hibernate和jdbc的渊源
1、为什么需要hibernate
- 简单介绍jdbc
我们学习Java数据库操作时,一般会设计到jdbc的操作,这是一位程序员最基本的素养。jdbc以其优美的代码和高性能,将瞬时态的javabean对象转化为持久态的SQL数据。但是,每次SQL操作都需要建立和关闭连接,这势必会消耗大量的资源开销;如果我们自行创建连接池,假如每个项目都这样做,势必搞死的了。同时,我们将SQL语句预编译在PreparedStatement中,这个类可以使用占位符,避免SQL注入,当然,后面说到的hibernate的占位符的原理也是这样,同时,mybatis的#{}占位符原理也是如此。预编译的语句是原生的SQL语句,比如更新语句:
private static int update(Student student) {
Connection conn = getConn();
int i = 0;
String sql = "update students set Age='" + student.getAge() + "' where Name='" + student.getName() + "'";
PreparedStatement pstmt;
try {
pstmt = (PreparedStatement) conn.prepareStatement(sql);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
return i;
}
上面的sql语句没有使用占位符,如果我们少了varchar类型的单引号,就会保存失败。在这种情况下,如果写了很多句代码,最后因为一个单引号,导致代码失败,对于程序员来说,无疑是很伤自信心的事。如果涉及到了事务,那么就会非常的麻烦,一旦一个原子操作的语句出现错误,那么事务就不会提交,自信心就会跌倒低谷。然而,这仅仅是更新语句,如果是多表联合查询语句,那么就要写很多代码了。具体的jdbc的操作,可以参考这篇文章: jdbc操作 。
因而,我们在肯定它的优点时,也不应该规避他的缺点。随着工业化步伐的推进,每个数据库往往涉及到很多表,每张表有可能会关联到其他表,如果我们还是按照jdbc的方式操作,这无疑是增加了开发效率。所以,有人厌倦这种复杂繁琐、效率低下的操作,于是,写出了著名的hibernate框架,封装了底层的jdbc操作,以下是jdbc的优缺点:

由上图可以看见,jdbc不适合公司的开发,公司毕竟以最少的开发成本来创造更多的利益。这就出现了痛点,商机伴随着痛点的出现。因而,应世而生了hibernate这个框架。即便没有hibernate的框架,也会有其他框架生成。hibernate的底层封装了jdbc,比如说jdbc为了防止sql注入,一般会有占位符,hibernate也会有响应的占位符。hibernate是orm(object relational mapping)的一种,即对象关系映射。
- 什么对象关系映射
通俗地来说,对象在pojo中可以指Javabean,关系可以指MySQL的关系型数据库的表字段与javabean对象属性的关系。映射可以用我们高中所学的函数映射,即Javabean顺时态的对象映射到数据库的持久态的数据对象。我们都知道javabean在内存中的数据是瞬时状态或游离状态,就像是宇宙星空中的一颗颗行星,除非行星被其他行星所吸引,才有可能不成为游离的行星。瞬时状态(游离状态)的javabean对象的生命周期随着进程的关闭或者方法的结束而结束。如果当前javabean对象与gcRoots没有直接或间接的关系,其有可能会被gc回收。我们就没办法长久地存储数据,这是一个非常头疼的问题。假如我们使用文件来存储数据,但是文件操作起来非常麻烦,而且数据格式不是很整洁,不利于后期的维护等。因而,横空出世了数据库。我们可以使用数据库存储数据,数据库中的数据才是持久数据(数据库的持久性),除非人为的删除。这里有个问题——怎么将瞬时状态(游离状态)的数据转化为持久状态的数据,肯定需要一个连接Javabean和数据库的桥梁,于是乎就有了上面的jdbc。
单独来说mysql,mysql是一个远程服务器。我们在向mysql传输数据时,并不是对象的方式传输,而是以字节码的方式传输数据。为了保证数据准确的传输,我们一般会序列化当前对象,用序列号标志这个唯一的对象。如果,我们不想存储某个属性,它是有数据库中的数据拼接而成的,我们大可不用序列化这个属性,可以使用Transient来修饰。比如下面的获取图片的路径,其实就是服务器图片的文件夹地址和图片的名称拼接而成的。当然,你想存储这个属性,也可以存储这个属性。我们有时候图片的路由的字节很长,这样会占用MySQL的内存。因而,学会取舍,未尝不是一个明智之举。
@Entity
@Table(name = "core_picture")
public class Picture extends BaseTenantObj {
