基础设施即代码:Terraform 和 AWS 无服务器
基础设施即代码
基础设施即代码(IaC)是一种通过机器可读的定义文件管理设备和服务器的方法。从根本上说,你要写下你希望基础设施是什么样子,以及应该在该基础设施上运行什么代码。然后,按下一个按钮,说“部署我的基础设施”即可。BAM 是你已经准备投入使用的应用程序,它运行在服务器上,后台是一个通过 API 访问的数据库。你刚刚用 IaC 定义了所有的基础设施。
IaC 是 DEVOPS 团队的一项重要实践,已经集成到 CI/CD 管道。
Terraform 是 HashiCorp 推出的一个很棒的基础设施即代码工具( https://www.terraform.io/ )。
我个人使用它来提供和维护 AWS 上的基础设施。我在这方面有很好的经验。

介绍和演示
我将通过一个例子来演示 IaC。我们将在 AWS 上创建一个应用程序。我在 GitLab 上提供了代码: https://gitlab.com/nxtra/codingtips-blog 。用户可以输入编码提示并查看其他用户输入的所有编码提示。这些提示存储在一个 NoSQL 数据库 AWS DynamoDB 中。存储和检索这些提示是由 Lambda 函数完成的,这些函数从数据库中获取或存放提示。要使用这个应用程序,用户必须能够调用这些 Lambda 函数。因此,我们通过 AWS API 网关公开 Lambda 函数。以下是该应用程序的总体架构。
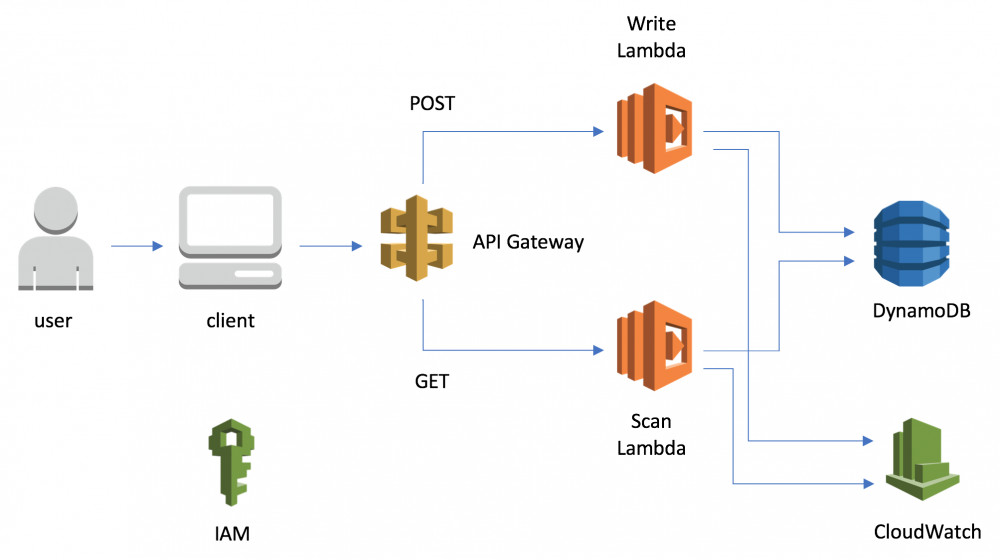
你可以将这些函数组合到一个 Web 页面上,用户可以在该页面中输入提示并查看已有的所有提示。下面是最终结果:
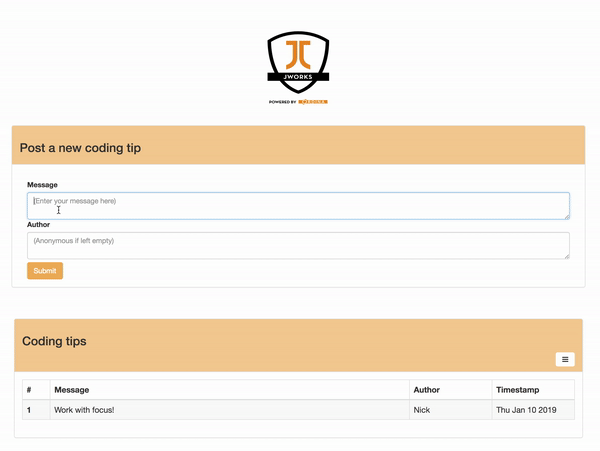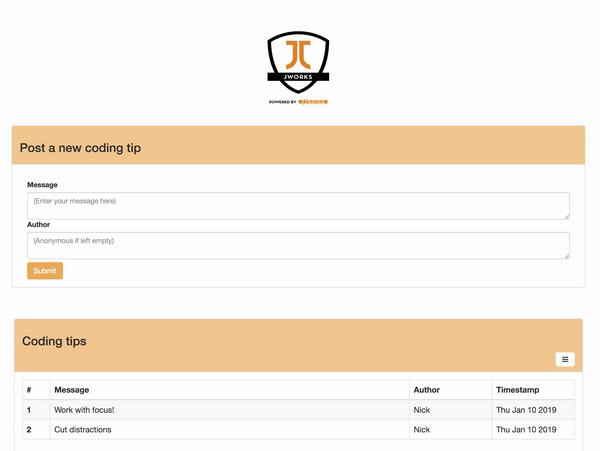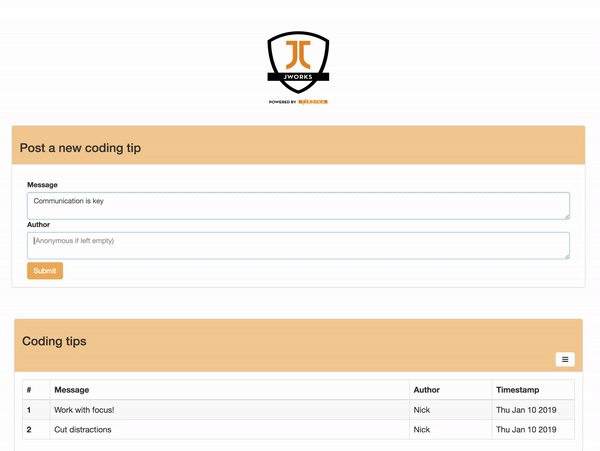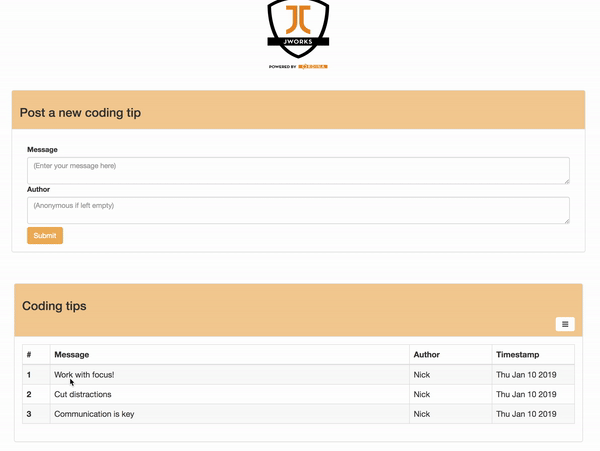
让我们深入了解一下。
创建应用程序
现在,我将介绍创建你在上面的演示中所看到的应用程序的步骤。IaC 是重点。我将展示必要的代码和 AWS CLI 命令,但我不会详细解释它们,因为这不是本文的目的。我将重点介绍 Terraform 的定义。欢迎复制我在下文中提供的存储库,并按照本文提供的步骤进行操作。
准备工作
- 安装 Terraform
- 安装 AWS CLI
- 在 GitLab 上检出库: https://gitlab.com/nxtra/codingtips-blog
- 准备好迎接 IaC 带来的惊喜
Terraform:基础
你将使用 Terraform 配置的主要内容是资源。资源是应用程序基础设施的组件。例如,一个 Lambda 函数、一个 API 网关部署、一个 DynamoDB 数据库……资源是通过在关键字 resource 后面加上类型和名称来定义的。名称可以任意选择。类型是固定的。例如:resource “aws_dynamodb_table” “codingtips-dynamodb-table”。
要按照这篇文章的介绍进行操作,你需要知道以下两个基本的 Terraform 命令。
