WebMagic 爬虫框架浅析
很久之前因为爬虫需求就接触过 WebMagic,但是一直停留在简单使用阶段。近来公司项目也有爬虫需求,而且需要对爬虫框架做一些定制开发,便以此为契机深入学习 WebMagic 的设计思想及实现原理。
概述
WebMagic 是国内知名开发者黄亿华开源的一个 Java 爬虫框架。WebMagic 的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。WebMagic 的结构分为Downloader、PageProcessor、Scheduler、Pipeline 四大组件,并由 Spider 将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
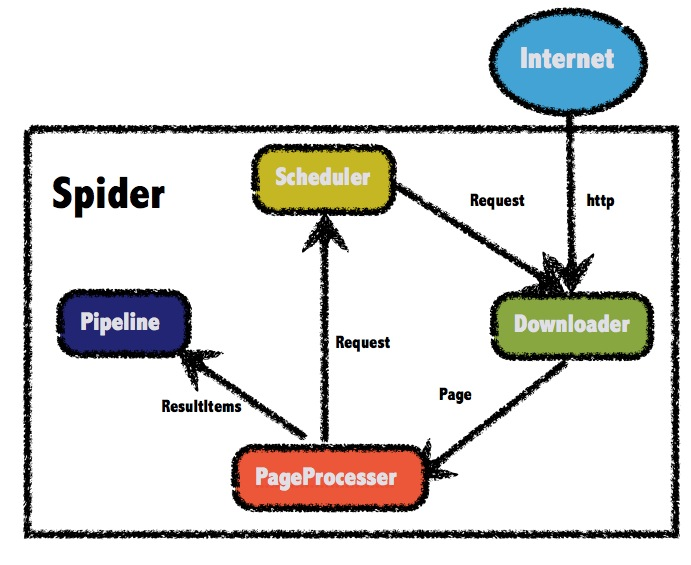
Scheduler
Scheduler 是 WebMagic中的 URL 调度器,负责从 Spider 处理收集 (push) 需要抓取的 URL (Page 的 targetRequests)、并 poll 出将要被处理的 URL 给 Spider,同时还负责对 URL 判断是否进行错误重试、及去重处理、以及总页面数、剩余页面数统计等。 Scheduler 实现类主要有 DuplicateRemovedScheduler、PriorityScheduler、QueueScheduler,拓展包还有 RedisScheduler、FileCacheQueueScheduler。虽然实现类不少,但是原理都差不多,WebMagic 默认实现是 QueueScheduler,便以此分析。
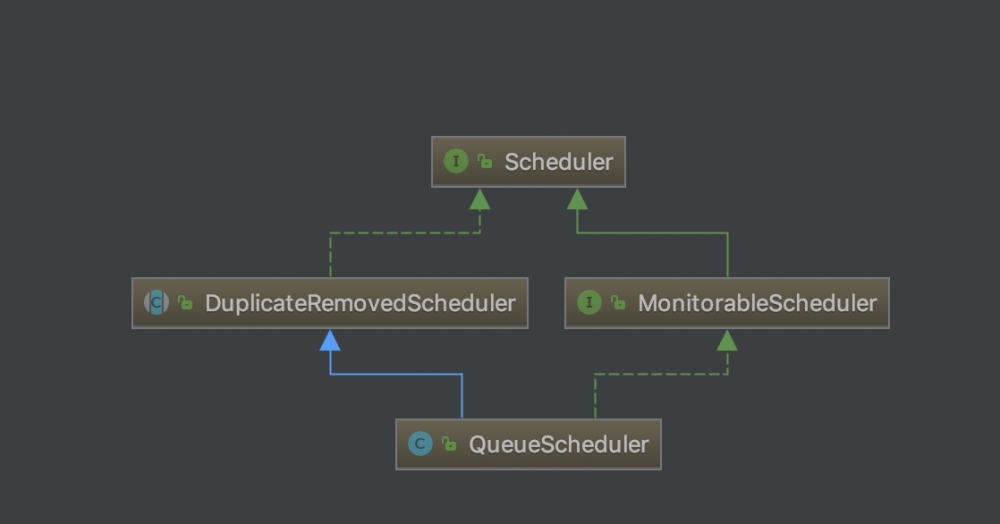
Scheduler 接口定义了 Scheduler 最基础的功能:添加一个请求,获取一个请求。
public interface Scheduler {
/**
* add a url to fetch
*
* @param request request
* @param task task
*/
public void push(Request request, Task task);
/**
* get an url to crawl
*
* @param task the task of spider
* @return the url to crawl
*/
public Request poll(Task task);
}
复制代码
MonitorableScheduler 接口定义了获取剩余请求数和总请求数的方法。
public interface MonitorableScheduler extends Scheduler {
public int getLeftRequestsCount(Task task);
public int getTotalRequestsCount(Task task);
}
复制代码
DuplicateRemovedScheduler 抽象类实现了通用的 push 模板方法,并在 push 方法内部判断错误重试、去重处理等。
public abstract class DuplicateRemovedScheduler implements Scheduler {
protected Logger logger = LoggerFactory.getLogger(getClass());
// 去重策略实现类,关键点在于 private Set<String> urls = Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>());通过 Set 和 ConcurrentHashMap 的特性实现去重及并发安全
private DuplicateRemover duplicatedRemover = new HashSetDuplicateRemover();
public DuplicateRemover getDuplicateRemover() {
return duplicatedRemover;
}
