JB的测试之旅-jenkins打包产物生成二维码
无风不起浪,为什么会做这个事情,就要由前几天讲起了。。

悲剧了
小公司没有资源,因为很多内测都是用第三方的,这边用的是蒲公英;
在某日早上,开发提测,打包,上传 pgy ,准备给业务方体验的时候,结果点击 查看下载页 按钮,弹出这货;
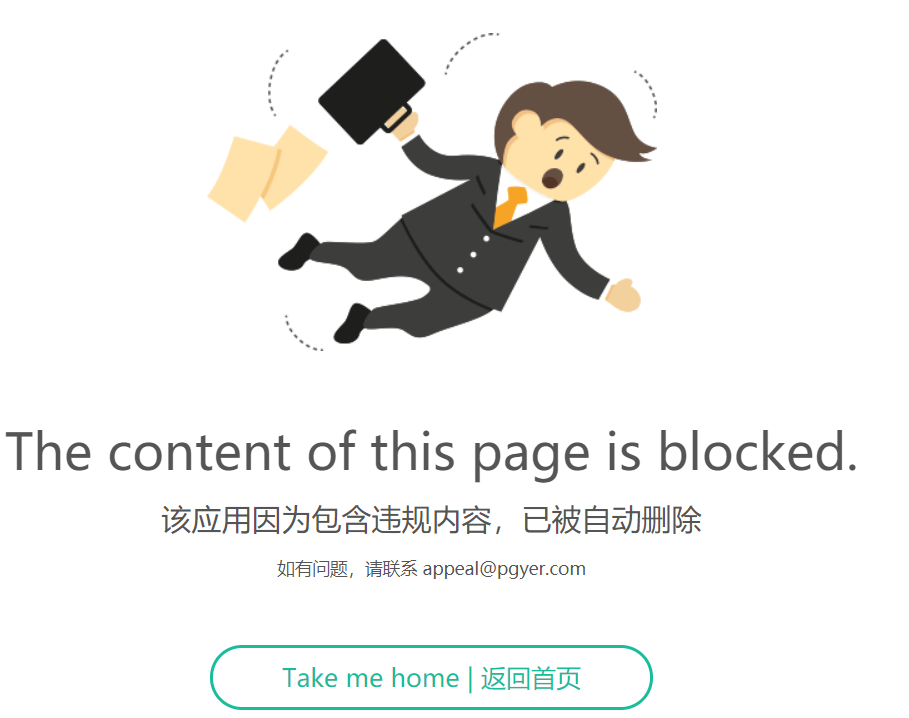
一开始以为是自己手误,然后再上传几次,依然显示这个界面,也没有任何报错信息,懵逼啊,之前都用的好好的,什么鬼?

折腾半天,无望,拿起手机,看到有短信,点开一开,显示这个:
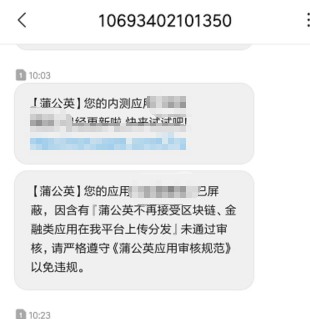
这里面说到不再接受金融类应用在该平台分发,我司产品虽然是资讯类产品,但内容的确是金融相关的,好像没毛病;
操作起来有点麻烦
公司某项目的打包产品是一个zip,是当打包完成后把apk跟ipa压缩成一个zip输出,而使用者需要下载这个zip,解压,电脑连手机/模拟器安装,方可体验;
整个链路过长,也比较麻烦,因此就想着两点:
- 打包拆分,支持安卓、ios分开打包,不然有时候验证一个平台的问题需要打两个包,打包时长成本问题;
- 打包产物显示二维码便捷下载
在正式开始之前,先说明下,testerhome其实有类似的文章,如下图:
对应的文章都写的挺好的,但是轮子嘛,还是要亲力亲为印象才深刻,而且会针对对应文章缺乏的内容进行相应补充,尽可能更加详细把过程写出来;
jenkins显示图片
这里不会再讲述jenkins是什么,怎么安装之类的内容,如果有疑问,请点击此处或第二处查看;
想要做成的效果是这样的:
- 支持修改文件描述
- 支持显示二维码
插件安装
jenkins不支持上面两个操作的,因此需要安装插件来使用;
- Build Name Setter ,用于修改Build名称
- description setter ,用于在修改Build描述信息,在描述信息中增加显示QRCode(二维码)
直接在Jenkins的插件管理页面搜索上述插件,点击安装即可


怎么用
点击对应job的设置界面;
Build Name Setter
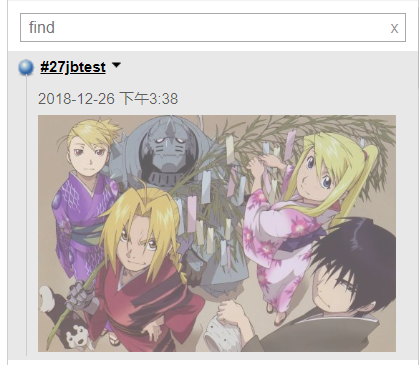
点击 Build Environment ,找到 set build name ,默认是 #${BUILD_NUMBER} ,这里可以自定义,如下修改成 #${BUILD_NUMBER}jbtest ,执行任务后的结果是这样的;
description setter
这个是在 Post-build Actions 里面,将 <img src='qr_code_url'> 写入到build描述信息中即可;
但填写完发现跟预想的不一致,这是因为Jenkins出于安全的考虑,所有描述信息的 Markup Formatter 默认都是采用 Plain text 模式,在这种模式下是不会对build描述信息中的HTML编码进行解析的。
要改变也很容易, Manage Jenkins -> Configure Global Security ,将 Markup Formatter 的设置更改为 Safe HTML 即可。

更改配置后,我们就可以在build描述信息中采用HTML的img标签插入图片了。
<img src="https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=3559712731,2278077975&fm=26&gp=0.jpg" style="background-color: rgb(177, 197, 163); width: 286px; height: 189px;"> 复制代码
保存后,执行任务,会就会显示url对应的图片了;
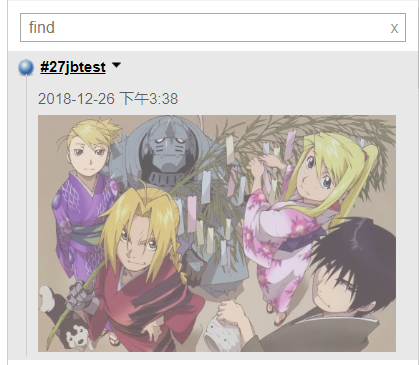
到这里,jenkins上显示图片的问题,就这样解决啦~

