cacheline 对 Go 程序的影响
首先来了解一下来自维基百科上关于CPU缓存的介绍。
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
结构上,一个直接映射(Direct Mapped)缓存由若干缓存块(Cache Block,或Cache Line)构成。每个缓存块存储具有连续内存地址的若干个存储单元。在32位计算机上这通常是一个双字(dword),即四个字节。因此,每个双字具有唯一的块内偏移量。每个缓存块还可对应若干标志位,包括有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等。这些位在保证正确性、排除冲突、优化性能等方面起着重要作用。

Intel的x86架构CPU从386开始引入使用SRAM技术的主板缓存,大小从16KB到64KB不等。486引入两级缓存。其中8KBL1缓存和CPU同片,而L2缓存仍然位于主板上,大小可达268KB。将二级缓存置于主板上在此后十余年间一直设计主流。但是由于SDRAM技术的引入,以及CPU主频和主板总线频率的差异不断拉大,主板缓存在速度上的对内存优势不断缩水。因此,从Pentium Pro起,二级缓存开始和处理器一起封装,频率亦与CPU相同(称为全速二级缓存)或为CPU主频的一半(称为半速二级缓存)。
AMD则从K6-III开始引入三级缓存。基于Socket 7接口的K6-III拥有64KB和256KB的同片封装两级缓存,以及可达2MB的三级主板缓存。
今天的CPU将三级缓存全部集成到CPU芯片上。多核CPU通常为每个核配有独享的一级和二级缓存,以及各核之间共享的三级缓存。
当从内存中取单元到cache中时,会一次取一个cacheline大小的内存区域到cache中,然后存进相应的cacheline中, 所以当你读取一个变量的时候,可能会把它相邻的变量也读取到CPU的缓存中(如果正好在一个cacheline中),因为有很大的几率你回继续访问相邻的变量,这样CPU利用缓存就可以加速对内存的访问。
在多核的情况下,如果两个CPU同时访问某个变量,可能两个CPU都会把变量以及相邻的变量都读入到自己的缓存中:
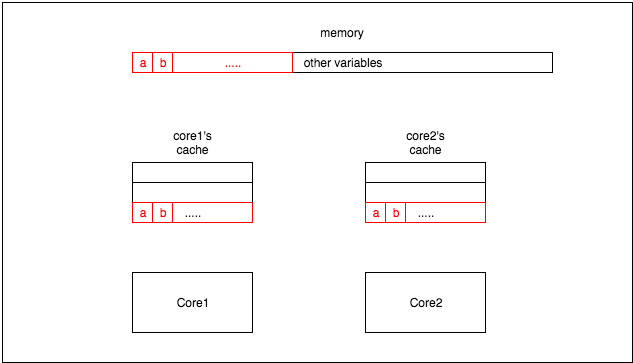
这会带来一个问题:当第一个CPU更新一个变量a的时候,它会导致第二个CPU读取变量b cachemiss, 即使变量b的值实际并没有变化。因为CPU的最小读取单元是cacheline,所以你可以看作a和b是一个整体,这就是伪共享:**一个核对缓存中的变量的更新会强制其它核也更新变量。
伪共享带来了性能的损失,因为从CPU缓存中读取变量要比从内存中读取变量快的多, 这里有一个很经典的图:

在并发编程中,经常会有共享数据被多个goroutine同时访问, 所以如何有效的进行数据的设计,就是一个相当有技巧的操作。最常用的技巧就是 Padding 。现在大部分的CPU的cahceline是64字节,将变量补足为64字节可以保证它正好可以填充一个cacheline。
台湾的 盧俊錡 Genchi Lu 提供了一个很好的例子来比较pad和没有padding的性能(我稍微改了一下)。
package test
import (
"sync/atomic"
"testing"
)
type NoPad struct {
a uint64
b uint64
c uint64
}
func (np *NoPad) Increase() {
atomic.AddUint64(&np.a,1)
atomic.AddUint64(&np.b,1)
atomic.AddUint64(&np.c,1)
}
type Pad struct {
a uint64
_p1 [8]uint64
b uint64
_p2 [8]uint64
c uint64
_p3 [8]uint64
}
func (p *Pad) Increase() {
atomic.AddUint64(&p.a,1)
atomic.AddUint64(&p.b,1)
atomic.AddUint64(&p.c,1)
}
func BenchmarkPad_Increase(b *testing.B) {
pad := &Pad{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
pad.Increase()
}
})
}
func BenchmarkNoPad_Increase(b *testing.B) {
nopad := &NoPad{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
nopad.Increase()
}
})
}
运行结果:
go test -gcflags "-N -l" -bench . goos: darwin goarch: amd64 BenchmarkPad_Increase-4 30000000 56.4 ns/op BenchmarkNoPad_Increase-4 20000000 91.4 ns/op
可能每次运行的结果不相同,但是基本上Padding后的数据结构要比没有padding的数据结构要好的多。
Java中知名的高性能的 disruptor库 中的设计中也采用了padding的方式避免伪共享。
你可以使用 intel-go/cpuid 获取CPU的cacheline的大小, 官方库 x/sys/cpu 也提供了一个 CacheLinePad struct用来padding,你只需要在你的struct定义的第一行增加 _ CacheLinePad 这么一行即可:
var X86 struct {
_ CacheLinePad
HasAES bool // AES hardware implementation (AES NI)
HasADX bool // Multi-precision add-carry instruction extensions
......
参考资料
- https://zh.wikipedia.org/wiki/CPU缓存
- https://medium.com/@genchilu/whats-false-sharing-and-how-to-solve-it-using-golang-as-example-ef978a305e10
- https://github.com/golang/go/issues/14980
- https://github.com/klauspost/cpuid
- https://segment.com/blog/allocation-efficiency-in-high-performance-go-services/
- https://luciotato.svbtle.com/golangs-duffs-devices
- https://stackoverflow.com/questions/14707803/line-size-of-l1-and-l2-caches
- https://luciotato.svbtle.com/golangs-duffs-devices
- https://github.com/golang/go/issues/25203
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