。。。。
@Transient
public String getLocaleUrl() {
return relativeFolder.endsWith("/") ? relativeFolder + name : relativeFolder + "/" + name;
}
。。。。
}
网上流传盛广的对象关系映射的框架(orm)有hibernate、mybatis等。重点说说hibernate和mybatis吧。hibernate是墨尔本的一位厌倦重复的javabean的程序员编写而成的,mybatis是appache旗下的一个子产品,其都是封装了jdbc底层操作的orm框架。但hibernate更注重javabean与数据表之间的关系,比如我们可以使用注解生成数据表,也可以通过注解的方式设置字段的类型、注释等。他将javabean分成了游离态、顺时态、持久态等,hibernate根据这三种状态来触及javabean对象的数据。而mybatis更多的是注重SQL语句的书写,也就是说主要是pojo与SQL语句的数据交互,对此,Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。一旦SQL语句的移动,有可能会影响字段的不对应,因而,mybatis移植性没有hibernate好。mybatis接触的是底层SQL数据的书写,hibernate根据javabean的参数来生成SQL语句,再将SQL查询的结果封装成pojo,因而,mybatis的性能相来说优于hibernate,但这也不是绝对的。性能还要根据你的表的设计结构、SQL语句的封装、网络、带宽等等。我只是抛砖引玉,它们具体的区别,可以参考这篇文档。 mybatis和hibernate的优缺点 。
hibernate和mybatis之间的区别,也是很多公司提问面试者的问题。但是真正熟知他们区别的人,一般是技术选型的架构师。如果你只是负责开发,不需要了解它们的区别,因为他们都封装了jdbc。所以,你不论使用谁,都还是比较容易的。然而,很多公司的HR提问这种问题很死板,HR并不懂技术,他们只是照本宣科的提问。如果你照本宣科的回答,它们觉着你很厉害。但是,如果是一个懂技术的人提问你,如果你只是临时背了它们的区别,而没有相应的工作经验,他们会问的让你手足无措。
- hibernate的讲解
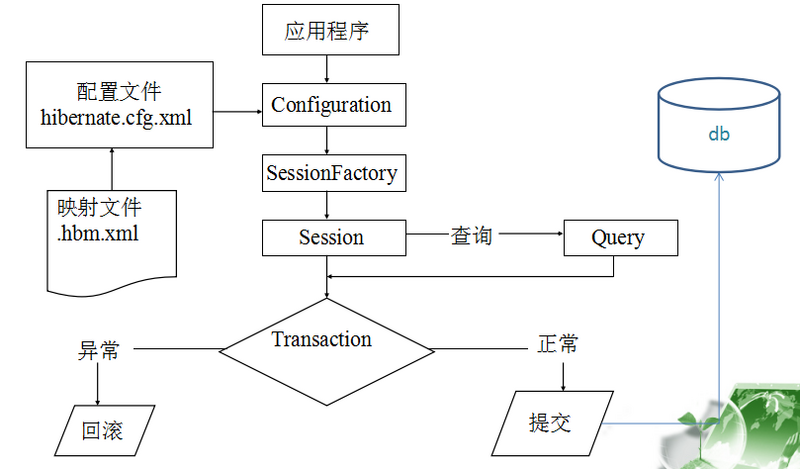
因为我们公司使用的是hibernate,我在这里简单地介绍下hibernate。但相对于jdbc来说,hibernate框架还是比较重的。为什么说他重,因为它集成了太多的东西,看如下的hibernate架构图:

你会发现最上层使我们的java应用程序的开始,比如web的Tomcat服务器的启动,比如main方法的启动等。紧接着就是需要(needing)持久化的对象,这里为什么说是需要,而不是持久化的对象。只有保存到文件、数据库中的数据才是持久化的想通过hibernate,我们可以毫不费力的将瞬时状态的数据转化为持久状态的数据,下面便是hibernate的内部操作数据。其一般是这样的流程:
- 我个人画的
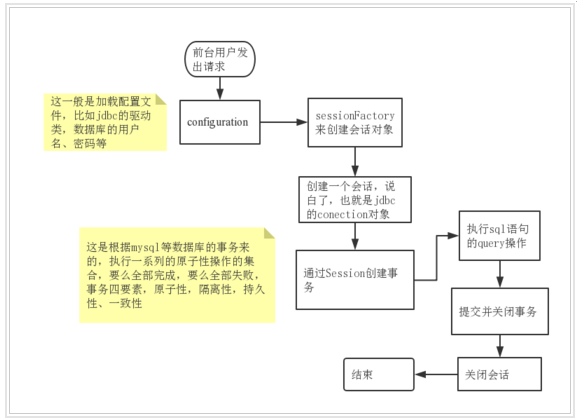
- 这个 地址的图片
如果你是用过jdbc连接数据库的话,我们一般是这样写的:
package com.zby.jdbc.config;
import com.zby.util.exception.TableException;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Properties;
/**
* Created By zby on 22:12 2019/1/5
*/
public class InitJdbcFactory {
private static Properties properties = new Properties();
private static Logger logger = LoggerFactory.getLogger(InitJdbcFactory.class);
static {
try {
//因为使用的类加载器获取配置文件,因而,配置文件需要放在classpath下面,
// 方能读到数据
properties.load(Thread.currentThread().getContextClassLoader().
getResourceAsStream("./jdbc.properties"));
} catch (IOException e) {
logger.info("初始化jdbc失败");
e.printStackTrace();
}
}
public static Connection createConnection() {
