京东服务市场高并发下 SOA 服务化演进架构
来这里找志同道合的小伙伴!
京东服务市场是京东商家与第三方独立软件提供商(ISV)进行服务类的在线交易平台。作为京东生态圈重要的一环,伴随着整个京东的快速增长,也在快速的发展。随着服务市场访问、交易量指数级的增长,系统由原来的ALL IN ONE架构,快速的演进成为SOA架构。
木桶的容量由木桶最短的木板决定,高并发环境下,单个服务的性能决定了整个服务市场的性能。 “ 可用插件列表服务 ”是服务市场的核心服务之一,优化该服务性能的过程,带动整个服务市场服务架构的演进。
宏观的看,大到系统小到模块都由自身+外部依赖组成,性能优化主要从自身与外部依赖两个方面来进行。
优化自身
单线程到多线程的升级,尝试通过并行提高服务性能。
根据日志分析,整体调用中“服务详细信息”占用时间最多,并行虽然压缩了一些可并行服务的调用时间,但对于无法并行的“服务详细信息”环节,依然没有改善。要改善必须找到“商品服务”性能不高的原因。
可见自身优化能起一些作用,但外部依赖起着更决定性的作用。
解决外部依赖冲突
“商品服务”性能不高,这是为什么呢?先从 “商品服务” 的依赖开始分析。单独调用该服务,或压测该服务,性能都不差,但为何线上性能却不佳?
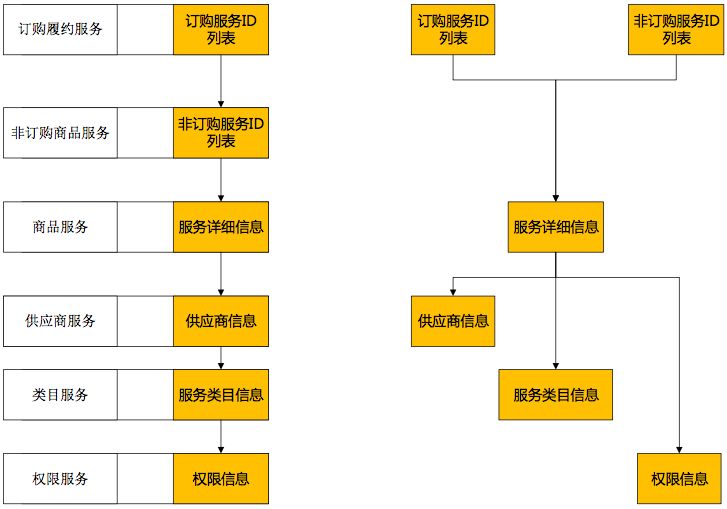
1、不同服务外部依赖资源冲突
