翻译 | 理解Java中的内存泄漏
Java 的其中一个核心特点是经由内置的垃圾回收机制(GC)下的自动化内存管理。GC 默默地处理着内存分配和释放工作因此能够处理大部分内存泄漏问题。
虽然 GC 能够有效地理一大部分内存,但他不保证能处理所有内存泄漏情况。GC 十分智能,但并不完美。即使是在谨慎的程序员所开发的应用程序下内存泄漏依旧会悄悄地出现。
应用程序仍然会出现产生大量的多余的对象的情况,因此耗尽了所有关键的内存块资源,有时候还会导致应用程序崩坏。
内存泄漏是 Java 中的一个永恒的问题。在这篇文章中,我们将会讨论 内存泄漏的潜在原因,怎么在运行时识别它们并且怎么在应用程序中解决它们 。
2. 什么是内存泄漏
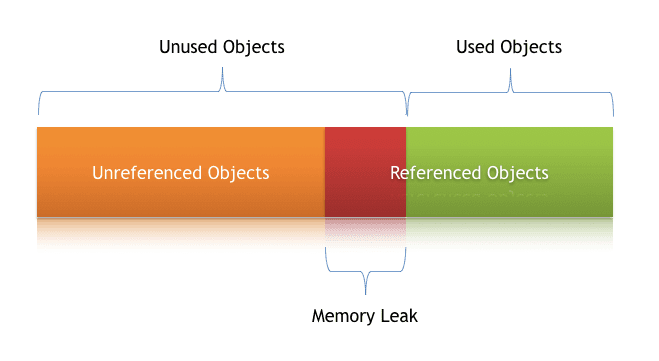
内存泄漏是指这么一种情况, 当存在对象在堆中不再被使用,但垃圾回收器无法从内存中移除它们 并且因此变得不可被维护。
内存泄漏十分不好因为它锁住了部分内存资源并且逐渐降低系统的性能。并且如果无法处理它,应用程序最终会耗尽所有资源最终产生一个致命的错误 -- java.lang.OutOfMemoryError 。
这里有两种不同类型的对象存在于堆内存中,被引用的以及未被引用的。被引用的对象是指那些在应用程序中仍然被主动使用的而未被引用的对象是指那些不在被使用的。
垃圾回收器会定期清除未被引用对象,但从来都不收集那些仍然被引用的对象。这就是内存泄漏发生的其中一个原因:
内存泄漏的症状:
- 当应用程序持续长时间运行导致服务器性能的严重下降
- 应用程序中的堆异常 OutOfMemoryError
- 自发以及奇怪的程序崩溃
- 程序偶然耗尽连接对象
让我们关注下这些场景并且研究下它们为什么会发生。
3. Java 中内存泄漏的类型
在任何的程序当中,内存泄漏能由几种原因引起。在这节,我们来讨论下最常见的一种。
3.1. 静态字段导致的内存泄漏
第一种可能导致内存泄漏的情况是大量使用静态字段。
在 Java,静态字段的生命周期通常和运行的应用程序的整个生命周期相匹配(除非 类加载器 有资格进行垃圾回收)
让我们创建一个填充了静态 list 的简单 Java 程序:
public class StaticTest {
public static List<Double> list = new ArrayList<>();
public void populateList() {
for (int i = 0; i < 10000000; i++) {
list.add(Math.random());
}
Log.info("Debug Point 2");
}
public static void main(String[] args) {
Log.info("Debug Point 1");
new StaticTest().populateList();
Log.info("Debug Point 3");
}
}
复制代码
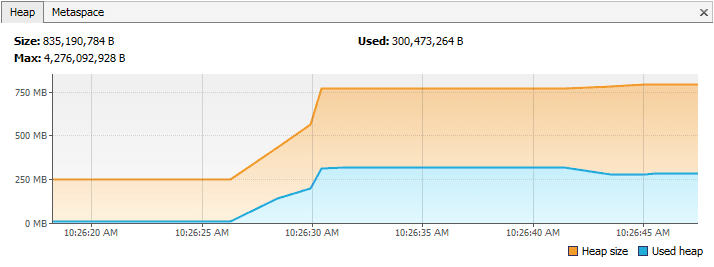
现在如果我们在程序运行过程中分析堆内存,可以看到在调试点1和2之间,正如预期所想的那样,堆内存的使用增加了。
