如何在Hibernate中通过saveAll或EntityManager实现批量插入?
默认情况下,100个插入将导致100个SQL INSERT语句,这很糟糕,因为它导致100次数据库往返。
批处理机制能够使用分组的机制INSERTs,UPDATEs,并DELETEs,作为一个结果,它显著减少数据库往返次数。实现批量插入的一种方法是使用SimpleJpaRepository#saveAll(Iterable< S> entities)方法。在这里,我们用MySQL做到这一点。
关键点:
- 在application.properties中设置spring.jpa.properties.hibernate.jdbc.batch_size
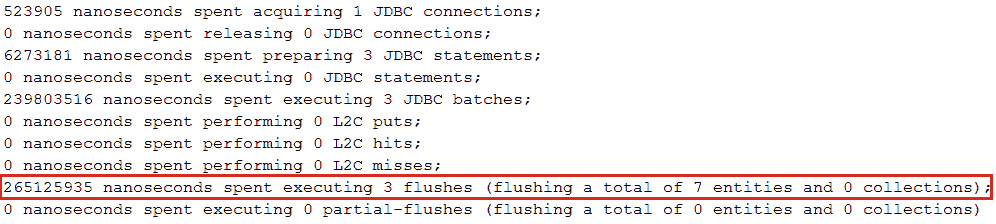
- 在application.properties中设置spring.jpa.properties.hibernate.generate_statistics(只是为了检查批处理是否正常)
- 在application.properties,设置JDBC URL中rewriteBatchedStatements=true (特定于MySQL的优化)
- 在application.properties设置 JDBC URL使用cachePrepStmts=true(启用缓存,如果您决定设置prepStmtCacheSize, 则也很有用prepStmtCacheSqlLimit;等等;如果没有此设置,则禁用缓存)
- 在application.properties设置 JDBC URL中useServerPrepStmts=true(通过这种方式切换到服务器端预处理语句(可能会显着提升性能))
- 在实体中,使用 指定的生成器, 因为MySQL IDENTITY将导致批处理被禁用
- 在实体中,添加@ Version类型的属性Long以避免SELECT在批处理之前额外触发 (还防止在多请求事务中丢失更新)。额外的SELECTs是使用merge()而不是使用的效果persist()。在幕后,saveAll()使用save(),在非新实体(具有ID)的情况下将调用merge(),其指示Hibernate触发SELECT语句以确保数据库中没有具有相同标识符的记录。
- 注意传递给的插入数量saveAll()不要“压倒”持久化上下文。通常情况下,EntityManager应该不时地刷新和清除,但是在saveAll()执行期间,你根本无法做到这一点,所以如果saveAll()有一个包含大量数据的列表,那么所有数据都将达到持久化上下文(第一级缓存)并且在内存中直到到达flush时间。使用相对少量的数据应该没问题。对于大量数据,请查看下一个示例。
源代码可以在 这里 找到 。
通过MySQL(或其他RDBMS)中的JpaContext/EntityManager批量插入
使用批处理应该会提高性能,但在flush之前要注意持久化上下文中存储的数据量。在内存中存储大量数据可能会再次导致性能下降。上面一阶非常适合相对少量的数据。
EntityManager在MySQL(或其他RDBMS)中实现批量插入。这样您就可以轻松控制flush()和clear()持久化上下文(第一级缓存)。这不可能通过Spring Boot,saveAll(Iterable< S>entities)来实现。另一个优点是你可以调用persist()而不是merge(),Spring Boot在saveAll(Iterable< S> entities)和save(S entity)背后使用的方法。
关键点:
- 在application.properties,设置spring.jpa.properties.hibernate.jdbc.batch_size
- 在application.properties,设置spring.jpa.properties.hibernate.generate_statistics(只是为了检查批处理是否正常)
- 在application.properties设置JDBC URL中rewriteBatchedStatements=true (特定于MySQL的优化)
- 在application.properties设置 JDBC URL中使用cachePrepStmts=true(启用缓存,如果您决定设置prepStmtCacheSize, 则也很有用 prepStmtCacheSqlLimit;等等;如果没有此设置,则禁用缓存)
- 在application.properties设置 JDBC URL中useServerPrepStmts=true(通过这种方式切换到服务器端预处理语句(可能会显着提升性能))
- 在实体中,使用 指定的生成器, 因为MySQL IDENTITY将导致批处理被禁用
- 在DAO中,不时刷新并清除持久性上下文。这样,您就可以避免“压跨”持久化上下文。
源代码可以在 这里 找到 。
MySQL中的会话级批处理(Hibernate 5.2或更高版本)
通过MySQL中的Hibernate会话级批处理(Hibernate 5.2或更高版本)批量插入。
关键点:
- 在application.properties中设置spring.jpa.properties.hibernate.generate_statistics(只是为了检查批处理是否正常)
- 在application.properties中设置JDBC URL rewriteBatchedStatements=true(MySQL的优化)
- 在application.properties中设置JDBC URL cachePrepStmts=true(启用缓存,如果你决定则很有用)设置prepStmtCacheSize,prepStmtCacheSqlLimit等等;没有这个设置,缓存被禁用)
- 在application.properties中设置JDBC URL useServerPrepStmts=true(这样你切换到服务器端预处理语句(可能会导致显着的性能提升))
- 如果使用具有级联持久性的父子关系(例如,一对多,多对多)然后考虑spring.jpa.properties.hibernate.order_inserts=true通过排序插入来设置优化批处理
- 在实体中,使用分配生成器,因为MySQL IDENTITY将导致批处理被禁用
- Hibernate Session是通过解包来获得的EntityManager#unwrap(Session.class)
- 批处理大小是通过 DAO 设置Session#setJdbcBatchSize(Integer size)并通过Session#getJdbcBatchSize()
- 在DAO中,不时刷新并清除持久化上下文。这样就可以避免“压倒”持久化上下文。
源码案例这里
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