terraform apply
Terraform apply 将开始准备你定义的所有基础设施,创建你的数据库,设置 Lambda 函数,准备 API 网关。
terraform destroy
Terraform destroy 将删除你在云中配置的所有基础设施。如果你正确地使用了 Terraform,应该就用不到这个命令。但是,如果你想从头重新开始,则可以使用此命令删除所有现有的基础设施。不用担心,你的机器上仍然有所有基础设施的完整描述,因为你使用的是基础设施即代码。
我们将把所有使用 Terraform 定义的基础设施放在同一个文件夹中。文件需要使用.tf 扩展名。
General
让我们从创建一个 general.tf 文件开始。
复制代码
provider"aws"{
region ="eu-west-1"
}
# 变量
variable"lambda_version"{default="1.0.0"}
variable"s3_bucket"{default="codingtips-node-bucket"}
Provider 块指明我们正在向 AWS 上部署。你还可以在这里提供将用于部署的凭证。如果你已经在自己的机器上正确地设置了 AWS CLI,那么,.aws 文件夹中就会有默认凭证。如果没有指定凭证,Terraform 将使用这些默认凭证。
变量有一个名称,我们可以在 Terraform 配置的任何地方引用它。例如,我们可以使用 ${var.s3_bucket) 引用 s3_bucket 变量。当你在多个地方使用相同的变量时,这非常方便。在这篇文章中,我不会使用太多的变量,因为这会使你的 Terraform 配置添加更多的引用,我希望它尽可能清晰。
数据库:DynamoDB
我们从基础开始。我们所有的编码提示将存储在哪里?没错,在数据库中。这个数据库是我们的基础设施的一部分,将在一个名为 dynamo.tf 的文件中定义。
复制代码
resource"aws_dynamodb_table""codingtips-dynamodb-table"{
name ="CodingTips"
read_capacity = 5
write_capacity = 5
hash_key ="Author"
range_key ="Date"
attribute = [
{
name ="Author"
type="S"
},
{
name ="Date"
type="N"
}]
}
因为 Dynamo 是一个 NoSQL 数据库,我们不需要预先指定所有属性。我们唯一需要提供的是 AWS 用来构建分区键的元素。当你提供一个哈希键和一个排序键时,AWS 会把它们组合成一个惟一的分区键。注意“UNIQUE”这个词。确保这个组合是唯一的。
DynamoDB 使用分区键值作为内部哈希函数的输入。哈希函数的输出决定了项存储在哪个分区(DynamoDB 的内部物理存储)。具有相同分区键值的所有项存储在一起,按键值排序。——来自 AWS 文档: DynamoDB 核心组件 。
从 dynamo.tf 中的属性定义可以很容易地看出,Author (S) 是一个字符串,Date (N) 应该是一个数字。
IAM
