互联网大厂Java面试题:使用无界队列的线程池会导致内存飙升吗?【石杉的架构笔记】
今天跟大家聊一个互联网大厂的Java面试题:使用无界队列的线程池会导致内存飙升吗?
因为在面互联网大厂的时候,一定会问并发,问并发的时候一定会问到线程池,问到线程池一定会问构造线程池的一些参数的含义。
然后,有一些面试官会就线程池的具体场景,问一些可能会遇到的问题。
所以,在这里就可能有上述那样一个面试中的问题,算是Java面试里相对来说高阶一点的。
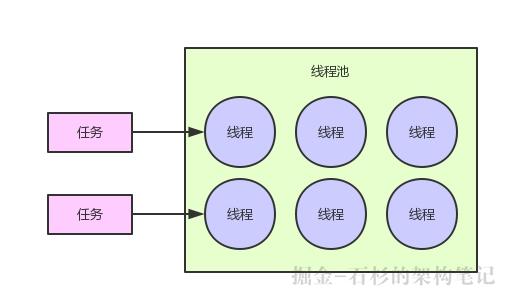
我相信大家一定起码知道线程池是个什么东西的。简单来说,就是维护一个池子,池子里面放了很多的线程。
然后来一个任务,某个线程就获取这个任务来执行,任务执行完之后线程是不会释放掉的,而是停留在线程池里继续等待下一个任务。
这样的一个好处是你没必要自己手动频繁的创建和销毁线程,毕竟线程是较重的资源,频繁的创建和销毁对系统性能是没好处的。
我们看看下面的图,回顾一下线程池的含义。
(2)线程池是如何构造的?
那么平时在Java里写代码的时候,大家记得不记得线程池是如何构造出来的呢?
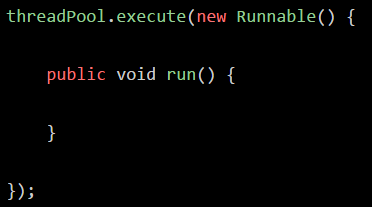
是不是类似下面那样的代码,比如说我们构造一个线程数量固定的一个线程池:

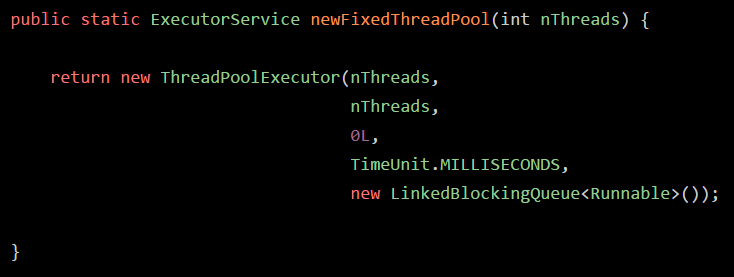
那么Executors.newFixedThreadPool(10)内部到底又是如何构造出来线程池的呢?
其实很简单,翻开JDK源码就可以看到里面的代码如下:
简单来说,就是构造了一个ThreadPoolExecutor对象实例,你大致就认为他是一个线程池吧,传入了一些参数,这些参数大致包含了:
corePoolSize maximumPoolSize keepAliveTime workQueue
假如说我们构造线程池传入的线程数量是10,那么在这里,corePoolSize和maximumSize都是10,keepAliveTime默认就是0,workQueue是一个无界的LinkedBlockingQueue。
接下来,我们具体来看看构造一个线程池传入一些参数之后,具体这个线程池的运行原理是什么。
(3)线程池的运行原理
简单来说,刚开始的时候其实线程池里是空的,就是一个线程都没有的,如下图所示。

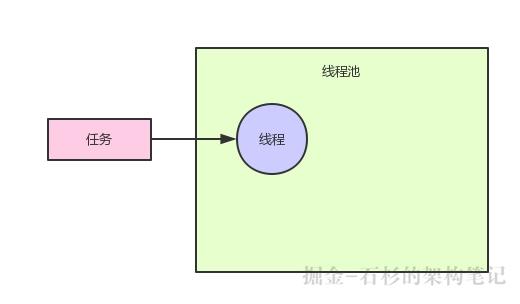
接着如果你使用线程池提交一个任务进去,希望由线程池里的一个线程来执行,如下代码所示,就是提交一个任务:
这个时候,线程池会先看一下,现在池子里的线程数量有没有有达到corePoolSize指定的数量。
现在线程池里的线程数量是0,然后corePoolSize是10,那么肯定没达到了,所以直接会在线程池里创建一个线程出来然后执行这个任务,如下图。
接着假如说,这个线程处理完一个任务了,那么此时线程是不会被销毁的,他会一直等待下一个提交过来的任务。
那么,到底是怎么等待的呢?