public DuplicateRemovedScheduler setDuplicateRemover(DuplicateRemover duplicatedRemover) {
this.duplicatedRemover = duplicatedRemover;
return this;
}
// 通用 push 模版方法
@Override
public void push(Request request, Task task) {
logger.trace("get a candidate url {}", request.getUrl());
if (shouldReserved(request) || noNeedToRemoveDuplicate(request) || !duplicatedRemover.isDuplicate(request, task)) {
logger.debug("push to queue {}", request.getUrl());
pushWhenNoDuplicate(request, task);
}
}
// 如果设置了回收重试则不需要去重处理
protected boolean shouldReserved(Request request) {
return request.getExtra(Request.CYCLE_TRIED_TIMES) != null;
}
// 如果是 POST 请求则不需要去重处理,因为 POST 请求不是幂等的,POST 请求没有加入到 Set 中去重,所以也不会计入请求数统计中
protected boolean noNeedToRemoveDuplicate(Request request) {
return HttpConstant.Method.POST.equalsIgnoreCase(request.getMethod());
}
protected void pushWhenNoDuplicate(Request request, Task task) {
}
}
复制代码
QueueScheduler 的实现很简单,维护一个 LinkedBlockingQueue 即可,获取剩余请求数即队列的 size,获取总请求数即 HashSetDuplicateRemover 维护的 Set 集合的 size。
@ThreadSafe
public class QueueScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler {
private BlockingQueue<Request> queue = new LinkedBlockingQueue();
public QueueScheduler() {
}
public void pushWhenNoDuplicate(Request request, Task task) {
this.queue.add(request);
}
public Request poll(Task task) {
return (Request)this.queue.poll();
}
public int getLeftRequestsCount(Task task) {
return this.queue.size();
}
public int getTotalRequestsCount(Task task) {
return this.getDuplicateRemover().getTotalRequestsCount(task);
}
}
复制代码
Downloader
Downloader 是负责请求 URL 获取返回值(HTML、Json、Jsonp 等)的一个组件,同时也会处理 POST 重定向、Https 验证、IP 代理、判断失败重试等
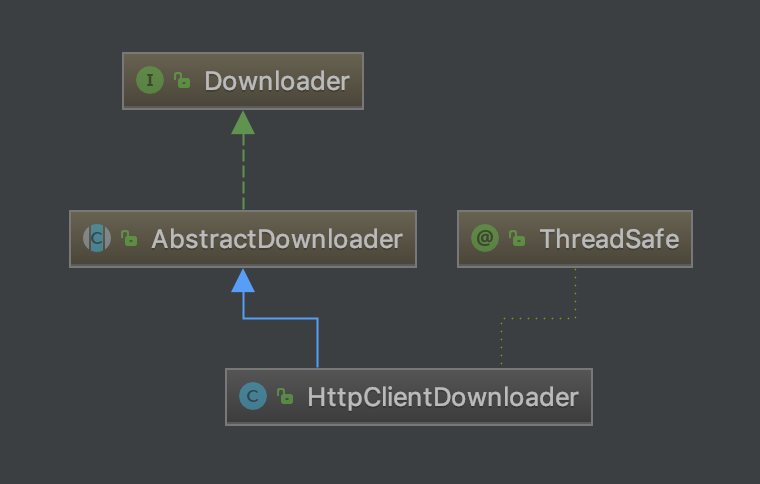
Downloader 接口定义了下载和设置线程数的方法。
public interface Downloader {
/**
* Downloads web pages and store in Page object.