String drivers = properties.getProperty("jdbc.driver");
if (StringUtils.isBlank(drivers)) {
drivers = "com.mysql.jdbc.Driver";
}
String url = properties.getProperty("jdbc.url");
String username = properties.getProperty("jdbc.username");
String password = properties.getProperty("jdbc.password");
try {
Class.forName(drivers);
return DriverManager.getConnection(url, username, password);
} catch (ClassNotFoundException e) {
logger.error(InitColTable.class.getName() + ":连接数据库的找不到驱动类");
throw new TableException(InitColTable.class.getName() + ": 连接数据库的找不到驱动类", e);
} catch (SQLException e) {
logger.error(InitColTable.class.getName() + ":连接数据库的sql异常");
throw new TableException(InitColTable.class.getName() + "连接数据库的sql异常", e);
}
}
}
hibernate一般这样连接数据库:
public class HibernateUtils {
private static SessionFactory sf;
//静态初始化
static{
//【1】加载配置文件
Configuration conf = new Configuration().configure();
//【2】 根据Configuration 配置信息创建 SessionFactory
sf = conf.buildSessionFactory();
//如果这里使用了hook虚拟机,需要关闭hook虚拟机
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
System.out.println("虚拟机关闭!释放资源");
sf.close();
}
}));
}
/**
* 采用openSession创建一个与数据库的连接会话,但这种方式需要手动关闭与数据库的session连接(会话),
* 如果不关闭,则当前session占用数据库的资源无法释放,最后导致系统崩溃。
*
**/
public static org.hibernate.Session openSession(){
//【3】 获得session
Session session = sf.openSession();
return session;
}
/**
* 这种方式连接数据库,当提交事务时,会自动关闭当前会话;
* 同时,创建session连接时,autoCloseSessionEnabled和flushBeforeCompletionEnabled都为true,
* 并且session会同sessionFactory组成一个map以sessionFactory为主键绑定到当前线程。
* 采用getCurrentSession()需要在Hibernate.cfg.xml配置文件中加入如下配置:
如果是本地事物,及JDBC一个数据库:
<propety name=”Hibernate.current_session_context_class”>thread</propety>
如果是全局事物,及jta事物、多个数据库资源或事物资源:
<propety name=”Hibernate.current_session_context_class”>jta</propety>
使用spring的getHiberanteTemplate 就不需要考虑事务管理和session关闭的问题:
*
**/
public static org.hibernate.Session getCurrentSession(){
//【3】 获得session
Session session = sf.getCurrentSession();
return session;
}
}
mybatis的配置文件:
public class DBTools {
public static SqlSessionFactory sessionFactory;
static{
try {
//使用MyBatis提供的Resources类加载mybatis的配置文件