很简单,线程池会搭配一个workQueue,比如这里搭配的就是一个无界的LinkedBlockingQueue,几乎可以无限量放入任务。
然后那个线程处理完一个任务之后,就会用阻塞的方式尝试从任务队列里获取任务,如果队列是空的,他就会阻塞卡在那儿不动,直到有人放一个任务到队列里,他才会获取到一个任务然后继续执行,循环往复,如下图。
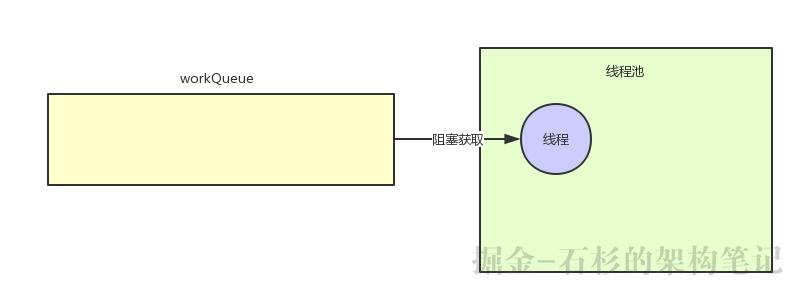
接着再次提交任务,线程池一判断发现,诶?好像线程数量才只有1个,完全比corePoolSize(10个)要小,那么继续直接在池子里创建一个线程,然后处理这个任务,处理完了继续尝试从workQueue里阻塞式获取任务。
一直重复上面的操作,直到线程池里有10个线程了,达到了corePoolSize指定的数量,如下图。
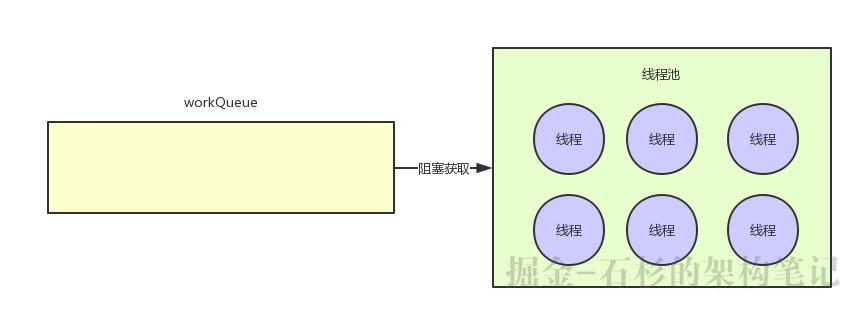
这个时候你如果再提交任务,他一下子发现,诶?不对啊,线程池里已经有10个线程了,跟corePoolSize指定的线程数量一样了。
那么现在,我就不需要创建任何一个额外的线程了,现在你只要提交任务,全部直接入队到workQueue里就好。
此时线程池里的线程都阻塞式在workQueue上等待获取任务,有一个任务进来就会唤醒一个线程来处理这个任务,处理完了任务再次阻塞在workQueue上尝试获取下一个任务,如下图所示这个意思。
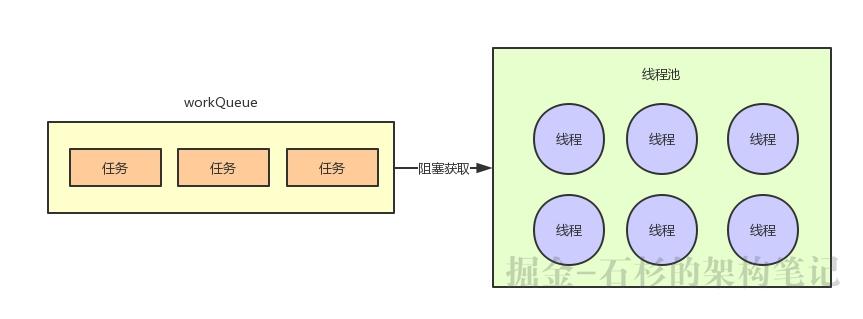
这里我们看到他用的是一个无界的LinkedBlockingQueue,但是假如说他用的是一个有界的队列呢?
