Java字符串编码介绍
1. 常见字符串编码
常见的字符串编码有:
- LATIN1
- 只能保存ASCII字符,又称ISO-8859-1。
- UTF-8
- 变长字符编码,一个字符需要使用1个、2个或者3个byte表示。由于中文通常需要3个字节表示,中文场景UTF-8编码通常需要更多的空间,替代的方案是GBK/GB2312/GB18030。
- UTF-16
- 2个字符,一个字符需要使用2个byte表示,又称UCS-2 (2-byte Universal Character Set)。根据大小端的区分,UTF-16有两种形式,UTF-16BE和UTF-16LE,缺省UTF-16指UTF-16BE。Java语言中的char是UTF-16LE编码。
- GB18030
- 变长字符编码,一个字符需要使用1个、2个或者3个byte表示。类似UTF8,但中文只需要2个字符,在国际不通用。
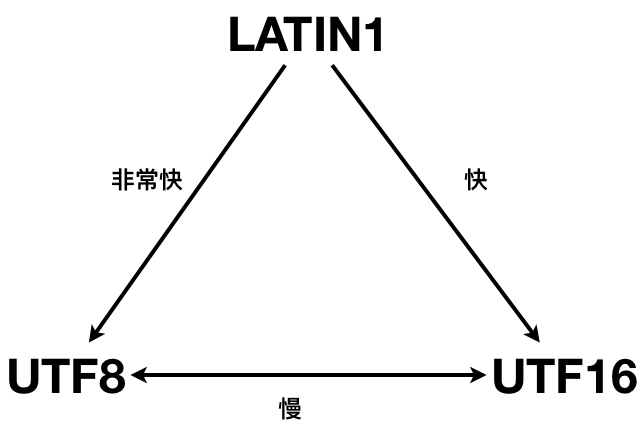
| 编码 | LATIN1 | UTF8 | UTF16 | GB18030 |
|---|---|---|---|---|
| 长度 | 定长为1 | 变长1/2/3 | 定长2 | 变长1/2/3 |
| 计算速度 | 快 | 慢 | 快 | 慢 |
| 英文存储空间 | 小 | 小 | 大 | |
| 中文存储空间 | 大 | 小 | 小 | |
| 典型场景 | 存储常用编码 | 计算常用编码 | 中文存储 |
为了计算方便,内存中字符串通常使用等宽字符,Java语言中char和.NET中的char都是使用UTF-16。早期Windows-NT只支持UTF-16。
2. 编码转换性能
UTF-16和UTF-8之间转换比较复杂,通常性能较差。
如下是一个将UTF-16转换为UTF-8编码的实现,可以看出算法比较复杂,所以性能较差
static int encodeUTF8(char[] utf16, int off, int len, byte[] dest, int dp) {
int sl = off + len, last_offset = sl - 1;
while (off < sl) {
char c = utf16[off++];
if (c < 0x80) {
// Have at most seven bits
dest[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 dest, 11 bits
dest[dp++] = (byte) (0xc0 | (c >> 6));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '/uD800' && c < '/uE000') {
int uc;
if (c < '/uDC00') {
if (off > last_offset) {
dest[dp++] = (byte) '?';
return dp;
}
char d = utf16[off];
if (d >= '/uDC00' && d < '/uE000') {
uc = (c << 10) + d + 0xfca02400;
} else {
throw new RuntimeException("encodeUTF8 error", new MalformedInputException(1));
}
} else {
uc = c;
}
dest[dp++] = (byte) (0xf0 | ((uc >> 18)));
dest[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dest[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (uc & 0x3f));
off++; // 2 utf16
} else {
// 3 dest, 16 bits
dest[dp++] = (byte) (0xe0 | ((c >> 12)));
dest[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}
复制代码
由于Java中char是UTF-16LE编码,如果需要将char[]转换为UTF-16LE编码的byte[]时,可以使用sun.misc.Unsafe#copyMemory方法快速拷贝。比如:
static int writeUtf16LE(char[] chars, int off, int len, byte[] dest, final int dp) {
UNSAFE.copyMemory(chars
, CHAR_ARRAY_BASE_OFFSET + off * 2
, dest
, BYTE_ARRAY_BASE_OFFSET + dp
, len * 2
);
dp += len * 2;
return dp;
}
复制代码
3. Java String的编码
不同版本的JDK String的实现不一样,从而导致有不同的性能表现。char是UTF-16编码,但String在JDK 9之后内部可以有LATIN1编码。
3.1. JDK 6之前的String实现
class String {
char[] value;
int offset;
int count;
}
复制代码
在Java 6之前,String.subString方法产生的String对象和原来String对象公用一个char[],这会导致引用subString会导致一个较大的char[]被引用而无法被GC回收。于是使得很多库都会针对JDK 6及以下版本避免使用subString方法。
3.2. JDK 7/8的String实现
class String {
char[] value;
}
复制代码
JDK 7之后,字符串去掉了offset和count字段,value.length就是原来的count。这避免了subString引用大char[]的问题,优化也更容易,从而JDK7/8中的String操作性能比Java 6有较大提升。
3.3. JDK 9/10/11的实现
class String {
byte code;
byte[] value;
static final byte LATIN1 = 0;
static final byte UTF16 = 1;
}
复制代码
JDK 9之后,value类型从char[]变成byte[],增加了一个字段code,如果字符全部是ASCII字符,使用value使用LATIN编码;如果存在任何一个非ASCII字符,则用UTF16编码。这种混合编码的方式,使得英文场景占更少的内存。缺点是导致Java 9的String API性能可能不如JDK 8,有些场景下降10%。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