小小结
jenkins显示图片及修改任务描述,需要安装两个插件,并且需要传一个图片的img标签过来即可;
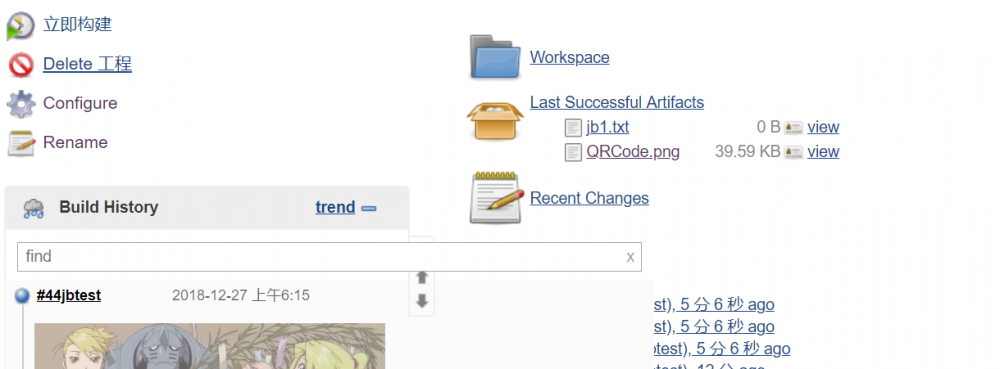
jenkins任务结果收集产物
这里额外提及一个点,如果job里面是有产物的,比如apk等文件,默认构建后是不会显示出来的,如下图:
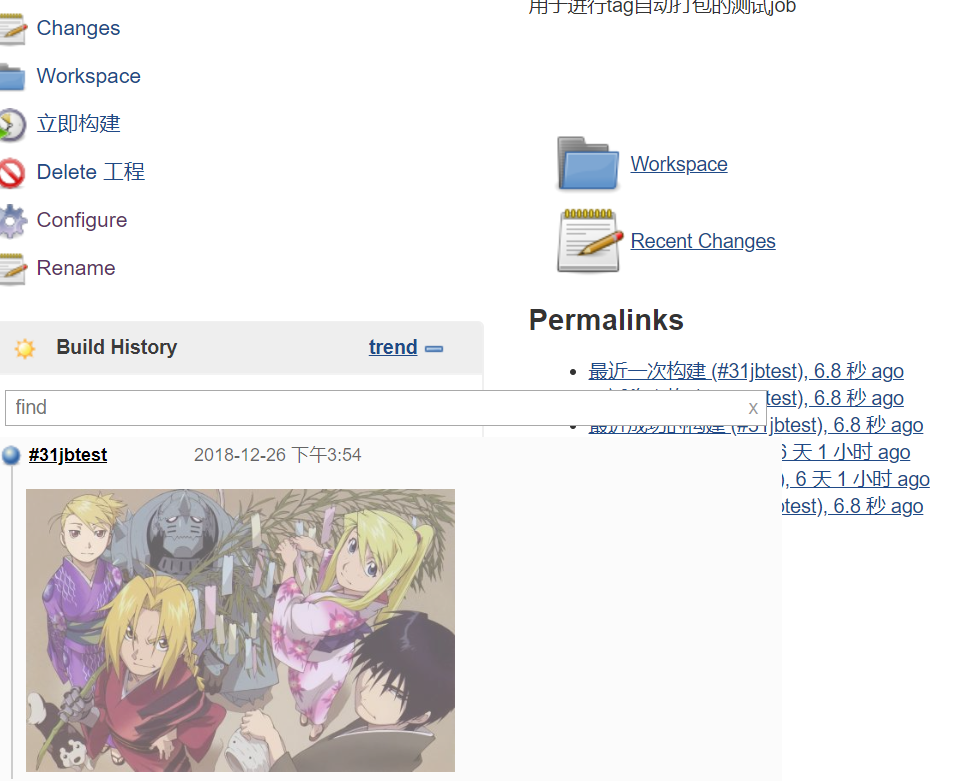
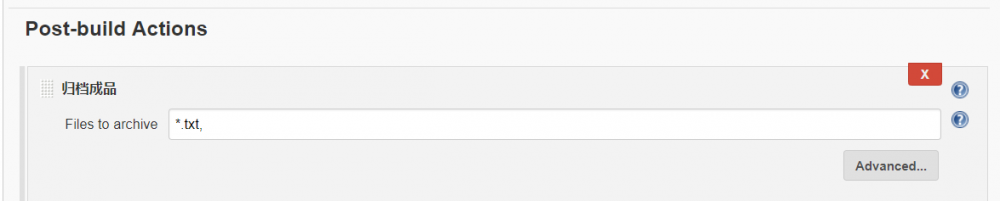
那怎样让其在右侧显示出来?还是打开job的设置项, Post-build Actions ,选择归档成品/Archives build artifacts,在 Files to archive 里面输入内容就好啦;
定位文件时,可以通过正则表达式进行匹配,也可以调用项目的环境变量;多个文件通过 逗号 进行分隔;
${OUTPUT_FOLDER}/*.ipa,*.txt,QRCode.png
#注意,${OUTPUT_FOLDER}是
复制代码
添加后的配置页面如下图所示:
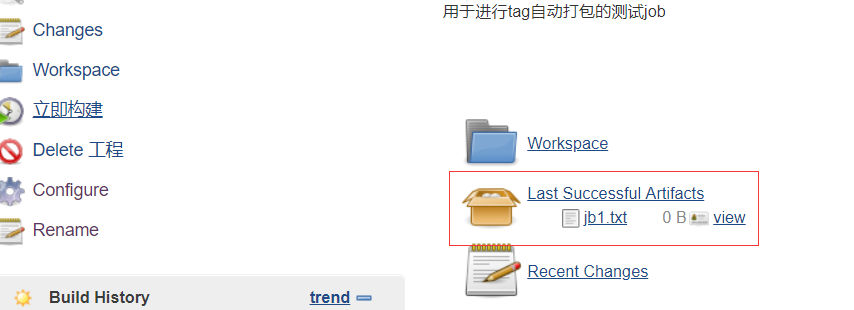
重新构建任务,就可以看到对应的产物啦;
分发平台
首先说明,非广告贴,非广告贴,这节除了介绍分发平台,也会介绍不使用分发平台时怎么搞,任君选择;
上网搜了下,目前国内比较有名且还能用的分发平台,就是蒲公英跟 fir.im
蒲公英
点击上面的地址打开官网,注册登录,点击文档,会有API说明;
简单看了下,支持的功能蛮多的,好像可以,而本章的重点是上传APP,可以搜索框输入 上传APP ,也可以点击链接直接跳转;
仔细看了下response,有二维码地址,good,就是你啦;
常规参数说明
| 参数 | 别称 | 说明 |
|---|---|---|
| _api_key | API Key | API Key,用来识别API调用者的身份,如不特别说明,每个接口中都需要含有此参数。对于同一个蒲公英的注册用户来说,这个值在固定的; |
| userKey | User Key | 用户Key,用来标识当前用户的身份,对于同一个蒲公英的注册用户来说,这个值在固定的; |
| appKey | App Key | 表示一个App组的唯一Key。例如,名称为'微信'的App上传了三个版本,那么这三个版本为一个App组,该参数表示这个组的Key。这个值显示在应用详情--应用概述--App Key。 |
| buildKey | Build Key | Build Key是唯一标识应用的索引ID,可以通过获取App所有版本取得 |
_api_key 跟 userKey 在登录状态下,点击网页的按钮即可获取;
上传App
参数太多了,懒的贴了,直接上代码吧;
Linux
这是官网给的例子, Linux 下直接使用 curl 命令上传即可;
curl -F 'file=@/c/Users/jb/Desktop/jb-android-3.4.1.30402-release-1812251912.apk' -F '_api_key=你的key' https://www.pgyer.com/apiv2/app/upload 复制代码
执行后等待上传完即可:

,就是拿这个给到jenkins那边的;
Python环境,py3
import requests
import sys
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
upload_url = "https://www.pgyer.com/apiv2/app/upload"
_api_key = "你的key"
apk_path = "你要上传的文件路径"
def pgy_uploadFile():
# 获取运行传递过来的参数
# _apk_path = sys.argv[1]
# 上传apk
try:
file = {'file': open(apk_path, 'rb')}
param = {'_api_key': _api_key}
req=requests.post(url=upload_url,files=file,data=param,verify=False)
if (req.status_code == 200):
print(req.json().get("data")["buildQRCodeURL"])
else:
print("上传失败,状态码: "+req.status_code)
except Exception as e:
print("upload:" + e)
if __name__ == '__main__':
pgy_uploadFile()
复制代码
如果是需要传参给脚本,就直接用 sys.argv 来获取,脚本本来没做太多兼容处理,将就用吧;
最后会输出二维码地址,拿这个地址传给jenkins就好啦;

结合jenkins玩玩
上面提及到,jenkins显示二维码是利用img src来处理,但是这个蒲公英返回的二维码地址是每次都不同的呢,那怎么搞?按照常理来说,是把src的值写成变量就好啦;

其实就是写成一个变量就好了,但是也因为url本身每次都变化,因此不能直接贴url,而是把url下载下来,固定下来一个名称,变量直接取这个路径即可;
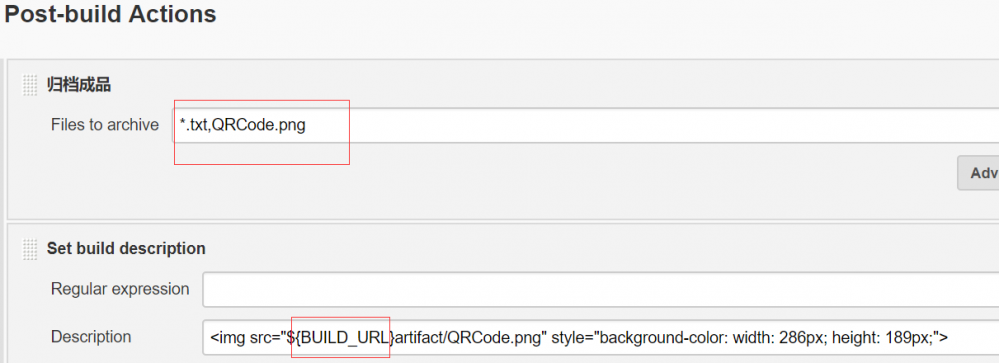
那上面的img标签就会变成这样啦:
<img src="${BUILD_URL}/artifact/QRCode.png" style="background-color: width: 286px; height: 189px;">
# 上面有多余的样式,因为图片是随便复制的,比较大,因此做了下限制,非必选;
复制代码
这里可能有同学会问题,这个 ${BUILD_URL} 是怎么来的,代表什么意思;
${BUILD_URL} 是jenkins的内置变量,代表着显示当前构建的URL地址,文章尾部会列出常用的jenkins变量;
比如上,假如二维码的链接是这样:
jenkineUrl/job/jobName/34/artifact/QRCode.png 复制代码
那么, jenkineUrl/job/jobName/34 这一串就是 ${BUILD_URL}
既然需要图片,那我们就下载图片吧,反正都有url了;
def pgy_doanloadQRCode(QRCodeURL):
print("准备下载二维码")
filename = os.getcwd()+"/QRCode.png"
with open(filename, 'wb') as f:
# 以二进制写入的模式在本地构建新文件
header = {
'User-Agent': '"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",'
, 'Referer': QRCodeURL}
f.write(requests.get(QRCodeURL, headers=header).content)
print("%s下载完成" % filename)
复制代码
结果截图
因pgy需要上传apk或ipa,因为为了方便,直接hardcore了一个图片url来演示结果;
fir.im
点击这里跳转到官网,看了下, 实名认证用户有 100 次/日的免费下载限额,未实名,仅有10次/日的免费下载限额;
一般来说,小公司,每天100次够用啦,除非产品够多,或者打包频繁;
实名好麻烦,还要手持证件照,没关系,反正有10次,够用啦;
然后去看api文章,咦,response居然没有二维码字段?那手动上传一个应用试试看,结果。。

当时心里的疑问就如下图一样,好吧,再见;

小小结
网上找了下分发平台, 国内比较有名且还能用的只剩下蒲公英跟fir.im ,然而fir.im需要实名才能玩,那就剩下蒲公英了,亲自接入下蒲公英,接入比较简单,而且支持的字段也不少,目前来看,比较推荐,省去不少事;
造轮子
此时有同学可能会有疑问,我司产品比较机密,不想用第三方,自己可以造一个轮子吗?

这个问题非常好,没错,可以的,简单想想了,这个轮子需要啥?
- 一个界面,提供上传文件按钮;
- 文件支持点击下载,支持鼠标移动到文件时显示对应的二维码;
- 一台服务器;
想的界面很简单,本来一开始是想着安装个phpstudy就好啦,但是突然想起,前几天看到大佬发了个截图:
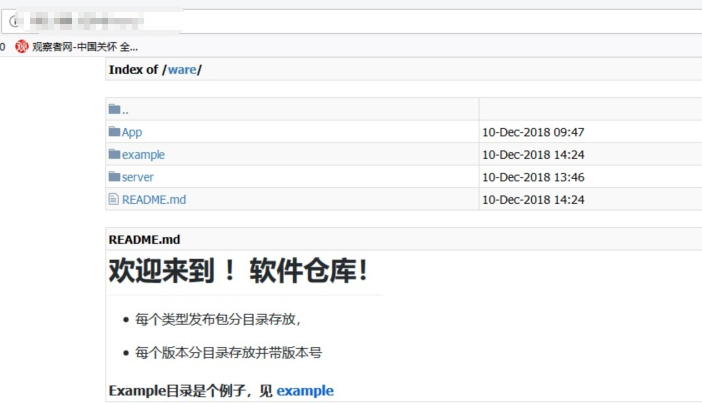
想着差不多,也顺便弄一个仓库呗,比较方便;
但jb不懂这个怎么弄,就跑去问老大了;

听老大说挺简单的,但是啊,jb只听过ng,没真正玩过啊,哪里简单的了,哭;