在指定 Lambda 函数之前,我们必须为要使用的函数创建权限。这确保我们的函数具有访问其他资源(如 DynamoDB)的权限。简单来说,AWS 权限模型的工作原理如下:
- 提供一个带角色的资源
- 给该角色添加权限
- 以下权限允许该角色访问其他资源:
- 触发另一个资源(如 Lambda 函数将日志转发到 CloudWatch)的权限
- 被另一个资源(如 Lambda 函数被 API 网关触发)触发的权限
复制代码
# ROLES
# IAM 角色规定 Lambda 函数可以访问的其他 AWS 服务
resource"aws_iam_role""lambda-iam-role"{
name ="codingtips_lambda_role"
assume_role_policy = <<EOF
{
"Version":"2012-10-17",
"Statement": [
{
"Action":"sts:AssumeRole",
"Principal": {
"Service":"lambda.amazonaws.com"
},
"Effect":"Allow",
"Sid":""
}
]
}
EOF
}
# POLICIES
resource"aws_iam_role_policy""dynamodb-lambda-policy"{
name ="dynamodb_lambda_policy"
role ="${aws_iam_role.lambda-iam-role.id}"
policy= <<EOF
{
"Version":"2012-10-17",
"Statement": [
{
"Effect":"Allow",
"Action": [
"dynamodb:*"
],
"Resource":"${aws_dynamodb_table.codingtips-dynamodb-table.arn}"
}
]
}
EOF
}
在上面的例子中,定义的第一个资源是 aws_iam_role。我们稍后会把这个角色赋予 Lambda 函数。
然后,我们创建了资源 aws_iam_role_policy,将其关联到到角色 aws_iam_role。第一个 aws_iam_role_policy 允许这个角色调用指定 DynamoDB 资源上的任何操作。第二个 role_policy 允许具有此角色的资源向 CloudWatch 发送日志。
以下是几个注意事项:
- aws_iam_role 和 aws_iam_role_policy 通过 role_policy 资源的 role 参数关联;
- 在 aws_iam_role_policy 的 Statement 属性里,我们赋予(Effect 属性)在特定资源上(Resource 属性)执行某些操作的权限(Action 属性);
- 资源通过 ARN 或 Amazon Resource Name 引用,这是资源在 AWS 上的唯一标识;
- 有两种方式可以指定 aws_iam_role_policy:
- 使用 until EOF 语法(正如我此处的做法)
- 使用一个单独的 Terraform aws_iam_policy_document 元素,然后耦合到 aws_iam_role_policy