比如说限定好了队列最多只能放10个任务,那么假如说,线程池里的线程来不及处理任务了,然后队列一下子放满了10个任务。
此时就会出现任务入队的失败,因为队列满了,无法入队。
然后就会尝试再次在线程池里创建线程,这个时候就会一直创建线程直到线程池里的线程数量达到maximumPoolSize指定的数量为止。
虽然这里fixed线程池默认corePoolSize和maximumPoolSize的数量都是一致的,但是可以假设此时maximumPoolSize的数量是20呢?
那么就会继续创建线程,直到线程数量达到20个,然后用额外创建的10个线程在队列满的情况下,继续处理任务。
整个过程,如下图所示:
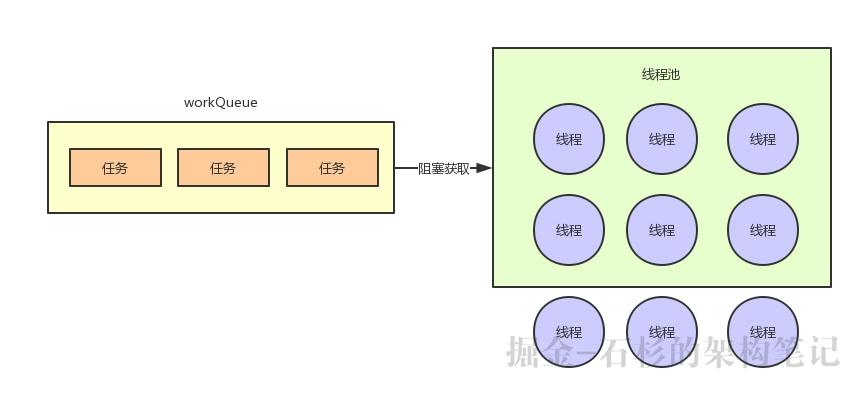
接着万一队列满了,然后线程池的线程数量达到了maximumPoolSize指定的数量了,你额外创建线程都无法创建了,此时会如何呢?
答案是:会reject掉,不让你继续提交任务了,此时默认的就是抛出一个异常。
那么,在上图中额外创建出来的,超出corePoolSize的那些线程呢?
