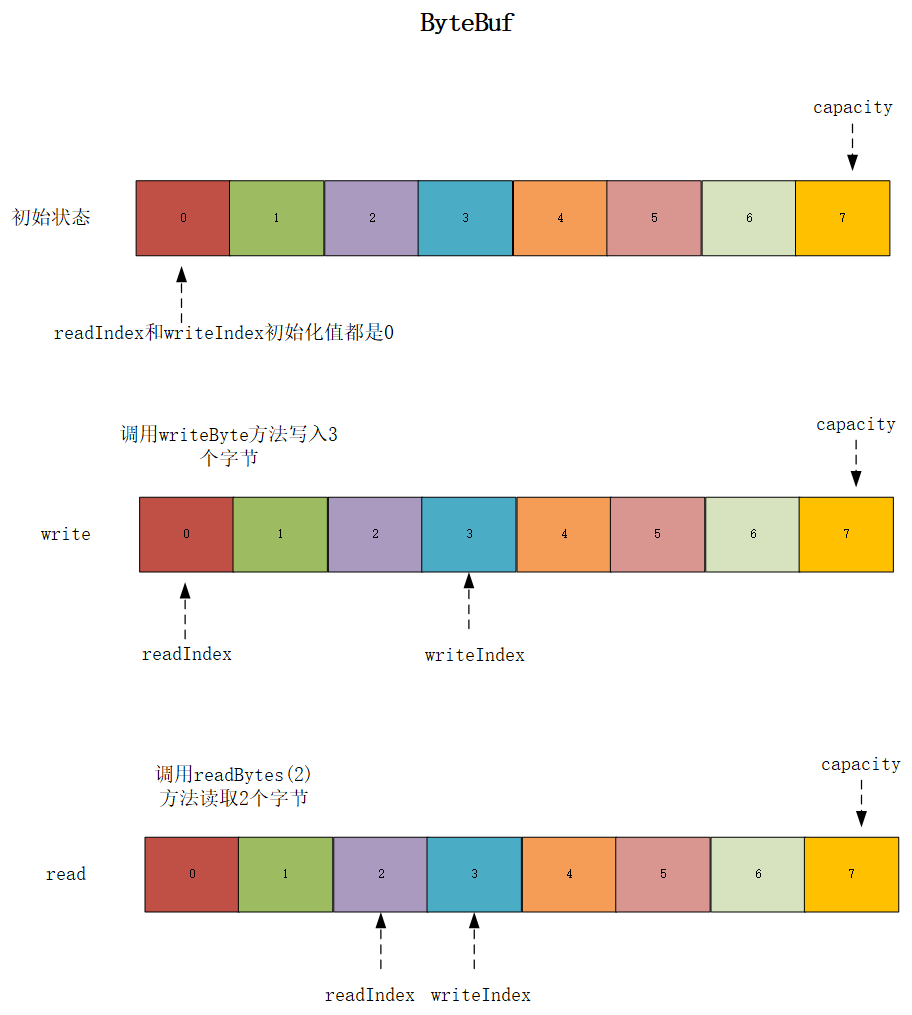
可以根据下面简单的代码自行测试一下:
1 ByteBuf heapBuffer = Unpooled.buffer(8);
2 int startWriterIndex = heapBuffer.writerIndex();
3 System.err.println("startWriterIndex: " + startWriterIndex);
4 int startReadIndex = heapBuffer.readerIndex();
5 System.err.println("startReadIndex: " + startReadIndex);
6 System.err.println("capacity: " + heapBuffer.capacity());
7 System.err.println("========================");
8 for (int i = 0; i < 3; i++) {
9 heapBuffer.writeByte(i);
10 }
11 int writerIndex = heapBuffer.writerIndex();
12 System.err.println("writerIndex: " + writerIndex);
13 heapBuffer.readBytes(2);
14 int readerIndex = heapBuffer.readerIndex();
15 System.err.println("readerIndex: " + readerIndex);
16 System.err.println("capacity: " + heapBuffer.capacity());
复制代码
动态扩展
ByteBuffer是不支持动态扩展的,给定一个具体的capacity,一旦put进去的数据超过其容量,就会抛出 java.nio.BufferOverflowException 异常,而ByteBuf完美的解决了这一问题,支持动态扩展其容量。
零拷贝
netty提供了CompositeByteBuf类实现零拷贝。大多数情况下,在进行网络数据传输时我们会将消息分为 消息头head 和 消息体body ,甚至还会有其他部分,这里我们简单的分为两部分来进行探讨:
以前的做法
1 ByteBuffer header = ByteBuffer.allocate(1);
2 header.put("a".getBytes());
3 header.flip();
4 ByteBuffer body = ByteBuffer.allocate(1);
5 body.put("b".getBytes());
6 body.flip();
7 ByteBuffer message = ByteBuffer.allocate(header.remaining() + body.remaining());
8 message.put(header);
9 message.put(body);
10 message.flip();
11 while (message.hasRemaining()){
12 System.err.println((char)message.get());
13 }
复制代码
这样为了得到完整的消息体相当于对内存进行了多余的两次拷贝,造成了很大的资源的浪费。
netty提供的方法
1 CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
2 ByteBuf headerBuf = Unpooled.buffer(1);
3 headerBuf.writeByte('a');
4 ByteBuf bodyBuf = Unpooled.buffer(1);
5 bodyBuf.writeByte('b');
6 messageBuf.addComponents(headerBuf, bodyBuf);
7 for (ByteBuf buf : messageBuf) {
8 System.out.println((char)buf.readByte());
9 System.out.println(buf.toString());
10 }
复制代码
这里通过CompositeByteBuf 对象将headerBuf 与bodyBuf组合到了一起,也得到了完整的消息体,但是并未进行内存上的拷贝。可以注意下我在上面代码段中进行的 buf.toString() 方法的调用,得出来的结果是:指向的还是原来分配的空间地址,也就证明了零拷贝的观点。
支持引用计数
看一段简单的代码段:
1 ByteBuf buffer = Unpooled.buffer(1);
2 int i = buffer.refCnt();
3 System.err.println("refCnt : " + i); //refCnt : 1
4 buffer.retain();
5 buffer.retain();
6 buffer.retain();
7 buffer.retain();
8 i = buffer.refCnt();