但是当我们在调试点3跳出了 populateList() 方法,在 VisualVM 可以看到,堆内存仍然未被回收:
然而,在上述的程序当中,如果我们在第二行把关键字 static 去掉的话,内存使用将会发生一个剧烈的变化,在 VisualVM 可以看到:
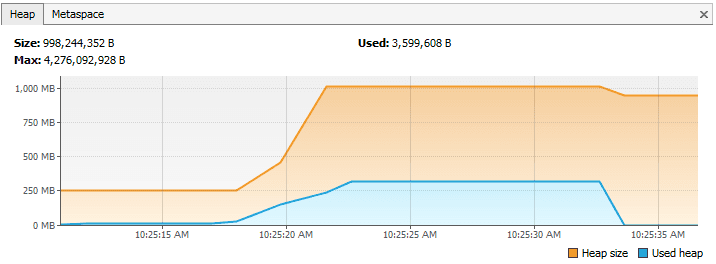
调试点的第一部分和存在 static 的例子差不多一样。但这次在跳出 populateList() 之后,list 所使用的内存全部被回收了因为我们不再引用它了。
因此使用 static 变量时我们需要留意了。如果集合或者大对象被声明为 static ,那么它们在应用程序的整个生命周期中都保留在内存中,因此锁住了那些原本可以用在其他重要地方的内存。
怎么预防这种情况发生呢?
- 尽量减低 static 变量的使用
- 使用单例模式时,使用延迟加载而非立即加载
3.2. 未关闭资源导致的内存泄漏
当我们产生新的连接或者开启流的时候,JVM 会为它们分配内存,像数据库连接、输入流或者会话对象等等。
忘记关闭流能导致内存被锁,从而它们也无法被回收。这甚至会出现在那些阻止程序执行关闭资源的语句的异常中。
不论哪种情况,资源产生的连接都会消耗掉内存,并且如果不处理它,会降低性能和导致 OutOfMemoryError 。
怎么预防这种情况发生呢?
- 始终使用 finally 块来关闭资源
- 关闭资源的代码块(包括 finally 块)自身不能带有异常
- 当使用 Java 7或更高版本,可以使用 try -with-resources 语法
3.3. 不当的 equals() 和 hashCode() 实现
当定义新类的时候,一种非常常见的疏忽是没有正确编写 equals() 和 hashCode() 的重写实现方法。
HashSet 和 HashMap 在许多操作当中使用这两个方法,如果我们没有合理地重写它们,会导致潜在的内存泄漏问题。
让我们以一个简单的 Person 类为例,并且将其作为一 HashMap 中的键:
public class Person {
public String name;
public Person(String name) {
this.name = name;
}
}
复制代码
现在我们在 Map 当中作为键插入相同的 Person 对象。
请记住 Map 并不能存在相同的键:
@Test
public void givenMap_whenEqualsAndHashCodeNotOverridden_thenMemoryLeak() {
Map<Person, Integer> map = new HashMap<>();
for(int i=0; i<100; i++) {
map.put(new Person("jon"), 1);
}
Assert.assertFalse(map.size() == 1);
}
复制代码
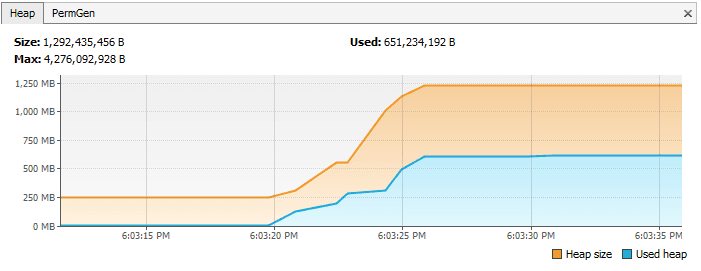
这里我们将 Person 作为键,由于 Map 不允许重复键,所以作为键插入的大量重复的 Person 应当不会增加内存的消耗。