- dynamodb-lambda-policy 允许在指定的 DynamoDB 资源上执行所有操作,因为 Action 属性的设置为 dynamodb:* 。你可以像下面这样进行更严格的限制,并指出可以执行的操作:
复制代码
"dynamodb:Scan","dynamodb:BatchWriteItem","dynamodb:PutItem"
Lambda 函数
这个应用程序有两个 Lambda 函数。第一个 Lambda 用于从数据库中获取或检索编码提示,引用名是 getLambda。第二个 Lambda 用于将编码提示发布或发送到数据库,引用名是 postlambda。
我不打算在这里复制粘贴 Lambda 函数的代码。你可以通过本文提供的存储库链接查看(GitLab 存储库: https://gitlab.com/nxtra/codingtips-blog) 。
这里,我将以 getLambda 函数为例。postLambda 以相同的方式部署,你可以在 Git 存储库中找到 Terraform 定义。Lambda 函数与我们在这里定义的其他基础设施稍有不同。我们不仅需要一个 Lambda 函数作为基础设施。我们还需要指定在 Lambda 函数中运行的代码。但是,在部署 Lambda 函数时,AWS 将在哪里找到特定的代码呢?他们无法访问你的本地机器,是吗? 这就是为什么你需要首先将代码发送到 AWS 上的 S3 桶,以便在部署函数时可以在那里找到代码。
这就意味着要创建一个 S3 桶,当你想在 eu-west-1(爱尔兰)地区创建时,可以使用下面的命令:
复制代码
awss3apicreate-bucket--bucketcodingtips-node-bucket--regioneu-west-1--create-bucket-configurationLocationConstraint=eu-west-1
现在,你需要使用 zip 压缩你的 Lambda 函数代码:
复制代码
zip -r getLambda.zipindex.js
并把那个文件上传到 S3:
复制代码
awss3cpgetLambda.zips3://codingtips-node-bucket/v1.0.0/getLambda.zip
注意,我将把它发送到存储桶 codingtips-node-bucket 的文件夹 v1.0.0 下,文件名为 getLambda.zip。
好了,代码已经到了该到的地方。现在让我们看看如何使用 Terraform 来指定这些函数。
复制代码
resource"aws_lambda_function""get-tips-lambda"{
function_name="codingTips-get"
# 桶名和之前创建的一样,为 "aws s3api create-bucket"
s3_bucket="${var.s3_bucket}"
s3_key="v${var.lambda_version}/getLambda.zip"
# "main" 是 zip 文件中的文件名(index.js),"handler" 是属性名,其值是那个文件
# 输出的 handler 函数
handler="index.handler"
runtime="nodejs8.10"