9 System.err.println("refCnt : " + i); //refCnt : 5
10 boolean release = buffer.release();
11 i = buffer.refCnt();
12 System.err.println("refCnt : " + i + " ===== " + release); //refCnt : 4 ===== false
13 release = buffer.release(4);
14 i = buffer.refCnt();
15 System.err.println("refCnt : " + i + " ===== " + release); //refCnt : 0 ===== true
复制代码
这里我感觉就是AQS差不多的概念,retain和lock类似,release和unlock类似,内部维护一个计数器,计数器到0的时候就表示已经释放掉了。往一个已经被release掉的buffer中去写数据,会抛出 IllegalReferenceCountException: refCnt: 0 异常。
在Netty in Action一书中对其的介绍是:
The idea behind reference counting isn’t particularly complex; mostly it involves tracking the number of active references to a specified object. A ReferenceCounted implementation instance will normally start out with an active reference count of 1. As long as the reference count is greater than 0, the object is guaranteed not to be released.When the number of active references decreases to 0, the instance will be released. Note that while the precise meaning of release may be implementation-specific, at the very least an object that has been released should no longer be available for use.
引用计数器实现的原理并不复杂,仅仅只是涉及到一个指定对象的活动引用,对象被初始化后引用计数值为1。只要引用计数大于0,这个对象就不会被释放,当引用计数减到为0时,这个实例就会被释放,被释放的对象不应该再被使用。
支持池
Netty对ByteBuf的分配提供了池支持,具体的类是 PooledByteBufAllocator 。用这个分配器去分配ByteBuf可以提升性能以及减少内存碎片。Netty中默认用 PooledByteBufAllocator 当做ByteBuf的分配器。 PooledByteBufAllocator 对象可以从Channel中或者绑定了Channel的ChannelHandlerContext中去获取到。
1Channel channel = ...; 2ByteBufAllocator allocator = channel.alloc(); 3.... 4ChannelHandlerContext ctx = ...; 5ByteBufAllocator allocator2 = ctx.alloc(); 复制代码
API介绍(介绍容易混淆的几个)
创建ByteBuf
1 // 创建一个heapBuffer,是在堆内分配的
2 ByteBuf heapBuf = Unpooled.buffer(5);
3 if (heapBuf.hasArray()) {
4 byte[] array = heapBuf.array();
5 int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
6 int length = heapBuf.readableBytes();
7 handleArray(array, offset, length);
8 }
9 // 创建一个directBuffer,是分配的堆外内存
10 ByteBuf directBuf = Unpooled.directBuffer();
11 if (!directBuf.hasArray()) {
12 int length = directBuf.readableBytes();
13 byte[] array = new byte[length];
14 directBuf.getBytes(directBuf.readerIndex(), array);
15 handleArray(array, 0, length);
16 }
复制代码
这两者的主要区别:
a. 分配的堆外内存空间,在进行网络传输时就不用进行拷贝,直接被网卡使用。但是这些空间想要被jvm所使用,必须拷贝到堆内存中。