于是乎就去简单了解ng下了,漫漫人生路;
nginx简单介绍
也许没听过nginx,但是没关系,Apache肯定是听过的,这两者都属于http server,因此,nginx同样是一款开源的HTTP服务器软件;
主要拿来干嘛
- 反向代理
- 负载均衡
- HTTP服务器(包含动静分离)
- 正向代理
反向代理
反向代理应该是Nginx做的最多的一件事了;
什么是反向代理呢,以下是百度百科的说法:
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。简单来说就是真实的服务器不能直接被外部网络访问,所以需要一台代理服务器,而代理服务器能被外部网络访问的同时又跟真实服务器在同一个网络环境,当然也可能是同一台服务器,端口不同而已。 复制代码
下面贴上一段简单的实现反向代理的代码
server {
listen 80;
server_name localhost;
client_max_body_size 1024M;
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host $host:$server_port;
}
}
复制代码
保存配置文件后启动Nginx,这样当我们访问localhost的时候,就相当于访问localhost:8080了;
负载均衡
负载均衡其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。
简单而言就是当有2台或以上服务器时,根据规则随机的将请求分发到指定的服务器上处理,负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载均衡。
HTTP服务器
Nginx本身也是一个静态资源的服务器,当只有静态资源的时候,就可以使用Nginx来做服务器,同时现在也很流行动静分离,就可以通过Nginx来实现,首先看看Nginx做静态资源服务器;
server {
listen 80;
server_name localhost;
client_max_body_size 1024M;
location / {
root e:/wwwroot;
index index.html;
}
}
复制代码
这样如果访问 http://localhost 就会默认访问到E盘wwwroot目录下面的index.html,如果一个网站只是静态页面的话,那么就可以通过这种方式来实现部署。
动静分离
动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路;
upstream test{
server localhost:8080;
server localhost:8081;
}
server {
listen 80;
server_name localhost;
location / {
root e:/wwwroot;
index index.html;
}
# 所有静态请求都由nginx处理,存放目录为html
location ~ /.(gif|jpg|jpeg|png|bmp|swf|css|js)$ {
root e:/wwwroot;
}
# 所有动态请求都转发给tomcat处理
location ~ /.(jsp|do)$ {
proxy_pass http://test;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root e:/wwwroot;
}
}
复制代码
这样就可以吧HTML以及图片和css以及js放到wwwroot目录下,而tomcat只负责处理jsp和请求;
例如当我们后缀为gif的时候,Nginx默认会从wwwroot获取到当前请求的动态图文件返回,当然这里的静态文件跟Nginx是同一台服务器,我们也可以在另外一台服务器,然后通过反向代理和负载均衡配置过去就好了,只要搞清楚了最基本的流程,很多配置就很简单了,另外localtion后面其实是一个正则表达式,所以非常灵活;
正向代理
意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。
nginx常用命令
启动nginx
service nginx start 复制代码
停止nginx
nginx -s stop 复制代码
查看nginx进程
ps -ef | grep nginx 复制代码
平滑启动nginx
nginx -s reload 复制代码
平滑启动的意思是在不停止nginx的情况下,重启nginx,重新加载配置文件,启动新的工作线程,完美停止旧的工作线程。
强制停止nginx
pkill -9 nginx 复制代码
检查对nginx.conf文件的修改是否正确
nginx -t -c /etc/nginx/nginx.conf or nginx -t 复制代码
查看nginx的版本
nginx -v or nginx -V 复制代码
端口开放
因阿里云默认是安装了nginx 1.6版本,因此这块不说明;
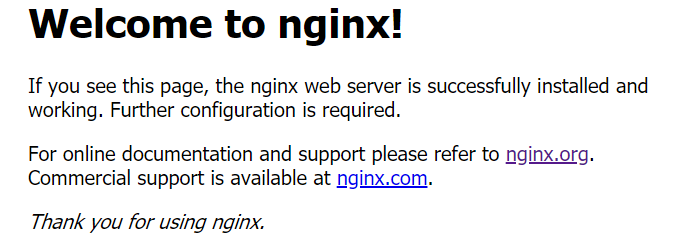
直接在阿里云找到安全组规则,添加对应的对口,就可以用公网IP访问啦;
修改默认端口
因nginx默认是使用80端口的,如果需要修改,需要去配置文件修改;
nginx安装文件在 /etc/nginx ,打开后发现里面有个 nginx.conf ,查看发现里面没有端口信息,但是最后一行插入了 *.conf 文件,那我们就跟着这目录找;
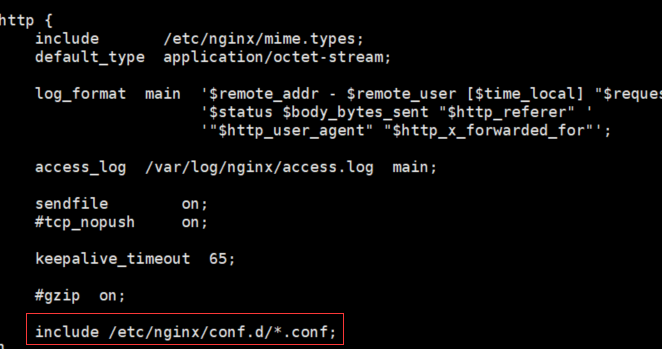
cd 到conf.d目录,发现里面只有一个 default.conf 文件,编辑查看,发现里面有个listen端口,这个就是了,修改成像要的端口,保存即可;
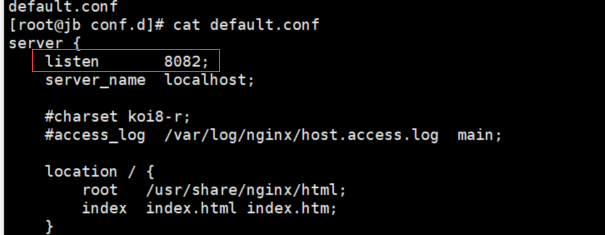
然后输入 nginx -s reload 重启服务器,然后再用公网IP+端口访问下,也会显示 Welcome to nginx!
增加端口
有同学可能问,那想加多几个端口可以吗?
没问题的,还是来到 default.conf 文件,在原来的server下新增一个就好啦,如下:
server {
listen 8083;
server_name location;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /home/file_dir;
autoindex on; #开启nginx目录浏览功能
autoindex_exact_size off; #文件大小从KB开始显示
autoindex_localtime on; #显示文件修改时间为服务器本地时间
add_after_body /autoindex.html;
charset utf-8;
}
复制代码
autoindex
nginx有一个目录浏览功能(autoindex),但是呢,默认是不允许列出整个目录的,如果有需求,就用上面的新增端口的方式来操作就好啦;
而上面这个autoindex.html文件点击下发链接下载即可;
链接:https://pan.baidu.com/s/1oiukkMAILzq9lHwCKzy-0w 提取码:7ytc 复制代码
最后,整个效果如下:
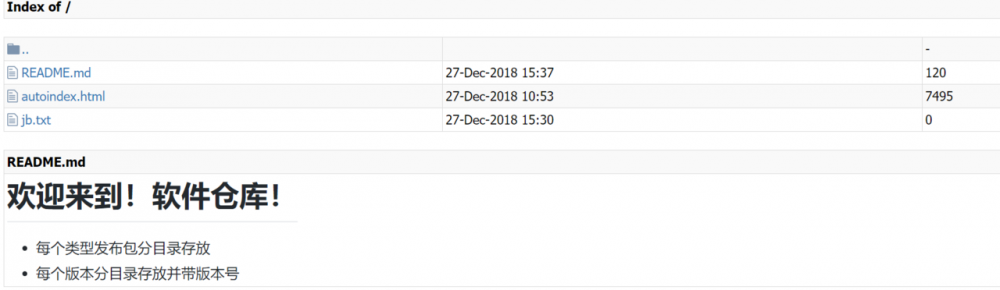
还可以解析 README.md ,骚啊;