memory_size=128
role="${aws_iam_role.lambda-iam-role.arn}"
}
resource"aws_lambda_permission""api-gateway-invoke-get-lambda"{
statement_id="AllowAPIGatewayInvoke"
action="lambda:InvokeFunction"
function_name="${aws_lambda_function.get-tips-lambda.arn}"
principal="apigateway.amazonaws.com"
# /*/* 部分允许从指定 API 网关中的任何资源上的任何方法访问
source_arn="${aws_api_gateway_deployment.codingtips-api-gateway-deployment.execution_arn}/*/*"
}
- 注意,我们把 S3 桶和查找代码的目录告知 Terraform;
- 我们为这个 Lambda 函数指定运行时和内存;
- index.handler 指向该文件和进入代码的函数;
- aws_lambda_permission 资源是权限,说明该 Lambda 函数可以被我们创建的 API 网关调用。
API 网关
我把最难的内容留到最后一部分介绍。另一方面,它也是最有趣的。我给 Terraform 提供 API 的 Swagger 定义。你也可以不使用 Swagger,但是,你必须指定更多的资源。
Swagger API 定义如下:
复制代码
swagger:'2.0'
info:
version:'1.0'
title:"CodingTips"
schemes:
-https
paths:
"/api":
get:
description:"Get coding tips"
produces:
-application/json
responses:
200:
description:"The codingtips request successful."
schema:
type:array
items:
$ref:"#/definitions/CodingTip"
x-amazon-apigateway-integration:
uri:${get_lambda_arn}
passthroughBehavior:"when_no_match"
httpMethod:"POST"
type:"aws_proxy"
post:
description:"post a coding tip"
consumes:
-application/json
responses:
200:
description:"The codingtip was added successfully"
x-amazon-apigateway-integration:
uri:${post_lambda_arn}
passthroughBehavior:"when_no_match"
httpMethod:"POST"
type:"aws_proxy"
definitions:
CodingTip:
type:object