*
* @param request request
* @param task task
* @return page
*/
public Page download(Request request, Task task);
/**
* Tell the downloader how many threads the spider used.
* @param threadNum number of threads
*/
public void setThread(int threadNum);
}
复制代码
AbstractDownloader 抽象类提供了更上层的 download 方法实现及定义了成功失败的回调方法。
public abstract class AbstractDownloader implements Downloader {
/**
* A simple method to download a url.
*
* @param url url
* @return html
*/
public Html download(String url) {
return download(url, null);
}
/**
* A simple method to download a url.
*
* @param url url
* @param charset charset
* @return html
*/
public Html download(String url, String charset) {
Page page = download(new Request(url), Site.me().setCharset(charset).toTask());
return (Html) page.getHtml();
}
protected void onSuccess(Request request) {
}
protected void onError(Request request) {
}
}
复制代码
HttpClientDownloader 类是 WebMagic Downloader 的默认实现,主要功能是根据配置生成 HttpClient 实例请求网络,将请求、结果封装成 Page 对象,并调用相应的回调方法。
通过 Site 获取域名,然后通过域名判断是否在 httpClients 这个 map 中已存在 HttpClient 实例,如果存在则重用,否则通过 httpClientGenerator 创建一个新的实例,然后加入到 httpClients这个 map 中并返回。注意为了确保线程安全性,这里用到了线程安全的双重判断机制。
private CloseableHttpClient getHttpClient(Site site) {
if (site == null) {
return httpClientGenerator.getClient(null);
}
String domain = site.getDomain();
CloseableHttpClient httpClient = httpClients.get(domain);
if (httpClient == null) {
synchronized (this) {
httpClient = httpClients.get(domain);
if (httpClient == null) {
httpClient = httpClientGenerator.getClient(site);
httpClients.put(domain, httpClient);
}
}
}
return httpClient;
}
复制代码
WebMagic threadNum 既是线程池的线程数,也是 HttpClient ConnectionManager 的连接数,这里设置的就是连接数。
@Override
public void setThread(int thread) {
httpClientGenerator.setPoolSize(thread);
}
复制代码
public HttpClientGenerator setPoolSize(int poolSize) {
connectionManager.setMaxTotal(poolSize);
return this;
}
复制代码
HttpClientDownloader 优先获取 Site 对象的 charset,如果为空会智能检测字符编码,首先判断 httpResponse.getEntity().getContentType().getValue() 是否含有比如 charset=utf-8, 否则用 Jsoup 解析内容,判断是提取 meta 标签,然后判断针对 HTML4 中 和 HTML5 中 分情况判断出字符编码.
private String getHtmlCharset(String contentType, byte[] contentBytes) throws IOException {
String charset = CharsetUtils.detectCharset(contentType, contentBytes);
if (charset == null) {
charset = Charset.defaultCharset().name();
logger.warn("Charset autodetect failed, use {} as charset. Please specify charset in Site.setCharset()", Charset.defaultCharset());
}
return charset;
}
复制代码
public static String detectCharset(String contentType, byte[] contentBytes) throws IOException {
String charset;
// charset
// 1、encoding in http header Content-Type
charset = UrlUtils.getCharset(contentType);
if (StringUtils.isNotBlank(contentType) && StringUtils.isNotBlank(charset)) {