对“商品服务”依赖的资源进行梳理,发现“商品服务”与“类目服务”使用相同数据库资源,非调用高峰期资源足够不相互影响,大并发环境下两个服务开始争夺资源。
将依赖资源分开,不同的服务使用不同的资源,通过调用不同的数据源解决冲突。
2、相同服务外部资源依赖冲突
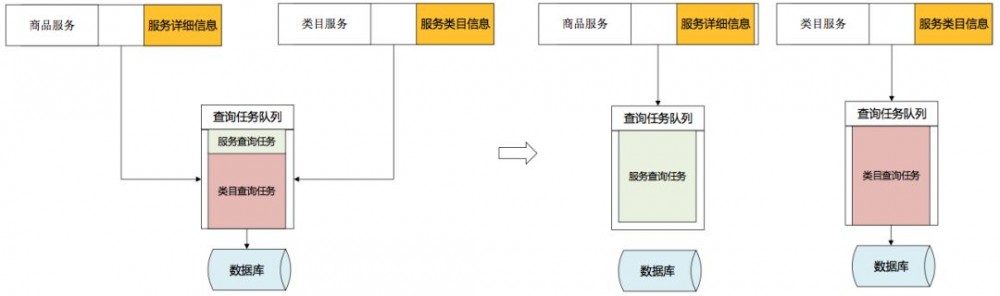
解决了两个服务对数据库资源的依赖冲突,性能有所提高,但性能总有很大的波动,排除其他服务外部资源的依赖冲突,看看“商品服务”自身对资源是如何使用的。
“商品服务”所有功能都单一的依赖数据库资源。服务上线后,自身多个功能开始争抢数据库资源。
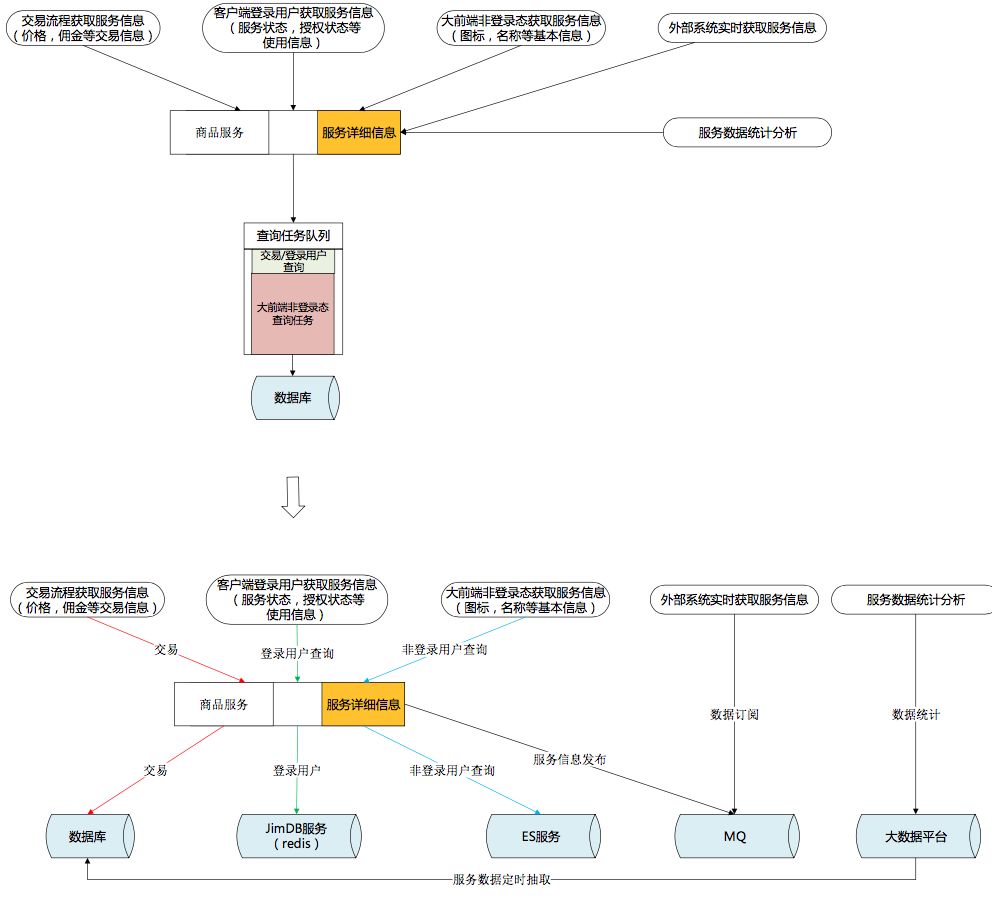
按使用场景进行外部依赖资源解耦:
1)为保证交易一致性,继续采用MySQL。MySQL的 INNODB引擎长于 OLTP 在线事务处理,为了保证数据强一致性的场景继续选择使用MySQL数据库。
2)客户端登录用户需要获得最新的数据反馈,且有PIN这个固定的维度。查询条件简单,能符合KEY-VALUE方式,Redis很适合这个场景。
3)大前端非登录状态下,访问的用户无须登录,有很大的访问量,更多的是获取服务的一些介绍。大数据量,可容忍一定程度的延迟,所以采用ES来进行查询支撑。