b. 分配和释放堆外内存相比堆内存而言,是相当昂贵的。
c. 使用这两者buffer中的数据的方式也略有不同,见上面的代码段。
读写数据(readByte writeByte)
1 ByteBuf heapBuf = Unpooled.buffer(5);
2 heapBuf.writeByte(1);
3 System.err.println("writeIndex : " + heapBuf.writerIndex());//writeIndex : 1
4 heapBuf.readByte();
5 System.err.println("readIndex : " + heapBuf.readerIndex());//readIndex : 1
6 heapBuf.setByte(2, 2);
7 System.err.println("writeIndex : " + heapBuf.writerIndex());//writeIndex : 1
8 heapBuf.getByte(2);
9 System.err.println("readIndex : " + heapBuf.readerIndex());//readIndex : 1
复制代码
进行readByte和writeByte方法的调用时会改变readIndex和writeIndex的值,而调用set和get方法时不会改变readIndex和writeIndex的值。上面的测试案例中打印的writeIndex和readIndex均为1,并未在调用set和get方法后被改变。
discardReadBytes方法
先看一张图:
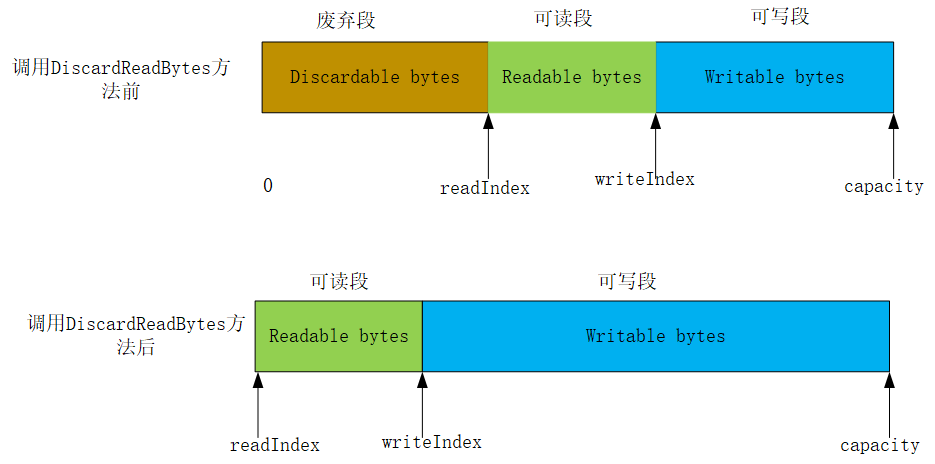
从上面的图中可以观察到,调用discardReadBytes方法后,readIndex置为0,writeIndex也往前移动了Discardable bytes长度的距离,扩大了可写区域。但是这种做法会 严重影响效率 ,它进行了大量的拷贝工作。如果要进行数据的清除操作,建议使用 clear 方法。调用 clear() 方法将会将readIndex和writeIndex同时置为0,不会进行内存的拷贝工作,同时要注意,clear方法不会清除内存中的内容,只是改变了索引位置而已。
Derived buffers
这里介绍三个方法(浅拷贝):
duplicate():直接拷贝整个buffer。
slice():拷贝buffer中已经写了的数据。
slice(index,length): 拷贝buffer中从index开始,长度为length的数据。
readSlice(length): 从当前readIndex读取length长度的数据。
我对上面这几个方法的形容虽然是拷贝,但是这几个方法并没有实际意义上去复制一个新的buffer出来,它和原buffer是共享数据的。所以说调用这些方法消耗是很低的,并没有开辟新的空间去存储,但是修改后会影响原buffer。这种方法也就是咱们俗称的浅拷贝。
要想进行深拷贝,这里可以调用copy()和copy(index,length)方法,使用方法和上面介绍的一致,但是会进行内存复制工作,效率很低。
测试demo:
1 ByteBuf heapBuf = Unpooled.buffer(5);
2 heapBuf.writeByte(1);
3 heapBuf.writeByte(1);
4 heapBuf.writeByte(1);
5 heapBuf.writeByte(1);
6 // 直接拷贝整个buffer
7 ByteBuf duplicate = heapBuf.duplicate();
8 duplicate.setByte(0, 2);
9 System.err.println("duplicate: " + duplicate.getByte(0) + "====heapBuf: " + heapBuf.getByte(0));//duplicate: 2====heapBuf: 2
10 // 拷贝buffer中已经写了的数据
11 ByteBuf slice = heapBuf.slice();
12 System.err.println("slice capacity: " + slice.capacity());//slice capacity: 4
13 slice.setByte(2, 5);
14 ByteBuf slice1 = heapBuf.slice(0, 3);
15 System.err.println("slice1 capacity: "+slice1.capacity());//slice1 capacity: 3
16 System.err.println("duplicate: " + duplicate.getByte(2) + "====heapBuf: " + heapBuf.getByte(2));//duplicate: 5====heapBuf: 5
复制代码
上面的所有测试代码均可以在我的 github 中获取(netty中的buffer模块)。
End
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