他们一旦创建出来之后,会发现线程池数量已经超过corePoolSize了,此时他们会尝试等待workQueue里的任务。
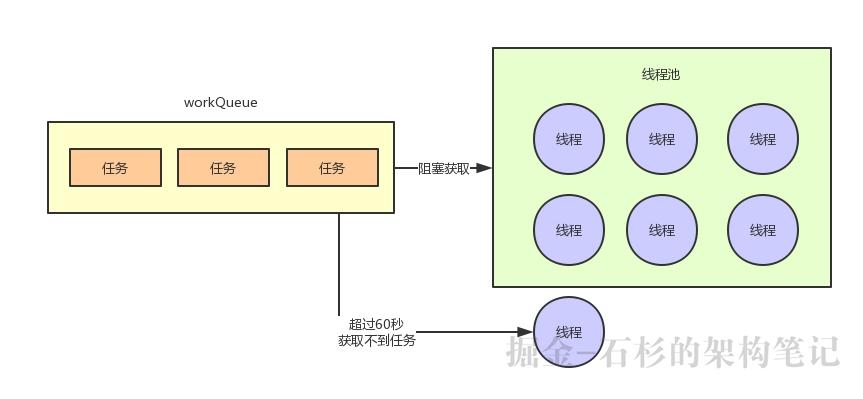
一旦超过keepAliveTime指定的时间,还获取不到任务,比如keepAliveTime是60秒,那么假如超过60秒获取不到任务,他就会自动释放掉了,这个线程就销毁了。
整个过程,如下图所示。
(4)无界队列引发的内存飙升
明白了线程池的运行原理了,这个面试题就好解答了。
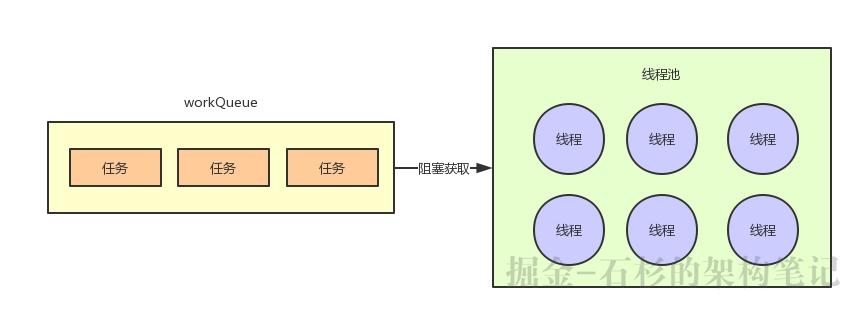
我们以最常用的fixed线程池举例,他的线程池数量是固定的,因为他用的是近乎于无界的LinkedBlockingQueue,几乎可以无限制的放入任务到队列里。
所以只要线程池里的线程数量达到了corePoolSize指定的数量之后,接下来就维持这个固定数量的线程了。
然后,所有任务都会入队到workQueue里去,线程从workQueue获取任务来处理。
这个队列几乎永远不会满,当然这是几乎,因为LinkedBlockingQueue默认的最大任务数量是Integer.MAX_VALUE,非常大,近乎于可以理解为无限吧。
只要队列不满,就跟maximumPoolSize、keepAliveTime这些没关系了,因为不会创建超过corePoolSize数量的线程的。
同样,给大家来一张图,我们来看看:
那么此时万一每个线程获取到一个任务之后,他处理的时间特别特别的长,长到了令人发指的地步。比如处理一个任务要几个小时,此时会如何?
当然会出现workQueue里不断的积压越来越多得任务,不停的增加。
这个过程中会导致机器的内存使用不停的飙升,最后也许极端情况下就导致JVM OOM了,系统就挂掉了。
所以这就是这个面试题背后你要知道的线程池的运行原理,以及可能遇到的一些问题,大家要做到心里有数。
END
扫描下方二维码,备注:“ 资料 ”,获取更多“ 秘制 ” 精品学习资料

如有收获,请帮忙转发,您的鼓励是作者最大的动力,谢谢!
一大波微服务、分布式、高并发、高可用的原创系列文章正在路上
欢迎扫描下方二维码,持续关注:

石杉的架构笔记(id:shishan100)
十余年BAT架构经验倾囊相授
推荐阅读:
1、 拜托!面试请不要再问我Spring Cloud底层原理
2、 【双11狂欢的背后】微服务注册中心如何承载大型系统的千万级访问?
3、 【性能优化之道】每秒上万并发下的Spring Cloud参数优化实战
4、 微服务架构如何保障双11狂欢下的99.99%高可用
5、 兄弟,用大白话告诉你小白都能听懂的Hadoop架构原理
6、 大规模集群下Hadoop NameNode如何承载每秒上千次的高并发访问
7、 【性能优化的秘密】Hadoop如何将TB级大文件的上传性能优化上百倍
8、 拜托,面试请不要再问我TCC分布式事务的实现原理!