4)外部系统希望获得最新服务的变化,推的方式远强于轮训拉取的方式。通过MQ订阅服务的变化情况。
5)有复杂计算,但对实时性要求不高,服务统计分析系统通过大数据平台获取数据进行分析。
建立统一的内存缓存模型
计算机的世界里没有魔法,时间换空间、空间换时间是所有方案的基础。
参考常用的MySQL INNODB引擎,为加快查询速度会在内存中设置一块内存作为缓冲区,将查询结果从硬盘中加载到缓冲区,下次相同的查询直接使用缓冲区数据。同样的,如果要提高查询响应速度,必须把服务数据缓存到内存中。单机内存有限,无法容纳所有数据,且服务器重启时整个内存重建所耗费的时间也是无法接受的,于是选择用Redis与ES按照不同的使用场景来构造内存缓存。
1、选择主动缓存
常规的缓存方案:查询构建+定期失效。对有大量重复查询的环境效果很好,但在实际情况下,在某些场景却无法发挥预想中的作用。

场景特征:
1)每个用户只会打开一次客户端,获取一次插件信息,不会重复频繁的去拉取列表。
2)访问集中在8点到9点这个时间段。
使用被动缓存的后果:
1)8点前Redis缓存内是空的。
2)8点到9点,所有的列表信息都是第一次获取,查询全部穿透缓存直接打到数据库。
3)8点到9点之间获取插件列表后做了插件的续订或权限变更,由于缓存定时失效,导致更新无法反馈,用户不断刷新插件列表直到缓存失效获取到更新结果。人为制造流量洪峰,Redis抗住的也是这些无用的人为重复调用量。