Reader reader = Resources.getResourceAsReader("mybatis.cfg.xml");
//构建sqlSession的工厂
sessionFactory = new SqlSessionFactoryBuilder().build(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
//创建能执行映射文件中sql的sqlSession
public static SqlSession getSession(){
return sessionFactory.openSession();
}
}
hibernate、mybatis、jdbc创建于数据库的连接方式虽然不同,但最红都是为了将顺时态的数据写入到数据库中的,但这里主要说的是hibernate。但是hibernate已经封装了这些属性,我们可以在configuration在配置驱动类、用户名、用户密码等。再通过sessionFactory创建session会话,也就是加载Connection的物理连接,创建sql的事务,然后执行一系列的事务操作,如果事务全部成功即可成功,但反有一个失败都会失败。jdbc是最基础的操作,但是,万丈高楼平地起,只有基础打牢,才能走的更远。因为hibernate封装了这些基础,我们操作数据库不用考虑底层如何实现的,因而,从某种程度上来说,hibernate还是比较重的。
- hibernate为什么会重?
比如我们执行插入语句,可以使用save、saveOrUpdate,merge等方法。需要将实体bean通过反射转化为mysql的识别的SQL语句,同时,查询虽然用到了反射,但是最后转化出来的还是object的根对象,这时需要将根对象转化为当前对象,返回给客户端。虽然很笨重,但是文件配置好了,可以大大地提高开发效率。毕竟现在的服务器的性能都比较好,公司追求的是高效率的开发,而往往不那么看重性能,除非用户提出性能的问题。
- 说说merge和saveOrUpdate
merge方法与saveOrUpdate从功能上类似,但他们仍有区别。现在有这样一种情况:我们先通过session的get方法得到一个对象u,然后关掉session,再打开一个session并执行saveOrUpdate(u)。此时我们可以看到抛出异常:Exception in thread "main" org.hibernate.NonUniqueObjectException: a different object with the same identifier value was already associated with the session,即在session缓存中不允许有两个id相同的对象。不过若使用merge方法则不会异常,其实从merge的中文意思(合并)我们就可以理解了。我们重点说说merge。merge方法产生的效果和saveOrUpdate方法相似。这是hibernate的原码:
void saveOrUpdate(Object var1);
void saveOrUpdate(String var1, Object var2);
public Object merge(Object object);
public Object merge(String var1, Object var2);
前者不用返回任何数据,后者返回的是持久化的对象。如果根据hibernate的三种状态,比如顺时态、持久态、游离态来说明这个问题,会比较难以理解,现在,根据参数有无id或id是否已经存在来理解merge,而且从执行他们两个方法而产生的sql语句来看是一样的。
-
参数实例对象没有提供id或提供的id在数据库找不到对应的行数据,这时merger将执行插入操作吗,产的SQL语句如下:
Hibernate: select max(uid) from user Hibernate: insert into hibernate1.user (name, age, uid) values (?, ?, ?)
一般情况下,我们新new一个对象,或者从前端向后端传输javabean序列化的对象时,都不会存在当前对象的id,如果使用merge的话,就会向数据库中插入一条数据。
- 参数实例对象的id在数据库中已经存在,此时又有两种情况
(1)如果对象有改动,则执行更新操作,产生sql语句有:
Hibernate: select user0_.uid as uid0_0_, user0_.name as name0_0_, user0_.age as age0_0_ from hibernate1.user user0_ where user0_.uid=?
Hibernate: update hibernate1.user set name=?, age=? where uid=?