description:"A coding tip"
properties:
tip:
type:string
description:"The coding tip"
date:
type:number
description:"date in millis when tip was entered"
author:
type:string
description:"Author of the coding tip"
category:
type:string
description:"category of the coding tip"
required:
-tip
如果你还不知道 Swagger,复制上述代码并粘贴到在线编辑器里( Swagger 编辑器 )。
这将使你对 API 定义有一个直观的了解。
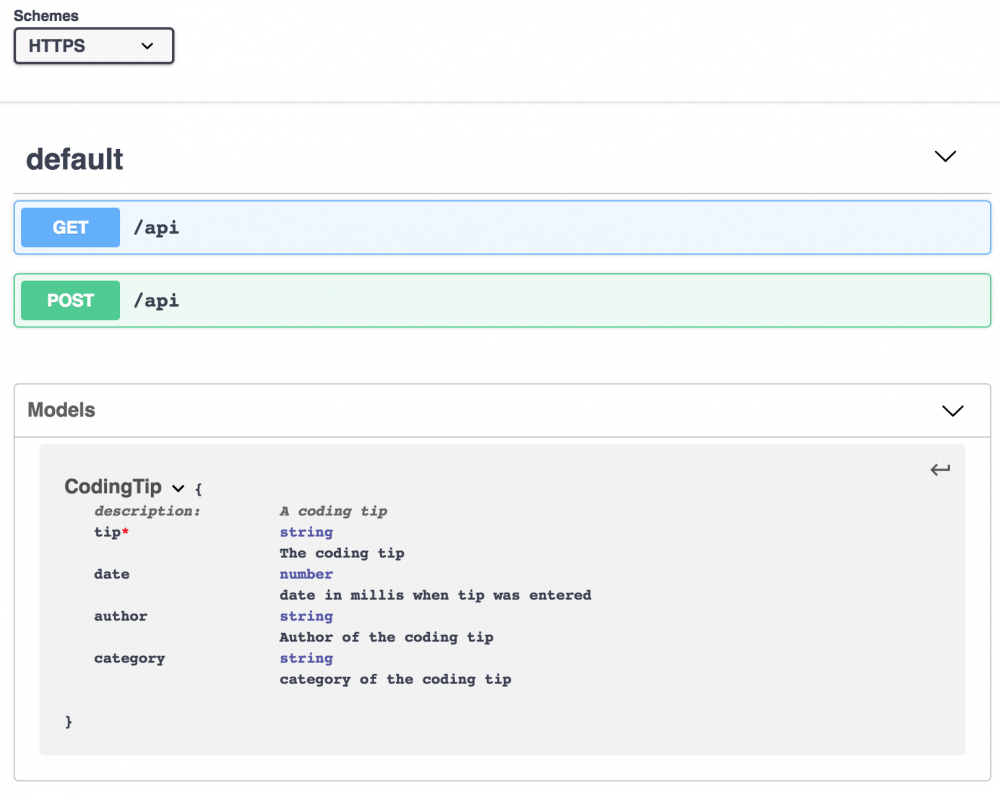
在上述 Swagger 规范中只有一个是 AWS 特定的东西,那就是 x-amazon-apigateway-integration。这指定了 API 与后端集成的细节。
- 注意,这里永远是 POST,即使资源路径的 HTTP 方式是 GET;
- aws_proxy 表示不对请求做任何操作就传递给 Lambda 函数;
- 当没有为 Content-Type 指定 requestTemplate 时,when_no_match 会将请求体直接传到后台,而不做转换;
- uri 引用一个变量,如 ${get_lambda_arn},Terraform 会将其传递给 Swagger 定义。我们一会就会看到。
前面已经提到,使用 Swagger 定义 API 网关有一些优点:
- 使 Terraform 更为简明;
- 你可以通过 Swagger 获得 API 的良好表示。
复制代码
resource"aws_api_gateway_rest_api""codingtips-api-gateway"{
name="CodingTipsAPI"
description="API to access codingtips application"
body="${data.template_file.codingtips_api_swagger.rendered}"
}
data"template_file"codingtips_api_swagger{
template="${file("swagger.yaml")}"
vars {
get_lambda_arn="${aws_lambda_function.get-tips-lambda.invoke_arn}"
post_lambda_arn="${aws_lambda_function.post-tips-lambda.invoke_arn}"
}
}
resource"aws_api_gateway_deployment""codingtips-api-gateway-deployment"{
rest_api_id="${aws_api_gateway_rest_api.codingtips-api-gateway.id}"
stage_name="default"
}
output"url"{