4)9点以后缓存逐渐过期,不再被使用。
一个测试性能很好,实际却没有用的缓存。
基于以上,缓存层决定通过主动构建的方式建立缓存。在数据修改后,将变化数据主动的加载到Redis缓存中,缓存不再设置过期时间。
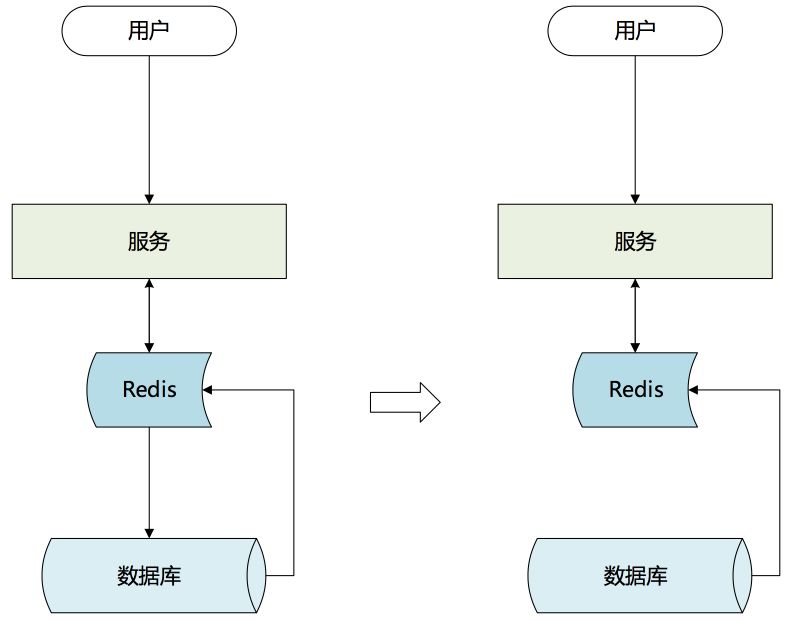
有的服务每次获取结果都要通过非常繁琐的计算,如果这些繁琐的计算集中在同一时间点,对于后端资源(数据库)是非常大的负担。
错峰使用资源,把构建缓存的过程分散在离散的调用中,集中使用时直接调用缓存获取最终结果。
上面提到过“类目服务”获取类目层级列表需要多次查询数据库,这对数据库是很大的负担。
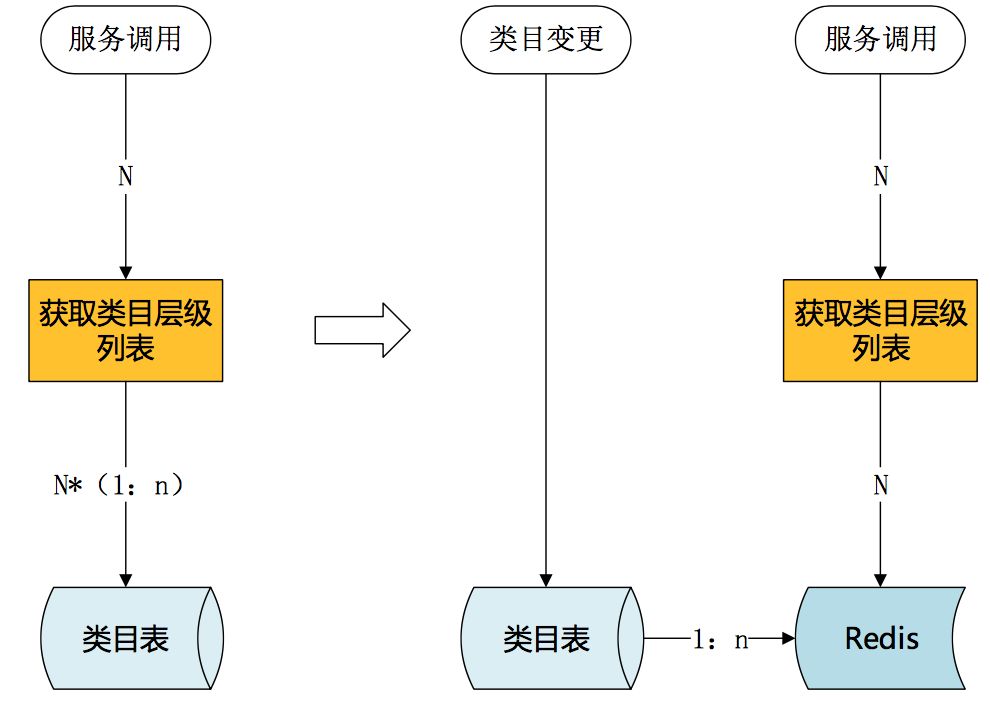
提前构建,在类目创建或类目变更时就重新构建类目层级列表,将结果存入缓存,高峰期使用时直接获取已构建完成的类目层级列表。
2、缓存碎片化
系统使用一段时间后,由于业务系统对服务数据需求的不一致,服务开发人员开始为每个外部系统提供一块主动缓存。这些缓存完全不具备通用性但又数量众多。每次服务模型修改,研发人员都要花大量时间去维护这些不通用的缓存。占用的缓存越来越多,但缓存的使用率并不高。
为去除冗余,降低维护工作量,最初按照数据表的维度将每一个表作为一个缓存。作为ES缓存可以采用这个方案,但是对于Redis缓存,这种缓存方式却带来了很大的麻烦。