(2)如果对象未改动,则执行查询操作,产生的语句有:
Hibernate: select user0_.uid as uid0_0_, user0_.name as name0_0_, user0_.age as age0_0_ from hibernate1.user user0_ where user0_.uid=?
以上三种是什么情况呢?如果我们保存用户时,数据库中肯定不存在即将添加的用户,也就是说,我们的保存用户就是向数据库中添加用户。但是,其也会跟着某些属性, 比如说用户需要头像,这是多对一的关系,一个用户可能多个对象,然而,头像的关联的id不是放在用户表中的,而是放在用户扩张表中的,这便用到了切分表的概念。 题外话,我们有时会用到快照表,比如商品快照等,也许,我们购买商品时,商品是一个价格,但随后商品的价格变了,我们需要退商品时,就不应该用到商品改变后的价格了,而是商品改变前的价格。 扩展表存放用户额外的信息,也就是用户非必须的信息,比如说昵称,性别,真实姓名,头像等。 因而,头像是图片类型,使用hibernate的注解方式,创建用户表、图片表、用户扩展表。如下所示( 部分重要信息已省略 )
//用户头像
@Entity
@Table(name = "core_user")
public class User extends BaseTenantConfObj {
/**
* 扩展表
* */
@OneToOne(mappedBy = "user", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private UserExt userExt;
}
//用户扩展表的头像属性
@Entity
@Table(name = "core_user_ext")
public class UserExt implements Serializable {
/**
* 头像
*/
@ManyToOne
@JoinColumn(name = "head_logo")
private Picture headLogo;
}
//图片表
@Entity
@Table(name = "core_picture")
public class Picture extends BaseTenantObj {
private static Logger logger = LoggerFactory.getLogger(Picture.class);
。。。。。。
//图片存放在第三方的相对url。
@Column(name = "remote_relative_url", length = 300)
private String remoteRelativeUrl;
// 图片大小
@Column(length = 8)
private Integer size;
/**
* 图片所属类型
* user_logo:用户头像
*/
@Column(name = "host_type", length = 58)
private String hostType;
//照片描述
@Column(name = "description", length = 255)
private String description;
}
前端代码是:
//这里使用到了vue.js的代码,v-model数据的双向绑定,前端的HTML代码
<tr>
<td class="v-n-top">头像:</td>
<td>
<div class="clearfix">
<input type="hidden" name="headLogo.id" v-model="pageData.userInfo.logo.id"/>
<img class="img-user-head fl" :src="(pageData.userInfo&&pageData.userInfo.logo&&pageData.userInfo.logo.path) ? (constant.imgPre + pageData.userInfo.logo.path) : 'img/user-head-default.png'">
<div class="img-btn-group">
<button cflag="upImg" type="button" class="btn btn-sm btn-up">点击上传</button>
<button cflag="delImg" type="button" class="btn btn-white btn-sm btn-del">删除</button>
</div>
</div>
<p class="img-standard">推荐尺寸800*800;支持.jpg, .jpeg, .bmp, .png类型文件,1M以内</p>
</td>
</tr>
//这里用到了js代码,这里用到了js的属性方法
upImg: function(me) {
Utils.asyncImg({
fn: function(data) {
vm.pageData.userInfo.logo = {
path: data.remoteRelativeUrl,
id: data.id
};
}
});
},
上传头像是异步提交,如果用户上传了头像,我们在提交用户信息时,通过“headLogo.id”可以获取当前头像的持久化的图片对象,hibernate首先会根据属性headLogo找到图片表,根据当前头像的id找到图片表中对应的行数据,为什么可以根据id来获取行数据?