root&alias
在弄ng的配置文件时,看到过别人是这样弄的;
location /ware {
alias /lvdata/warehouse/;
复制代码
而自己基本上只会这么弄的:
location / {
root e:/wwwroot;
复制代码
当时心里就想,这两者有什么区别?
简介
nginx指定文件路径有两种方式root和 alias ;
root与alias主要区别在于 nginx如何解释location后面的uri,这会使两者分别以不同的方式将请求映射到服务器文件上。
语法
root的用法
句法: root path; 默认: root html; 语境: http,server,location,if in location 复制代码
示例1:
location ^~ /request_path/dirt/ {
root /local_path/dirt/;
}
复制代码
当客户端请求 /request_path/image/file.ext 的时候,Nginx把请求解析映射为 /local_path/dirt/request_path/dirt/file.ext
实例2:
location ^~ /t/ {
root /www/root/html/;
}
复制代码
如果一个请求的URI是 /t/a.html 时,web服务器将会返回服务器上的 /www/root/html/t/a.html 的文件; alias的用法
句法: alias path; 默认: - 语境: location 复制代码
示例1:
location /request_path/dirt/ {
alias /local_path/dirt/file/;
}
复制代码
当客户端请求 /request_path/dirt/file.ext 的时候,Nginx把请求映射为 /local_path/dirt/file/file.ext 注意这里是file目录,因为 alias 会把 location 后面配置的路径丢弃掉(比如 /request_path/dirt/one.html ,到 alias 那里就剩 one.html 了),把当前匹配到的目录指向到指定的目录。
示例2:
location ^~ /t/ {
alias /www/root/html/new_t/;
}
复制代码
如果一个请求的URI是 /t/a.html 时,web服务器将会返回服务器上的 /www/root/html/new_t/a.html 的文件;
综合例子
location /abc/ {
alias /home/html/abc/;
}
复制代码
在这段配置下, http://test/abc/a.html 就指定的是 /home/html/abc/a.html ;
这段配置亦可改成使用 root 标签:
location /abc/ {
root /home/html/;
}
复制代码
这样,nginx 就会去找 /home/html/ 目录下的 abc 目录了,得到的结果是相同的。
但是,如果把 alias 的配置改成
location /abc/ {
alias /home/html/def/;
}
复制代码
那么 nginx 将会直接从 /home/html/def/ 取数据,例如访问 http://test/abc/a.html 指向的是 /home/html/def/a.html ;
这段配置还不能直接使用 root 配置,如果非要配置,只有在 /home/html/ 下建立一个 def->abc 的 软 link(快捷方式) 了。
一般情况下,在 location / 中配置 root,在 location /other 中配置 alias 是一个好习惯。
其他
-
使用alias时,目录名后面一定要加"/",不然会认为是个文件。
-
alias在使用正则匹配时,location后uri中捕捉到要匹配的内容后,并在指定的alias规则内容处使用。
location ~ ^/users/(.+/.(?:gif|jpe?g|png))$ { alias /data/w3/images/$1; } 复制代码 -
alias只能位于location块中,而root的权限不限于location。
举个例子
你提供地址,当你在家时:
1.朋友想去找你,看到阿姨,阿姨说在家,那朋友得到的是你提供的地址+阿姨说的,这就是root,会把两个地址串起来; 2.班主任想去找你,看到阿姨,阿姨说,你直接跟我说就好了,那班主任得到的就是阿姨说的,这就是alias,会把location后面配置的路径弃掉,把当前匹配到的目录指向到指定目录; 复制代码
当你不在家时(动静分离):
1.(alias)班主任找你的结果不变,结果依然是以阿姨说的为主; 2.(root)因为root是把连个地址串一起的原因,这种情况不太适用,如果非要用root,要在阿姨身上加一个电话,直接call你(软link) 复制代码
上传文件
既然可以访问了,那就写个简单的HTML上传文件吧,关于后端的话,本来想用 php ,毕竟这块网上例子很多,比如这里,都有源码了;
但是呢,毕竟不懂 php ,即使它是最棒的语言,考虑到后面维护麻烦,还是选择用 flask 吧;
直接通过pip命令进行安装即可:
pip install flask 复制代码
官方的一个最简单示例:
# coding=utf-8
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello Flask!"
if __name__ == "__main__":
app.run()
#如果想在公网访问,就修改如下:
#app.run((host='0.0.0.0',port=5000,debug=True))
#直接打开ip:5000就可以了,记得开放端口权限
复制代码
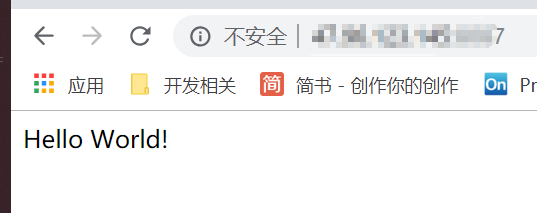
这里不会详细介绍flask,感兴趣的同学可以來官网看看;
对于简单的上传,一般只需要3个步骤:
1. 创建上传表单
<form method="POST" enctype="multipart/form-data">
<input type="file" name="file">
<input type="submit" value="Upload">
</form>
复制代码
2. 获取文件
当点击上传/提交按钮,要获取到上传的文件,通过requests对象中的files就可以获取到啦~
file = request.files['file'] 复制代码
3. 保存文件获取到文件,接着就是保存了,指定路径和文件名;
file.save(path + filename) 复制代码
配置文件
实际在上传文件的时候,会做下限制,比如限制文件大小、文件夹地址、上传文件扩展名等,而在实际项目,还会有密钥、数据库地址等等,这些都是属于配置项;
一般有3种方式:
直接写入脚本
当你脚本是轻量,配置项不多的情况下,可以直接写到脚本里面;
from flask import Flask app = Flask(__name__) app.config['name'] = 'jb' app.config['DEBUG'] = True app.config['age'] = 18 复制代码
当然也可以用字典来简化代码:
from flask import Flask
app = Flask(__name__)
app.config.update(
DEBUG=True,
name='jb',
age=18
)
复制代码
单独配置文件
这种适用于配置项多离的情况,可以创建一个独立的配置文件,如 config.py ;
name = 'jb' DEBUG = True age = 18 复制代码
然后导入配置:
import config ... app = Flask(__name__) app.config.from_object(config) ... 复制代码
或者:
...
app = Flask(__name__)
app.config.from_pyfile('config.py')
...
复制代码
不同的配置类
当需要多个配置配合,比如测试配置、开发配置、运营配置,这时候就需要在配置文件中创建不同的配置类,然后在创建程序实例时引入相应的配置类;
这里继续以 config.py 为例子,创建一个存储通用配置的类;
import os
basedir = os.path.abspath(os.path.dirname(__file__))
class BaseConfig: # 基本配置类
SECRET_KEY = os.getenv('SECRET_KEY', 'some secret words')
ITEMS_PER_PAGE = 10
class DevelopmentConfig(BaseConfig):
DEBUG = True
SQLALCHEMY_DATABASE_URI = os.getenv('DEV_DATABASE_URL', 'sqlite:///' + os.path.join(basedir, 'data-dev.sqlite')
class TestingConfig(BaseConfig):
TESTING = True
SQLALCHEMY_DATABASE_URI = os.getenv('TEST_DATABASE_URL', 'sqlite:///' + os.path.join(basedir, 'data-test.sqlite')
WTF_CSRF_ENABLED = False
config = {
'development': DevelopmentConfig,
'testing': TestingConfig,
'default': DevelopmentConfig
}
复制代码
这里说明下,上面是把配置写入系统环境变量,然后使用os模块的getenv()方法获取,第二个参数作为默认值;
通过from_object()方法导入配置:
from config import config # 导入存储配置的字典 ... app = Flask(__name__) app.config.from_object(config['development']) # 获取相应的配置类 ... 复制代码
那回到这次的功能上,我们只需要写到脚本里面即可;
app.config['UPLOAD_FOLDER'] = os.getcwd() app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024 复制代码
当然还要考虑安全问题,如文件名校验之类的,具体的话,看源码:
import os
from flask import Flask, request, url_for, send_from_directory
from werkzeug import secure_filename
# 文件扩展名
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = os.getcwd()+"/file_upload" #上传地址
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024 #文件大小,单位N
html = '''
<!DOCTYPE html>
<title>Upload File</title>
<h1>图片上传</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=上传>
</form>
'''
# 检查文件类型
def allowed_file(filename):
return '.' in filename and /
filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
# 获取上传后的文件
@app.route('/uploads/<filename>')
def uploaded_file(filename):
return send_from_directory(app.config['UPLOAD_FOLDER'],
filename)
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
file = request.files['file']
#判断上传文件名
if file and allowed_file(file.filename):
# 检查文件名
filename = secure_filename(file.filename)
#如果目录不存在则创建
if not os.path.exists(app.config['UPLOAD_FOLDER']):
os.mkdir(app.config['UPLOAD_FOLDER'])
# 保存图片
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
# 获取url
file_url = url_for('uploaded_file', filename=filename)
return html + '<br><img src=' + file_url + '>'
return html
if __name__ == '__main__':
app.run(host='0.0.0.0',port=8087,debug=True)
复制代码
这里说个小事情,一开始执行上面的代码,会报错:

网上找了下,原因是 在Subline3遇到的都是看似空格实则没有空格引起的::
解决方法: 就是打开subline的空格制表显示就可以清楚的显示出自己是否真的空格了。
第一次遇到这问题,详情请点击这里查看;
执行脚本,上传文件,上传的文件就是在 file_upload 目录下的;

功能是有的,就是界面low了点。。
身为一个测试同学,对UI肯定要有点追求,并且希望可以提供下载,因此就上网找了个插件,点击 这里 ,看看github上的截图:
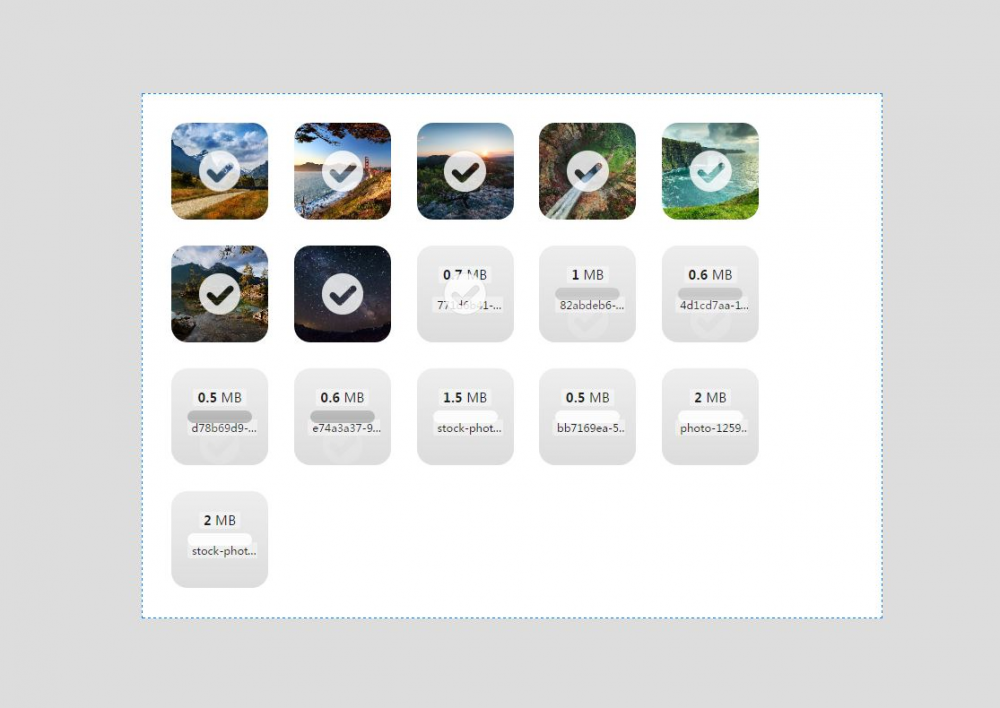
听漂亮的,这样上传就有了进度,并且支持多文件上传,但依然会有个问题,上传完去哪里看?想下载怎么办?