但是由于我们没有正确地定义 equals() 方法,重复的对象会堆积起来并且增加内存消耗,这就是为什么在内存中能看到超过一个对象。VisualVM 的堆内存就像下图所示:
但是,如果我们正确地重写 equals() 和 hashCode() 方法,那么 Map 中只会存在一个 Person 对象。
让我们看下 Person 类中正确的 equals() 和 hashCode() 实现:
public class Person {
public String name;
public Person(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof Person)) {
return false;
}
Person person = (Person) o;
return person.name.equals(name);
}
@Override
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
return result;
}
}
复制代码
在这种情况下,下面的断言是正确的:
@Test
public void givenMap_whenEqualsAndHashCodeNotOverridden_thenMemoryLeak() {
Map<Person, Integer> map = new HashMap<>();
for(int i=0; i<2; i++) {
map.put(new Person("jon"), 1);
}
Assert.assertTrue(map.size() == 1);
}
复制代码
在通过正确的 equals() 和 hashCode() 方法后,相同程序的堆内存是这样的:
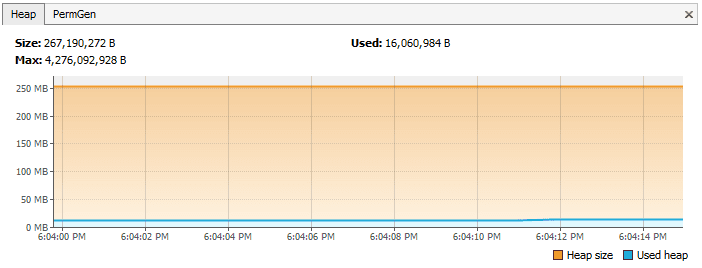
另外一个使用像 Hibernate 这样的 ORM 框架的例子中,它使用 equals() 和 hashCode() 方法分析对象并将它们保存在缓存中。
如果这些方法不被重写发生内存泄漏的几率会变得非常大,因为 Hibernate 无法比较对象并且会将重复的对象填充到缓存当中。
怎么预防这种情况发生呢?
- 根据经验,在定义新实体的时候,总是要重写 equals() 和 hashCode() 方法
- 仅仅重写还不够,还需要以最佳的方式来处理它们
3.4. 引用外部类的内部类
这种情况发生在非静态内部类(匿名类)当中。对于初始化,这些内部类总是需要一个封闭类的实例。
默认情况下,每个非静态内部类都有对其包含类的隐式引用。如果我们在程序当中使用这种内部类对象,即使包含类对象超出了作用域,它仍然不会被回收。
思考有一个类中包含大量大对象的引用以及一个非静态内部类。现在当我们创建一个内部类对象时,内存模型是这样的:
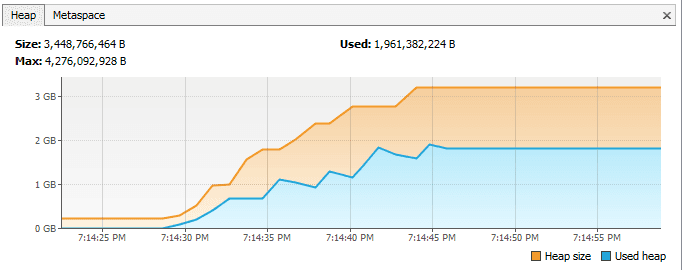
然而,如果我们定义这个内部类为静态,现在内存模型是这样的:
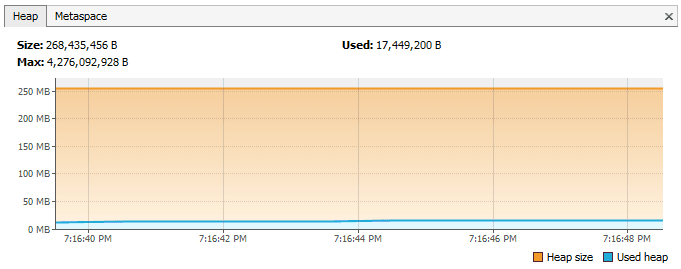
会发生这种情况的原因是内部类对象隐含着外部类对象的引用,从而它不能被垃圾回收所识别。匿名类同样如此。
怎么预防这种情况发生呢?