数据库表设计为保证强一致性,建表的时候严格依照范式,数据中很少有冗余,表也切的很小,查询时通过联合查询来获取整体数据。但Redis没有联合查询的功能,因此不得不多次调用不同的缓存,多次调用大大降低了性能。对于查询而言,数据库会进行一些反范式操作。既然Reids缓存能够支撑查询,那么也可以做一定的冗余把这些关联数据作为一个整体对象缓存起来。
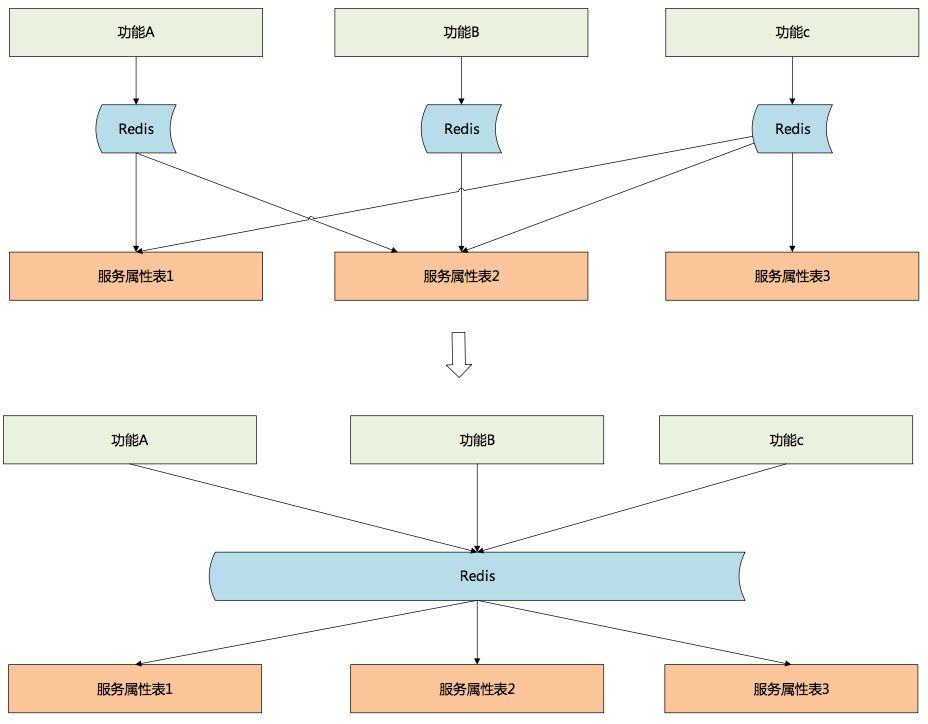
对于服务开发人员而言,主要职责是根据环境变化,不断的进化服务模型。服务开发人员维护一套最新、最完整的服务模型并将模型开放出来;服务调用者,特别是只获取服务数据的调用者完全可以通过对服务完整模型的自定义裁剪获取自己所需要的数据,各开发人员只关注自己需要关注的地方,大大提高了工作效率。
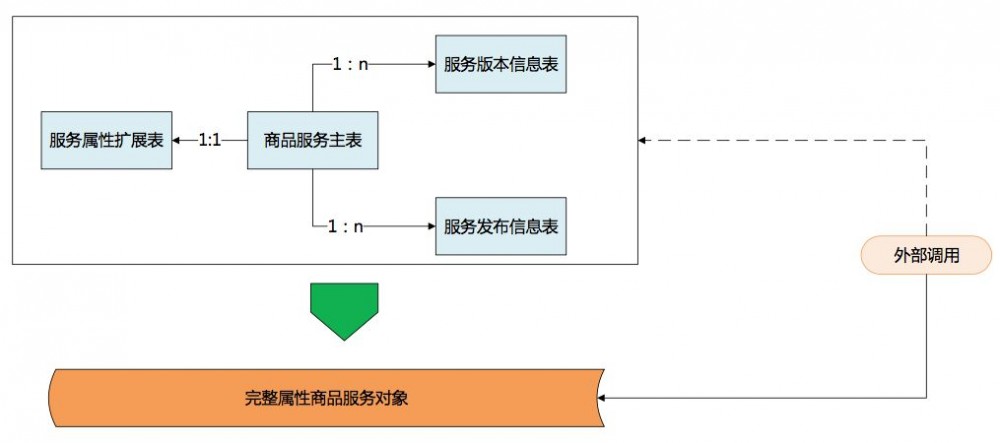
3、缓存构建方案
面临问题:
1)服务缓存构建与变更属于非核心流程,所以只能异步执行,通过MQ的方式与主流程解耦。
2)服务属性修改入口众多,通过MQ会出现操作重排序问题。
3)服务属性修改入口众多,每次修改或添加入口都必须跟着修改,业务侵入性强。
4)发送MQ的时机,事务中影响事务性能,当事务回滚时还需要发送补偿;事务后又无法保证一定能发送。