这里想说一个问题,上面的例子,如果大家有细心看的话,会发现上传的文件都会去到一个叫 file_upload 文件夹,上传是没问题的,但是下载就有问题了;
jb在下载的时候,不管这个下载地址怎么拼,页面都会无情报错,说这个地址不存在;
但是呢,如果把上传目录修改成 static ,却是正常的; 包括如果这个 static 不在根目录,也一样有问题,那为什么当 static 是根目录且放到这里面就这样?
Flask资源定位是依靠
app = Flask(__name__) 复制代码
__name__ 参数(文件名或包名),所以相对定位一定要基于这个文件路径。
为什么会在static文件夹路径下会正确**?Flask默认静态文件在static文件下。**
那如果一定要上传到 file_upload 文件夹,怎么办?
那就修改的flask默认的static文件夹只需要在创建Flask实例的时候,把 static_folder 和 static_url_path 参数设置为 空字符串 即可。
app = Flask(__name__, static_folder='', static_url_path='') 复制代码
访问的时候用url_for函数,res文件夹和static文件夹同一级:
url_for('static', filename='res/sheeta.jpg')
复制代码
最终就成了这样:
<img src ="/file_upload/a.png">
//或者
<img src = "{{ url_for('file_upload', filename = 'a.png') }}>
复制代码
good,问题搞定了,体验下:
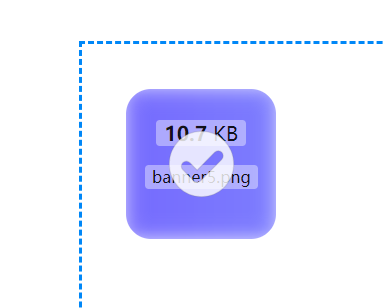
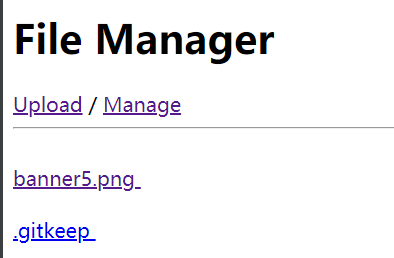
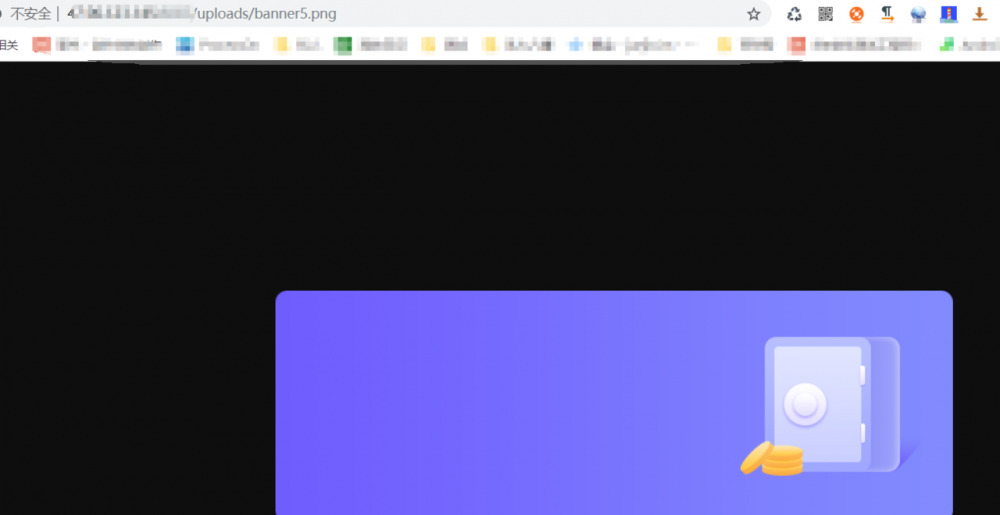
搞定,那接着就是生成二维码;
生成二维码
支持点击打开/下载,那如果是上传apk/ipa那就麻烦了,jenkins那边,所以还是希望能生成一个二维码;
而Python生成二维码的话,有qrcode,同时也需要处理下二维码图片,因此需要安装 qrcode 、 pillow :
pip install qrcode pip install pillow 复制代码
最简单的demo:
import qrcode
qr = qrcode.QRCode(version=2, error_correction=qrcode.constants.ERROR_CORRECT_L, box_size=10, border=1)
qr.add_data("我是jb啊~")
qr.make(fit=True)
img = qr.make_image()
img.save("jb_qrcode.png")
复制代码
这里面是有一些参数的,但是边幅原因,请各自去了解;
这时候就生成一个二维码了,但是呢,上面的demo图片太小了,而且想弄个定制化的二维码,怎么破?不细说,直接源码拿走不谢~
# 生成二维码
def get_QRCode(filename):
#检测目录的方法,不存在则创建
checkdir(存放二维码目录路径)
# 初步生成二维码图像
qr = qrcode.QRCode(
version=5,
error_correction=qrcode.constants.ERROR_CORRECT_H,
box_size=8,
border=4
)
# 二维码存放的内容,可文案,可链接
qr.add_data("二维码路径")
qr.make(fit=True)
# 获得Image实例并把颜色模式转换为RGBA
img = qr.make_image()
img = img.convert("RGBA")
# 打开logo文件
icon = Image.open("定制的logo")
# 计算logo的尺寸
img_w,img_h = img.size
factor = 4
size_w = int(img_w / factor)
size_h = int(img_h / factor)
# 比较并重新设置logo文件的尺寸
icon_w,icon_h = icon.size
if icon_w >size_w:
icon_w = size_w
if icon_h > size_h:
icon_h = size_h
icon = icon.resize((icon_w,icon_h),Image.ANTIALIAS)
# 计算logo的位置,并复制到二维码图像中
w = int((img_w - icon_w)/2)
h = int((img_h - icon_h)/2)
icon = icon.convert("RGBA")
img.paste(icon,(w,h),icon)
# 保存二维码
img.save(os.path.join(二维码路径, filename))
复制代码
可以直接拿来复用,需要修改的也就几个参数,简单便捷,效果图如下:

其他小系列
在处理过程,遇到一些小问题,简单罗列下;
中文名称被吃了
是这样的,如果一个文件里面有中文,比如 消息.jpg ,把这个地址塞到二维码,然后扫描,会这样的:

中文不见了。。如果是英文或字母,都很正常,另外,如果是用浏览器扫描,也都没问题,就微信会这样;
很简单,encode下就好了;
编码:
from urllib.parse import quote text = quote(text, 'utf-8') 复制代码
解码:
from urllib.parse import unquote text = unquote(text, 'utf-8') 复制代码
这样后,就能在微信打开啦~
ios不能直接下载ipa包
来到这里,主路径都是通的,二维码也是可以生成的,用android手机试下,没问题,可以在线预览图片或者下载文件;
但是用ios手机扫描 ipa包 的链接,结果不会像安卓那样下载ipa包安装,而是load半天,然后这样显示:
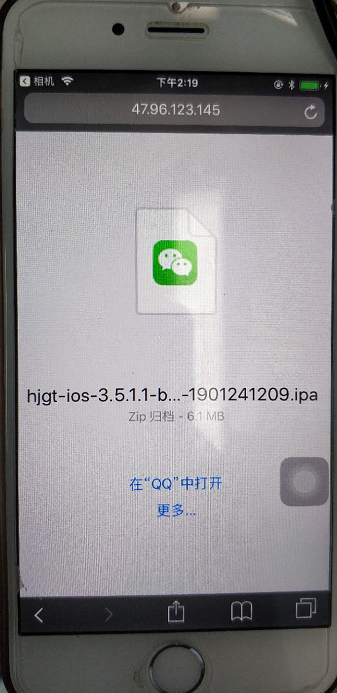
???这跟剧本不一样啊;
网上找了下,很多这样的例子,这里参考的是这里,
大致的步骤就是:
- 准备plist、ipa包、icon、HTMLdemo;
- plist上传到https地址;
- HTML里面加一个点击事件;
原理:
是通过Safari解析链接中的"itms-services://"来实现的。 例如: <a title="iPhone" href="itms-services://?action=download-manifest&url=https://192.168.10.193/installIPA.plist"> Iphone Download</a> Safari会去读取installIPA.plist中的信息,如:iOS应用的名称、版本、安装地址等。 复制代码
test.html
<!DOCTYPE html>
<html lang="en">
<head>
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/layer/2.3/layer.js"></script>
<title>File Manager</title>
</head>
<body>
<h1>File Manager</h1>
<div id="btnContainer">
<a id="btnA" href="itms-services://?action=download-manifest&url=你的plist地址,必须要https,不然会提示签名无效">
<span id="btnSpan2">v1.1.2</span>
</a>
</div>
</html>
复制代码
这里的href是填入 plist 的地址,必须要 https ,原因是 iOS7.1 以后, Apple不再支持 HTTP 方式的OTA ,所以需要开启 HTTPS 服务,不然会提示无效证书;
test.plist
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>items</key>
<array>
<dict>
<key>assets</key>
<array>
<dict>
<key>kind</key>
<string>software-package</string>
<key>url</key>
<string>ipa包地址</string>
</dict>
</array>
<key>metadata</key>
<dict>
<key>bundle-identifier</key>
<string>包名</string>
<key>bundle-version</key>
<string>版本号</string>
<key>kind</key>
<string>software</string>
<key>subtitle</key>
<string>应用名称</string>
<key>title</key>
<string>应用名称</string>
</dict>
</dict>
</array>
</dict>
</plist>
复制代码
因篇幅问题,只留必备项,只输入填入 ipa 包地址,底部那块元数据信息即可;
最终的结果就是这样啦:

主流程总算通了,深呼一口气;
这里说明下,如果没有https,测试的话,可以试试上传的 github ,这里是https的;
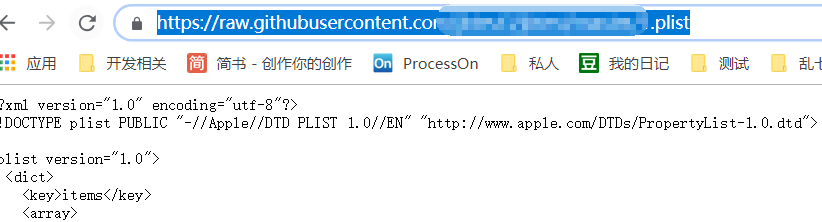
当长期考虑,还是要弄一个,公司有就用公司的,公司没有就自己买一个,jb是用aly,所以也在aly买了个,有兴趣的同学点击这里 ,购买、认证、解析、申请证书,就可以了,这块不说明,感兴趣的可自行上网查询,
这里演示的是demo,因此url都是hardcore的,实际还要处理 plist 的路径等,上传一个 ipa 就生成一个 plist ,这块自行处理吧;
源码
链接:https://pan.baidu.com/s/1SFFtGJHmUHhpqq2MwwhpXw 提取码:2hdd 复制代码
源码在此,就不再单独解释了,可能会有一些问题,但是模型大致就这样啦,因时间问题,年后再优化,反正就是缺什么就import什么就好了;
小结
本文折腾很久,主要是因为重新看回 flask 跟学习下 ng ,以及ios的解决方案,外加年底工作很繁忙,因此陆陆续续折腾了快半个月的时间,本来还想把所有优化都做好再放出来,但怕开年后更加忙了,那这文章就烂尾了,因此就先发出来了;
本文涉及到的内容比较多,包括 jenkins如何显示图片 、 pgy分发平台的使用 、 自己搭一个文件上传的轮子 ,涉及到的只是有 ng 、 flask ,都是比较简单的内容,但是是否做过是两回事,从小白的角度出发来落地;
体验地址点击这里,如果服务器没挂的话,打开是这样的;
如果有更好的方案,欢迎一起交流~
最后,大家新年快啦~一路顺风,明年见~
最后的最后,谢谢大家~
这里还有一节,主要是介绍下jenkins的内置变量,感兴趣的同学可以看看~
jenkins内置变量
邮件的配置变量
| 变量名 | 说明 |
|---|---|
${GIT_BRANCH} |
build 的 Git 分支; |
${FILE,path="xxx"} |
xxx 为指定的文件,文件内容可以在邮件中显示。注意:xxx 是工作区目录的相对路径; |
${JOB_DESCRIPTION} |
显示项目描述; |
${BUILD_NUMBER} |
显示当前构建的编号; |
${SVN_REVISION} |
显示 svn 版本号; |
${CAUSE} |
显示谁、通过什么渠道触发这次构建; |
${CHANGES} |
显示上一次构建之后的变化; |
${BUILD_ID} |
显示当前构建生成的ID; |
${PROJECT_NAME} |
显示项目的全名; |
${PROJECT_DISPLAY_NAME} |
显示项目的显示名称; |
${JENKINS_URL} |
显示 Jenkins 服务器的 url 地址(可以在系统配置页更改); |
${BUILD_LOG_MULTILINE_REGEX} |
按正则表达式匹配并显示构建日志; |
${BUILD_LOG} |
显示最终构建日志; |
${PROJECT_URL} |
显示项目的URL地址; |
${BUILD_STATUS} |
显示当前构建的状态(失败、成功等等); |
${BUILD_URL} |
显示当前构建的URL地址; |
${CHANGES_SINCE_LAST_SUCCESS} |
显示上一次成功构建之后的变化; |
${CHANGES_SINCE_LAST_UNSTABLE} |
显示显示上一次不稳固或者成功的构建之后的变化; |
${ENV} |
显示一个环境变量; |
${FAILED_TESTS} |
如果有失败的测试,显示这些失败的单元测试信息; |
${PROJECT_URL} |
显示项目的 URL; |
${TEST_COUNTS} |
显示测试的数量; |
环境变量
| 变量名 | 说明 |
|---|---|
BRANCH_NAME |
设置为正在构建的分支的名称; |
CHANGE_ID |
更改ID,例如拉取请求号; |
CHANGE_URL |
设置为更改URL; |
CHANGE_TITLE |
设置为更改的标题; |
CHANGE_AUTHOR |
设置为拟议更改的作者的用户名; |
CHANGE_AUTHOR_DISPLAY_NAME |
设置为作者的人名; |
CHANGE_AUTHOR_EMAIL |
设置为作者的电子邮件地址; |
CHANGE_TARGET |
设置为可以合并更改的目标或基本分支; |
BUILD_NUMBER |
目前的编号,如“153”; |
BUILD_ID |
当前版本ID,与BUILD_NUMBER相同; |
BUILD_DISPLAY_NAME |
当前版本的显示名称; |
JOB_NAME |
此构建项目的名称,如“foo”; |
JOB_BASE_NAME |
此建立项目的名称将剥离文件夹路径,例如“bar”。 |
BUILD_TAG |
jenkins- JOBNAME− {BUILD_NUMBER} 的字符串; |
EXECUTOR_NUMBER |
识别执行此构建的当前执行程序(在同一台计算机的执行程序中)的唯一编号; |
NODE_NAME |
代理的名称; |
NODE_LABELS |
空格分隔的节点分配的标签列表; |
WORKSPACE |
分配给构建作为工作区的目录的绝对路径; |
JENKINS_HOME |
Jenkins主节点上分配的目录绝对路径存储数据; |
JENKINS_URL |
完整的Jenkins网址,如 http://server:port/jenkins/ ; |
BUILD_URL |
此构建的完整URL,如 http://server:port/jenkins/job/foo/15/ ; |
JOB_URL |
此作业的完整URL,如 http://server:port/jenkins/ job/foo/ ; |
SVN_REVISION |
Subversion版本号,当前已被检出到工作区,如“12345”; |
SVN_URL |
当前已经检出到工作空间的Subversion URL; |
正文到此结束
- 本文标签: SQLite tab Service ip id grep Agent cat 金融 FIT App XML 软件 ftp logo 公网IP root 免费 认证 Action SVN 希望 tar 正向代理 产品 配置 API CTO json 插件 企业 正则表达式 ask PHP 下载 源码 Property tomcat MQ 反向代理 文案 安装 管理 空间 实例 二维码 开源 linux 运营 web 文章 测试 HTTP服务器 mail IO CDN 缓存 进程 sql CSS Apple HTML文件 文件上传 百度 core apache python 定制 Security jenkins 图片 负载均衡 Proxy 线程 部署 安全 IDE 时间 parse Chrome 开发 src zip ACE 服务器 Job node executor js 索引 广告 tag 密钥 数据 需求 解析 list 解决方法 lib update FTP服务 IOS 端口 ORM https bug 数据库 stream 标题 UI 代码 Android value 参数 client 目录 Word kk windows constant git 模型 description 单元测试 网站 jquery GitHub HTML key 阿里云 build 云 http Nginx
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