logger.debug("Auto get charset: {}", charset);
return charset;
}
// use default charset to decode first time
Charset defaultCharset = Charset.defaultCharset();
String content = new String(contentBytes, defaultCharset);
// 2、charset in meta
if (StringUtils.isNotEmpty(content)) {
Document document = Jsoup.parse(content);
Elements links = document.select("meta");
for (Element link : links) {
// 2.1、html4.01 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
String metaContent = link.attr("content");
String metaCharset = link.attr("charset");
if (metaContent.indexOf("charset") != -1) {
metaContent = metaContent.substring(metaContent.indexOf("charset"), metaContent.length());
charset = metaContent.split("=")[1];
break;
}
// 2.2、html5 <meta charset="UTF-8" />
else if (StringUtils.isNotEmpty(metaCharset)) {
charset = metaCharset;
break;
}
}
}
logger.debug("Auto get charset: {}", charset);
// 3、todo use tools as cpdetector for content decode
return charset;
}
复制代码
download() 方法就是常规的 HttpClient 操作请求网络,handleResponse() 方法将请求、结果封装成 Page 对象,然后调用相应的回调方法,最后将 HttpClient 的连接和代理释放掉。
@Override
public Page download(Request request, Task task) {
if (task == null || task.getSite() == null) {
throw new NullPointerException("task or site can not be null");
}
CloseableHttpResponse httpResponse = null;
CloseableHttpClient httpClient = getHttpClient(task.getSite());
Proxy proxy = proxyProvider != null ? proxyProvider.getProxy(task) : null;
HttpClientRequestContext requestContext = httpUriRequestConverter.convert(request, task.getSite(), proxy);
Page page = Page.fail();
try {
httpResponse = httpClient.execute(requestContext.getHttpUriRequest(), requestContext.getHttpClientContext());
page = handleResponse(request, request.getCharset() != null ? request.getCharset() : task.getSite().getCharset(), httpResponse, task);
onSuccess(request);
logger.info("downloading page success {}", request.getUrl());
return page;
} catch (IOException e) {
logger.warn("download page {} error", request.getUrl(), e);
onError(request);
return page;
} finally {
if (httpResponse != null) {
//ensure the connection is released back to pool
EntityUtils.consumeQuietly(httpResponse.getEntity());
}
if (proxyProvider != null && proxy != null) {
proxyProvider.returnProxy(proxy, page, task);
}
}
}
复制代码
PageProcessor
PageProcessor 接口定义了 process() 页面分析的方法还有 getSite() 提供 HttpClient 请求相关配置的方法。
public interface PageProcessor {
/**
* process the page, extract urls to fetch, extract the data and store
*
* @param page page
*/
public void process(Page page);
/**
* get the site settings
*
* @return site
* @see Site
*/
public Site getSite();
}
复制代码
这里的页面分析主要指HTML页面的分析,页面分析可以说是垂直爬虫最复杂的一部分。Selector 是 WebMagic 为了简化页面抽取开发的独立模块,整合了 CSS Selector、XPath 和正则表达式,并可以进行链式的抽取,很容易就实现强大的功能。