- 如果内部类不需要访问包含的类的成员,考虑将它定义为静态类
3.5.finalize()方法导致的内存泄漏
使用 finalizer 是另一个潜在内存泄漏问题的来源。每当类中的 finalize() 方法被重写, 那么该类的对象不会马上被回收 。相反,它们将会延后被 GC 放到队列当中序列化。
此外,如果编写的 finalize() 并非最优并且如果序列化队列跟不上 GC 的速度的话,那么,应用程序迟早会发生 OutOfMemoryError 异常。
为了演示这点,让我们假设我们已经有一个重写了 finalize() 方法的类并且这方法需要花费额外的一些时间来执行。当该类的大量对象被回收,VisualVM 是这样的:
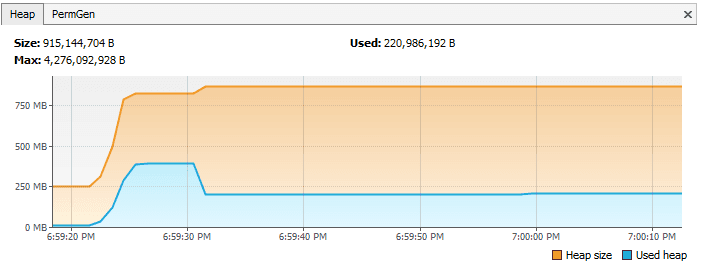
然而,如果我们仅仅是移除 finalize() 方法,同一个程序给出以下的响应:
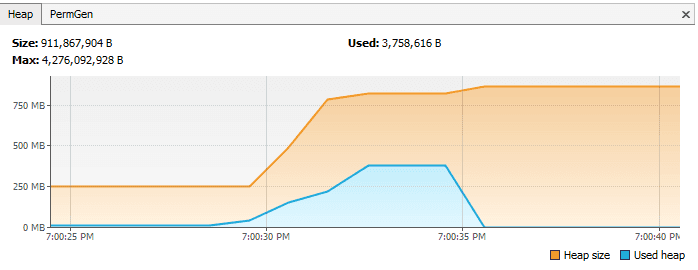
怎么预防这种情况发生呢?
- 我们应该尽量避免序列化
3.6. 字符串
Java 字符串池发生了重大变化,当它在 Java7 中从 PermGen 转移到 HeapSpace 时所发生的。但是对于在版本6及以下运行的程序,我们在处理大字符串时应该更加注意。
如果我们读取一个巨大的字符串对象,并且调用 intern() 方法,它就会进入到位于 PermGen (永久内存)的字符串池中,而只要我们的应用程序运行,它就会一直呆在那里。
在 Java6 中本例子的 PermGen 在VisualVM 是这样的:
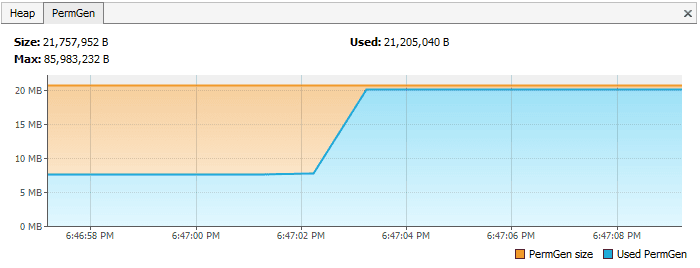
与此想法,在一个方法中,如果我们只是从文件中读取字符串,而不进行 intern ,PermGen 是这样的:
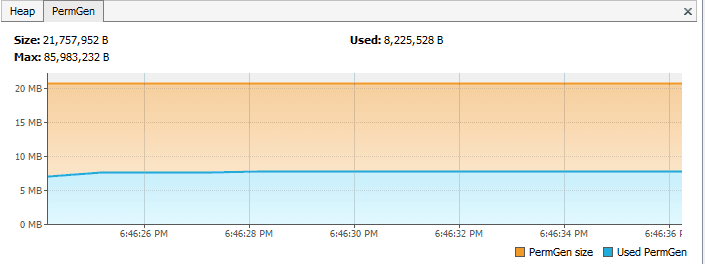
怎么预防这种情况发生呢?