解决方案:
1)采用binlake的方式进行异步缓存构建,与主流程解耦。 Binlake是京东一款通过解析MySQL的binlog日志,并通过MQ队列进行解析受数据变更事件传递的数据异构产品。
2)数据库是功能修改后唯一进行数据持久化的地方,仅需监控数据库修改,就可获知所有的服务属性修改,不再需要跟着业务走,也不用担心操作重排序。
3)事务提交才能产生binlog日志,binlog的产生标志数据修改出于确定状态,不会出现回滚,解决MQ发送时机的问题。
4)Binlog事件通过MQ发送,发送不成功不修改日志偏移量,下次继续发送。接收队列为回执确认式队列,消费完成回执确认前会不断进行重试,解决发送丢失或接收后丢失问题。
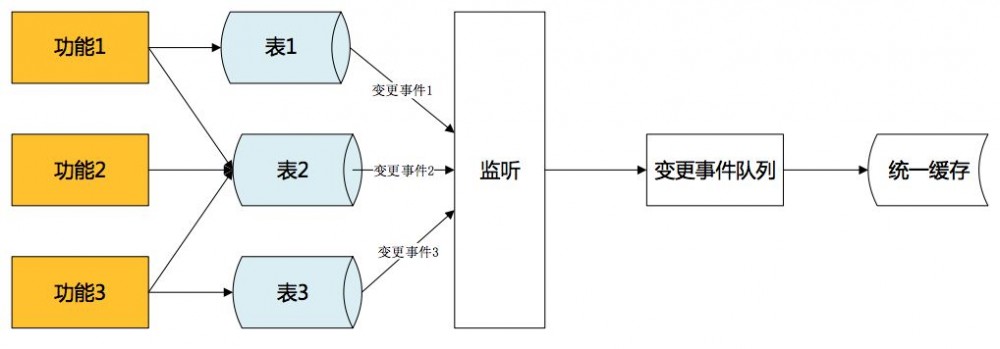
初期采取直接解析binlog报文,按照消息内容更新数据。为保证消费顺序性,必须只有一个队列进行消息传递,大大降低了效率,并埋下了单点的隐患。
解决方法是,MQ不作为数据变化的承载者,而是作为一个通知者。当缓存构造者接受到MQ的时候,从数据库获取最新的服务属性,更新到缓存中。通过拉式获取完整的服务属性数据,保证了数据的完整性、一致性。而主动拉取数据,不限制于消息本身,也不需要保证消息顺序性,完美解决效率与单点问题。在属性被多次修改时,更能在其他修改消息未接收到时,就已经拉取到最新数据更新了缓存数据,进一步提高了实时性。