-图片表的表结构信息
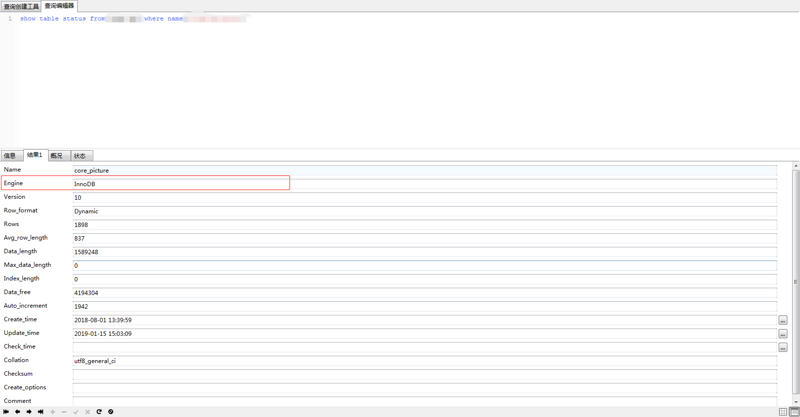
从这张图片可以看出,图片采用默认的存储引擎,也就是InnoDB存储引擎,而不是myiSam的存储引擎。我们都知道这两种存储引擎的区别,如果不知道的话,可以参这篇文章 MySQL中MyISAM和InnoDB的索引方式以及区别与选择 。innodb采用BTREE树的数据结构方式存储,它有0到1直接前继和0到n个直接后继,这是什么意思呢?一棵树当前叶子节点的直接父节点只有一个,但其儿子节点可以一个都没有,也可以有1个、2个、3个......,如果mysql采用的多对一的方式存储的话,你就会发现某条外键下有许多行数据,比如如下的这张表
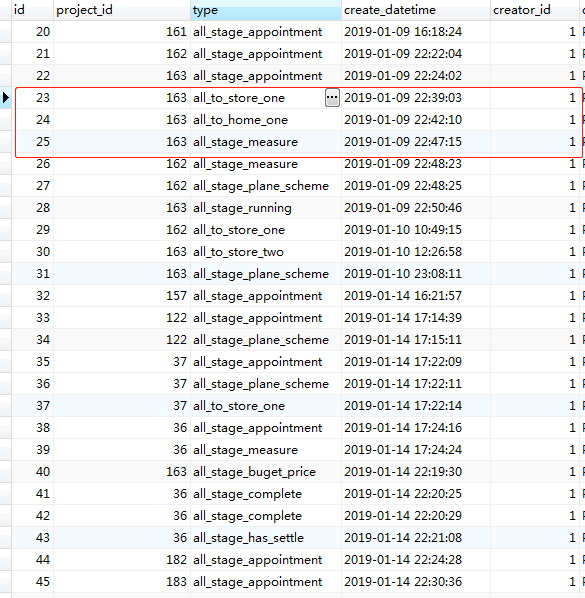
这张表记录的是项目的完成情况,一般有预约阶段,合同已签,合同完成等等。你会发现project_id=163的行数据不止一条,我们通过查询语句: SELECT zpp.* from zq_project_process zpp WHERE zpp.is_deleted = 0 AND zpp.project_id=163 ,查找速度非常快。为什么这么快呢,因为我刚开始说的innodb采用的BTREE树结构存储,其数据是放在当前索引下,什么意思?innodb的存储引擎是以索引作为当前节点值,比如说银行卡表的有个主键索引, 备注,如果我们没有创建任何索引,如果采用的innodb的数据引擎,其内部会创建一个默认的行索引,这就像我们在创建javabean对象时,没有创建构造器,其内部会自动创建一个构造器的道理是一样的。 其数据是怎么存储的呢,如下图所示:
- mysql银行卡数据

- 其内部存储数据

其所对应的行数据是放在当前索引下的,因而,我们取数据不是取表中中的数据,而是取当前主键索引下的数据。项目进程表如同银行卡的主键索引,只不过其有三个索引,分别是主键索引和两个外键索引,如图所示的索引:

索引名是hibernate自动生成的一个名字,索引是项目id、类型两个索引。因为我们不是从表中取数据,而是从当前索引的节点下取数据,所以速度当然快了。 索引有主键索引、外键索引、联合索引等,但一般情况下,主键索引和外键索引使用频率比较高。 同时,innodb存储引擎的支持事务操作,这是非常重要,我们操作数据库,一般都是设计事务的操作,这也mysql默认的存储引擎是innodb。
我们通过主键获取图片的行数据,就像通过主键获取银行卡的行数据。这也是上面所说的,根据是否有id来确定是插入还是更新数据。通过图片主键id获取该行数据后,hibernate会在堆中创建一个picture对象。用户扩展表的headLogo属性指向这个图片对象的首地址,从而创建一个持久化的图片对象。前台异步提交头像时,如果是编辑头像,hibernate会觉擦到当前对象的属性发生了改变,于是,在提交事务时将修改后的游离态的类保存到数据库中。如果我们保存或修改用户时,我们保存的就是持久化的对象,其内部会自动存储持久化头像的id。这是hibernate底层所做的,我们不需要关心。
- 再举一个hibernate事务提交的例子:
我们在支付当中搞得提现事务时,调用第三方支付的SDK时,第三方一般会用我们到订单号,比如我们调用连连支付这个第三方支付的SDK的payRequestBean的实体类:
/**
* Created By zby on 11:00 2018/12/11
* 发送到连连支付的body内容
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PaymentRequestBean extends BaseRequestBean {
/**
* 版本号
*/
@NonNull
private String api_version;
/**
* 银行账户
*/
@NonNull
private String card_no;
/**
* 对私
*/
@NonNull
private String flag_card;
/**
* 回调接口
*/
@NonNull