- 预防的最简单的方法就是升级到最新的 Java 版本,因为字符串池是从 Java7 开始移动到 HeapSpace 的
- 如果需要处理大字符串,增加 PermGen 空间的大小,以避免任何潜在的 outofmemoryerror 异常
-XX:MaxPermSize=512m 复制代码
3.7. 使用 ThreadLocals
ThreadLocals 是一种结构,它使我们能够将状态隔离到特定的线程中,从而实现线程安全。
当使用这种结构, 每个线程都会持有其 ThreadLocal 变量副本的隐式引用,并且维护它们自身的副本,而不是在活动状态的线程当中跨线程共享资源 。
尽管它有其优点,但是 ThreadLocal 的使用是受争议的。因为如果使用不恰当,它会导致内存泄漏。Joshua Bloch 曾经评论过 ThreadLocals*:
草率地使用线程池加上草率地使用线程局部变量,可能会导致意外的对象保留情况,这点在很多地方都被引起注意了,但把责任推给 ThreadLocal* 是没有依据的。
ThreadLocals 导致的内存泄漏
一旦持有的线程不再活动, ThreadLocals 应当被回收。当问题就出在当 ThreadLocals 被使用在现在流行的应用服务器上。
现在的应用服务器是使用线程池去处理请求而并非创建新的线程来处理(例如 Apache Tomcat 的 Executor )此外,它们还使用单独的类加载器。
由于应用服务器二弟线程池使用线程重用的概念来工作,因此它们从来都不会被回收 — 相反,它们被重用来服务于另一个新的请求。
现在,如果任何类创建了一个 ThreadLocals 而并没有显式地删除掉它,那么即使在web应用程序停止后,对象的副本仍然保留在工作线程当中,从而使得对象没有被回收。
怎么预防这种情况发生呢?
- 当 ThreadLocals 不再使用时,清理它们是一个很好的实践 — threadlocals 提供 remove() 方法,这个方法将删除该变量中的当前线程。
- 千万不要使用 ThreadLocal.set(null) 来清除 — 它实际上并没有做清除工作,而是会查找与当前线程关联的 Map 映射,并将键-值对分别设置为当前线程和null
- 最好将 ThreadLocal 视为一个需要在 finally 块中关闭的资源,以确保它始终处于关闭状态,即使在异常情况下也需要如此:
try {
threadLocal.set(System.nanoTime());
//... further processing
}
finally {
threadLocal.remove();
}
复制代码
4. 处理内存泄漏的其他策略
虽然在处理内存泄漏时并没有一种万能的解决方法,但是还是有些可以将风险降到最低的做法。
4.1. 使用剖析工具
Java 分析工具是通过应用程序监视和诊断内存泄漏的工具。它分析应用程序内部发生的事情 — 例如内存是怎么分配的。
通过分析器,我们能够比较不同的方法和找到使用资源的最优方法。
在第三节中我们使用 VisualVM。除此之外还有 Mission Control,JProfiler,YourKit,Java VisualVM,Netbeans Profiler 等等。
4.2. Verbose Garbage Collection
通过使用 Verbose Garbage Collection,我们可以跟踪 GC 的详细轨迹,为了开启它,我们需要在 JVM 配置中添加如下内容:
-verbose:gc 复制代码