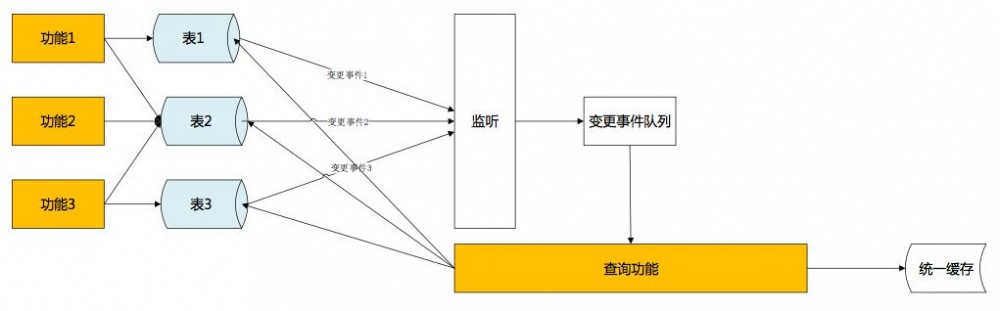
最后,单向事件触发有很小的概率还是会发生数据不一致。解决办法是,采用定时比对的方式,每个小时(可调整)通过时间戳比对当日数据与缓存数据差异,进行最终补偿。
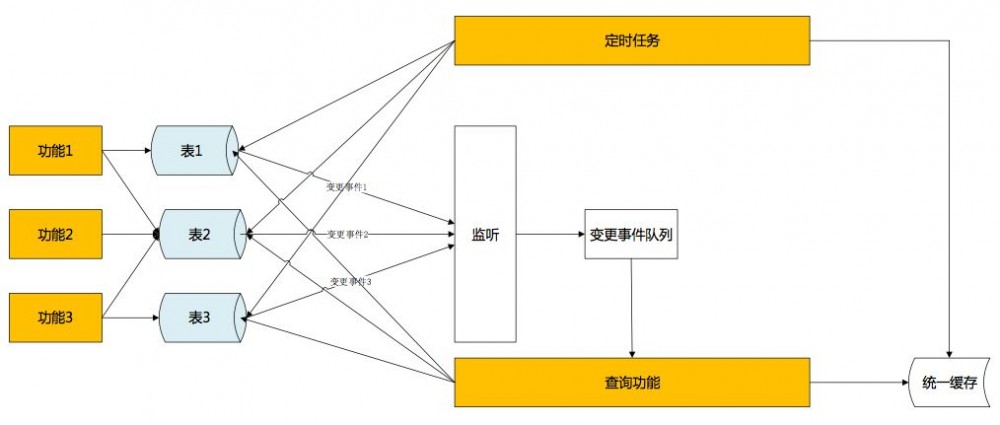
后记
解决了不同服务对相同资源的调用冲突,服务内不同的场景使用不同的资源支撑,创建了统一缓存层摆脱对数据库的依赖。使用不同的方法解决了当统一缓存建立以后,如何使查询摆脱了对数据库的强依赖,服务性能得到了非常大的提升。
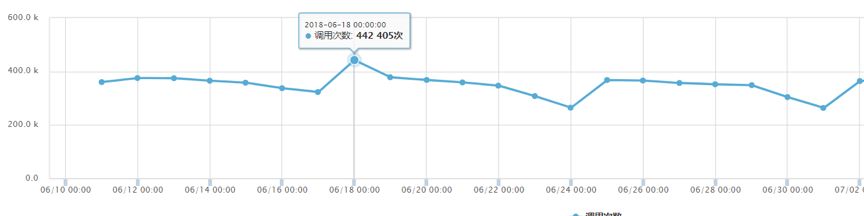
改造前支撑调用量:
改造后支撑调用量:
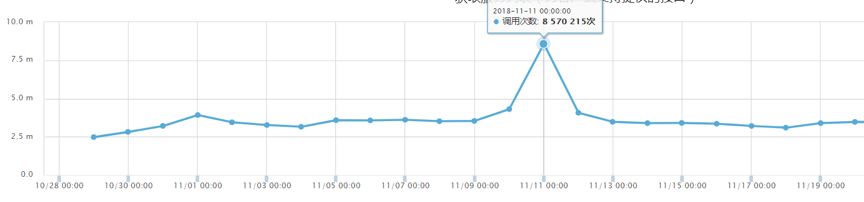
通过以上演进,“可用插件列表服务”并发性能有了很大的提升。 2018年11.11零点调用量10分钟内陡增6倍,平稳度过。
作者简介
研发老兵,热爱技术,喜欢挑战。熟悉各种开源框架,对大型分布式系统有丰富的架构、设计经验。
性能卓越、设计优雅是其一生的追求。
RECOMMEND
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