private String notify_url;
/**
* 商户订单号
*/
@NonNull
private String no_order;
/**
* 商户订单时间,时间格式为 YYYYMMddHHmmss
*/
@NonNull
private String dt_order;
/**
* 交易金额
*/
@NonNull
public String money_order;
/**
* 收款方姓名 即账户名
*/
@NonNull
private String acct_name;
/**
* 收款银行姓名
*/
private String bank_name;
/**
* 订单描述 ,代币类型 + 支付
*/
@NonNull
private String info_order;
/**
* 收款备注
*/
private String memo;
/**
* 支行名称
*/
private String brabank_name;
}
商户订单号是必传的,且这个订单号是我们这边提供的,这就有一个问题了,怎么避免订单号不重复呢?我们可以在提现记录表事先存储一个订单号,订单号的规则如下: "WD" +系统时间+ 当前提现记录的id, 这个id怎么拿到呢?既然底层使用的是merge方法,我们事先不创建订单号,先保存这个记录,其返回的是已经创建好的持久化的对象,该持久化的对象肯定有提现主键的id。我们拿到该持久化对象的主键id,便可以封装订单号,再次保存这个持久化的对象,其内部会执行类似以下的操作:
Hibernate: select user0_.uid as uid0_0_, user0_.name as name0_0_, user0_.age as age0_0_ from hibernate1.user user0_ where user0_.uid=? Hibernate: update hibernate1.user set name=?, age=? where uid=?
代码如下:
withdraw.setWithdrawStatus(WITHDRAW_STATUS_WAIT_PAY);
withdraw.setApplyTime(currentTime);
withdraw.setExchangeHasThisMember(hasThisMember ? YES : NO);
withdraw = withdrawDao.save(withdraw);
withdraw.setOrderNo("WD" + DateUtil.ISO_DATETIME_FORMAT_NONE.format(currentTime) + withdraw.getId());
withdrawDao.save(withdraw);
不管哪种情况,merge的返回值都是一个持久化的实例对象,但对于参数而言不会改变它的状态。
正文到此结束
- 本文标签: 数据 App mybatis http 第三方支付 自动生成 索引 zab mysql 服务器 ip 线程 UI CTO REST core OneToOne sqlsession session 缓存 root tomcat 数据库 配置 注释 value entity ManyToOne SqlSessionFactory 架构师 Statement web db 银行 map 时间 XML src 文章 SqlSessionFactoryBuilder 回答 JDBC apache remote description sql 代码 实例 build ACE ORM 提问 连接池 update tab API Select Connection Word bean id 类加载器 2019 java classpath js cat 管理 HTML 开发 生命 constant IO 存储引擎 tag spring 编译 https 产品 IDE 程序员 参数 删除 Property 图片 字节码 stream logo ssl struct 进程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