9、 【坑爹呀!】最终一致性分布式事务如何保障实际生产中99.99%高可用?
10、 拜托,面试请不要再问我Redis分布式锁的实现原理!
11、 【眼前一亮!】看Hadoop底层算法如何优雅的将大规模集群性能提升10倍以上?
12、 亿级流量系统架构之如何支撑百亿级数据的存储与计算
13、 亿级流量系统架构之如何设计高容错分布式计算系统
14、 亿级流量系统架构之如何设计承载百亿流量的高性能架构
15、 亿级流量系统架构之如何设计每秒十万查询的高并发架构
16、 亿级流量系统架构之如何设计全链路99.99%高可用架构
17、 七张图彻底讲清楚ZooKeeper分布式锁的实现原理
18、 大白话聊聊Java并发面试问题之volatile到底是什么?
19、 大白话聊聊Java并发面试问题之Java 8如何优化CAS性能?
20、 大白话聊聊Java并发面试问题之谈谈你对AQS的理解?
21、 大白话聊聊Java并发面试问题之公平锁与非公平锁是啥?
22、 大白话聊聊Java并发面试问题之微服务注册中心的读写锁优化
23、 互联网公司的面试官是如何360°无死角考察候选人的?(上篇)
24、 互联网公司面试官是如何360°无死角考察候选人的?(下篇)
25、 Java进阶面试系列之一:哥们,你们的系统架构中为什么要引入消息中间件?
26、 【Java进阶面试系列之二】:哥们,那你说说系统架构引入消息中间件有什么缺点?
27、 【行走的Offer收割机】记一位朋友斩获BAT技术专家Offer的面试经历
28、 【Java进阶面试系列之三】哥们,消息中间件在你们项目里是如何落地的?
29、 【Java进阶面试系列之四】扎心!线上服务宕机时,如何保证数据100%不丢失?
30、 一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!
31、 【高并发优化实践】10倍请求压力来袭,你的系统会被击垮吗?
32、 【Java进阶面试系列之五】消息中间件集群崩溃,如何保证百万生产数据不丢失?
33、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(上)?
34、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(中)?
35、 亿级流量系统架构之如何在上万并发场景下设计可扩展架构(下)?
36、 亿级流量架构第二弹:你的系统真的无懈可击吗?
37、 亿级流量系统架构之如何保证百亿流量下的数据一致性(上)
38、 亿级流量系统架构之如何保证百亿流量下的数据一致性(中)?
39、 亿级流量系统架构之如何保证百亿流量下的数据一致性(下)?
40、 互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(1)
41、 互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(2 )
42、 面试大杀器:消息中间件如何实现消费吞吐量的百倍优化?
43、 高并发场景下,如何保证生产者投递到消息中间件的消息不丢失?
44、 兄弟,用大白话给你讲小白都能看懂的分布式系统容错架构
45、 从团队自研的百万并发中间件系统的内核设计看Java并发性能优化
46、 【非广告,纯干货】英语差的程序员如何才能无障碍阅读官方文档?
47、 如果20万用户同时访问一个热点缓存,如何优化你的缓存架构?
48、 【非广告,纯干货】中小公司的Java工程师应该如何逆袭冲进BAT?
49、 拜托,面试请不要再问我分布式搜索引擎的架构原理!
作者:石杉的架构笔记 链接: juejin.im/post/5c263a… 来源:掘金 著作权归作者所有,转载请联系作者获得授权!
正文到此结束
- 本文标签: 注册中心 node 互联网 数据 二维码 http 高并发 Spring cloud Hadoop 压力 UI value core 分布式 并发 源码 线程 系统架构 分布式事务 src id 分布式锁 微服务 java 广告 zookeeper 实例 ThreadPoolExecutor 希望 性能优化 缓存 spring 事故 双11 程序员 executor 工程师 JVM Namenode 时间 锁 queue 一致性 索引 https 集群 代码 volatile 线程池 分布式系统 服务注册 db 搜索引擎 redis 参数 文章 高可用
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