value="${aws_api_gateway_deployment.codingtips-api-gateway-deployment.invoke_url}/api"
}
- 我们首先列出了资源 aws_api_gateway_rest_api resource。该资源就像它的名称一样,提供一个 API 网关 REST API:
- body 引用 Swagger 文件;
- template_file 数据源允许 Terraform 使用 Terraform(在这里是 Swagger )中未定义的信息:
- 传递到 template_file 的变量用于填充文件;
- 要使指定的 REST API 可用,它必须:
- 通过资源 aws_api_gateway_deployment 部署;
- 引用该 REST API;
- 它需要一个 stage,这好比 API 的“版本”或“快照”,stage_name 将用在 URL 中,用于调用这个 API;
- 最后,可以用来调用这个 API 的 URL 被输出到终端,并在末尾加上 /api 以提供正确的资源路径。
尾声
好了,我们现在来看看,这是否真得可行。这里,我在和这篇博文相关的存储库中运行 terraform apply。
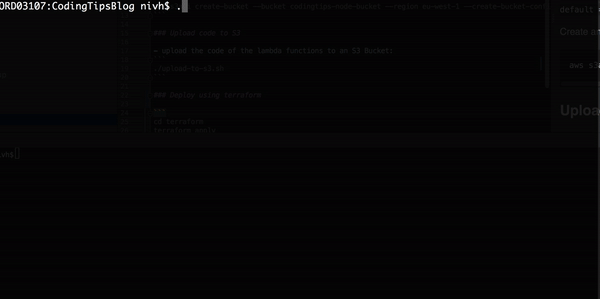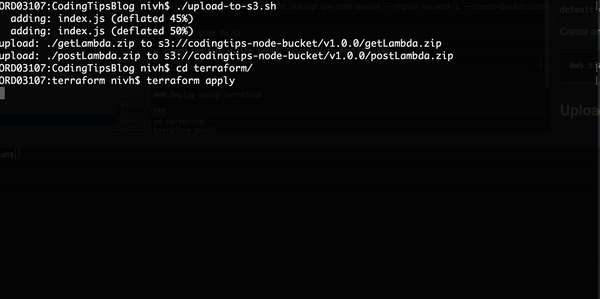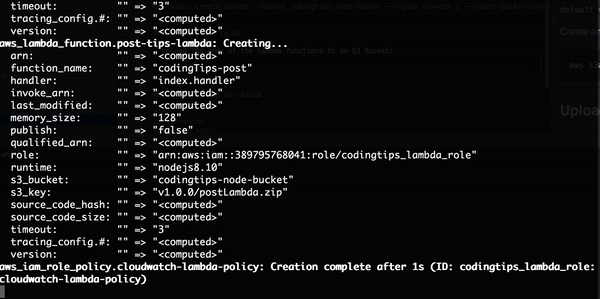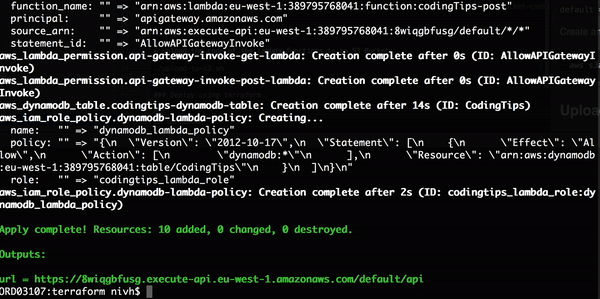
不错,它可以工作。我只告诉 Terraform 我想要的基础设施。整个安装过程自动进行!现在,你可以使用输出的 URL 来 GET 和 POST 编码提示。POST 体应该是这样的:
复制代码
{
"author":"Nick",
"tip":"Short sessions with frequent brakes",
"category":"Empowerment"
}
当你需要将 API 端点耦合到自己设计的前端时,你需要正确设置 CORS 头。如果你想迎接这个挑战,在我解决这个问题的存储库中(cors-enabled)还有另一个分支。
快乐编码人,用代码写下基础设施!
查看英文原文: INFRASTRUCTURE AS CODE: TERRAFORM AND AWS SERVERLESS
正文到此结束
- 本文标签: 云 db 数据库 数据 json Amazon ORM Statement node description UI Document provider Service session tab Region App Action 模型 服务器 js 配置 色调 参数 文章 id 部署 web https 安装 代码 REST 删除 希望 tag zip git NOSQL API 文件上传 http MQ category rmi struct sql 管理 value src 工作原理 lambda 目录 ip cat IDE key schema IO Proxy
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