通过添加这个参数,我们可以看到 GC 内部的细节:
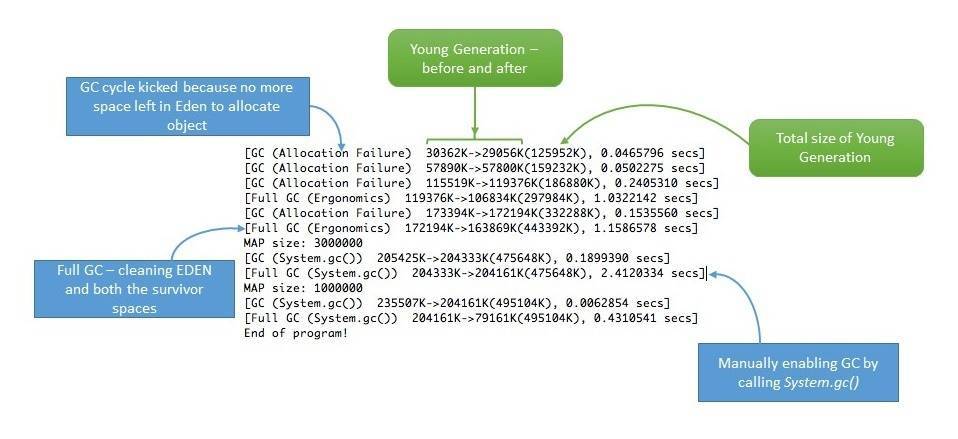
4.3. 使用引用对象避免内存泄漏
我们也可以使用 java.lang.ref 包中内置的引用对象来处理内存泄漏。使用 java.lang.ref 包,而并不会直接引用对象,使用对对象的特殊引用使得它们容易被回收。设计出的引用队列也让我们了解到垃圾回收的执行操作。
4.4. Eclipse 的内存泄漏警告
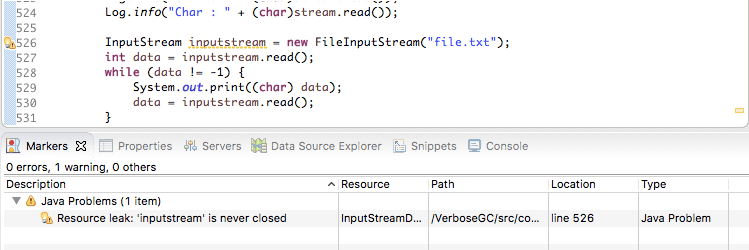
对于 JDK1.5 或以上的项目,当遇到明显的内存泄漏情况时,Eclipse 都会显示警告和错误。因此使用 Eclipse 开发时,我们可以通过查看 Problems 标签栏,来提防内存泄漏的警告了(如果有的话):
4.5. Benchmarking
我们通过 Benchmarking 来度量和分析 Java 代码的性能。通过这种方法,我们可以比较对同一个任务的不同种做法之间的性能。这可以帮助我们选择更好的方法去运行,也可以节约内存消耗。
4.6. 代码 review
最后,还是以我们最经典,老式的代码遍历方法来处理啦。
在某些情况下,即使是一个看起来微不足道的方法,也可以帮助我们消除一些常见的内存泄漏问题。
5. 总结
用外行的话来说,我们可以把内存泄漏当作一种疾病,它通过阻塞重要的内存资源来降低应用程序的性能。和其他所有疾病一样,如果没有痊愈,随着时间推移,它可能导致致命的程序崩溃。
内存泄漏难以解决,找到它们需要对 Java 本身有很高的掌握以及知识。 在处理内存泄漏时,没有适用于所有情况的解决方法,因为泄漏本身可以通过各种各样的事件发生。
然而,如果我们采用最佳的代码方式实践并且定期做代码的回顾和严格的代码分析,那么我们可以将应用程序中的内存泄漏风险降至最低。
像往常那样,用于生成本文章中 VisualVM 的响应的代码段在我们的 Github 上可以获取到。
6. 译者总结
这篇文章很详细的讲述了各种发生内存泄漏的情形以及一些简单的解决方法,其中详细的解决方法在作者的其他文章中有提及,本人因为翻译的原因并没有放到上面,有需要的读者可以自行到文章本体去阅读。
而且本人因为时(TOU)间(LAN)原因,并没有把图片中的描述翻译过来,望各位读者见谅。
最后祝大家新春快乐。
小喇叭
广州芦苇科技Java开发团队
芦苇科技-广州专业互联网软件服务公司
抓住每一处细节 ,创造每一个美好
关注我们的公众号,了解更多
想和我们一起奋斗吗?lagou搜索“ 芦苇科技 ”或者投放简历到 server@talkmoney.cn 加入我们吧

关注我们,你的评论和点赞对我们最大的支持
正文到此结束
- 本文标签: 数据库 调试 空间 软件 http executor HashMap 自动化 UI 时间 list src ORM bug rand 翻译 科技 配置 代码 实例 总结 bean 模型 HashSet 服务器 map GitHub DOM final 线程池 id 缓存 web https 安全 内存模型 遍历 锁 文章 垃圾回收 类加载器 apache git cat 管理 程序员 开发 ACE Collection JVM java ip 互联网 IDE 智能 解决方法 生命 IO equals tomcat 线程 数据 CEO 参数 删除 图片 ArrayList eclipse
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