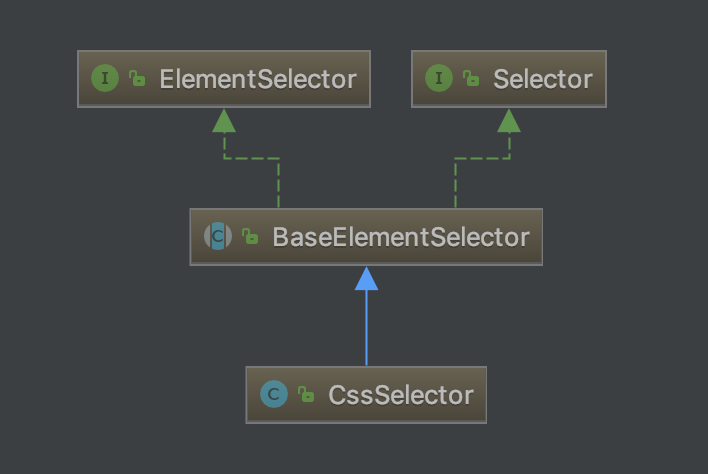
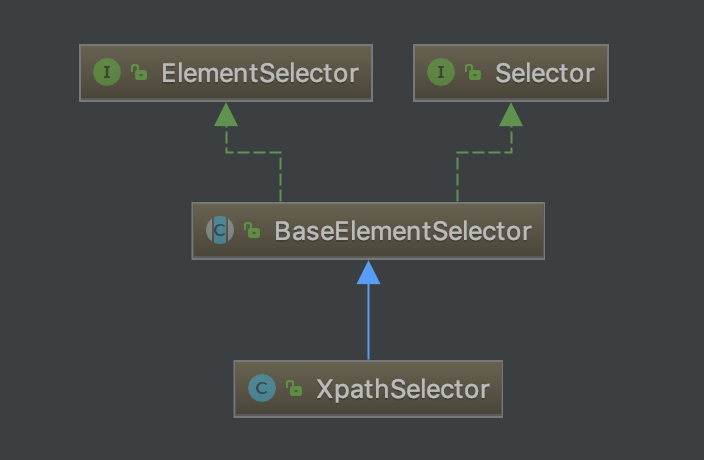
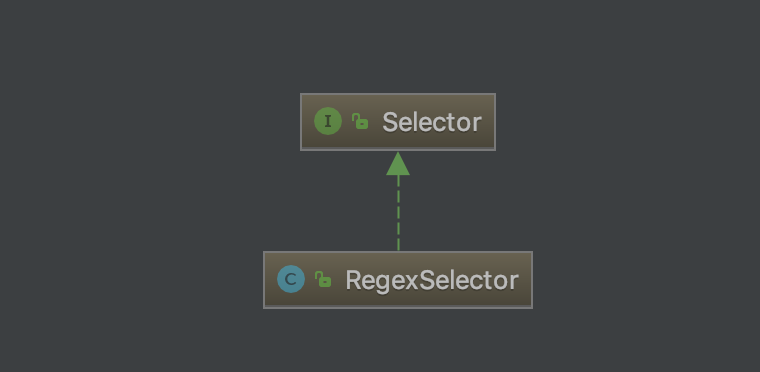
接口: Selector:定义了根据字符串选择单个元素和选择多个元素的方法。 ElementSelector:定义了根据 Jsoup Element选择单个、多个元素的方法。主要用于 CSS、Xpath 选择器。 抽象类: BaseElementSelector 实现类前面说的两个接口,主要用于 CSS、Xpath 选择器继承。模板化接口方法,并定义了一些选择元素的方法由子类实现。 实现类: CssSelector:CSS 选择器的实现类,继承 BaseElementSelector。基本实现都是基于Jsoup 的 CSS 选择接口。 XpathSelector:Xpath 选择器的实现类,继承 BaseElementSelector。基本实现都是采用作者自己基于 Jsoup 实现的 Xsoup 的相关接口。 RegexSelector:正则表达式选择器的实现类,仅实现了Selector接口。 源码: 源码就不作分析了,基本就是基本的 Java 正则 API 和 Jsoup API 的封装调用。
Pipeline
Pipeline其实也是容易被忽略的一部分。大家都知道持久化的重要性,但是很多框架都选择直接在页面抽取的时候将持久化一起完成,例如crawer4j。但是Pipeline真正的好处是,将页面的在线分析和离线处理拆分开来,可以在一些线程里进行下载,另一些线程里进行处理和持久化。
Pipeline 接口很简单,只有一个 process() 方法,参数是 PageProcessor 的解析结果及任务 task 对象,实现类主要有 ConsolePipeline、FilePipeline、ResultItemsCollectorPipeline 等,把解析结果拼接起来输出到控制台、文件或者保存到内存集合对象中。源码很简单也就不展开分析了。
public interface Pipeline {
/**
* Process extracted results.
*
* @param resultItems resultItems
* @param task task
*/
public void process(ResultItems resultItems, Task task);
}
复制代码
@ThreadSafe
public class FilePipeline extends FilePersistentBase implements Pipeline {
private Logger logger = LoggerFactory.getLogger(getClass());
/**
* create a FilePipeline with default path"/data/webmagic/"
*/
public FilePipeline() {
setPath("/data/webmagic/");
}
public FilePipeline(String path) {
setPath(path);
}
@Override
public void process(ResultItems resultItems, Task task) {
String path = this.path + PATH_SEPERATOR + task.getUUID() + PATH_SEPERATOR;
try {
PrintWriter printWriter = new PrintWriter(new OutputStreamWriter(new FileOutputStream(getFile(path + DigestUtils.md5Hex(resultItems.getRequest().getUrl()) + ".html")),"UTF-8"));
printWriter.println("url:/t" + resultItems.getRequest().getUrl());
for (Map.Entry<String, Object> entry : resultItems.getAll().entrySet()) {
if (entry.getValue() instanceof Iterable) {
Iterable value = (Iterable) entry.getValue();
printWriter.println(entry.getKey() + ":");
for (Object o : value) {
printWriter.println(o);
}
} else {
printWriter.println(entry.getKey() + ":/t" + entry.getValue());
}
}
printWriter.close();
} catch (IOException e) {
logger.warn("write file error", e);
}
}
}
复制代码
正文到此结束
- 本文标签: cat CSS CTO Select 参数 entity 线程池 bug stream 源码 线程 IDE CEO DOM 组织 src 调度器 id 幂等 定制 tar redis 域名 Document value client 下载 mmap Proxy web 开发者 需求 parse key Connection ACE Collection synchronized java js UI 代码 解析 Collections provider 生命 IO equals 正则表达式 https 配置 HTML5 jsoup json 开源 http cache ConcurrentHashMap tk ip map API HTML 实例 final ask constant HashMap HashSet 安全 管理 智能 URLs 开发 统计 queue 架构设计 并发 db
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

