一次线上JVM内存异常排查
2月11日网关在短时间内出现20+的访问出错,查看kibina如下:
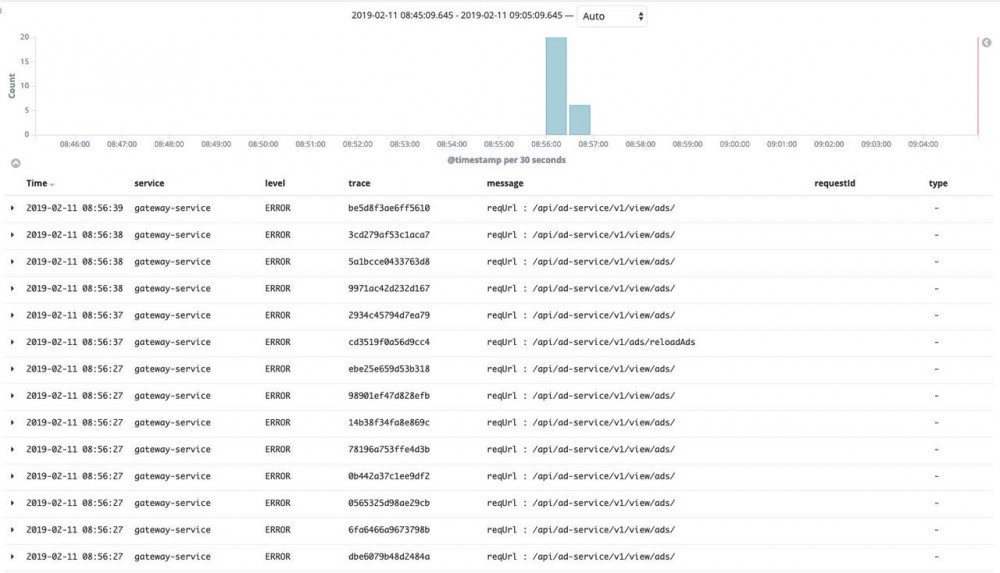
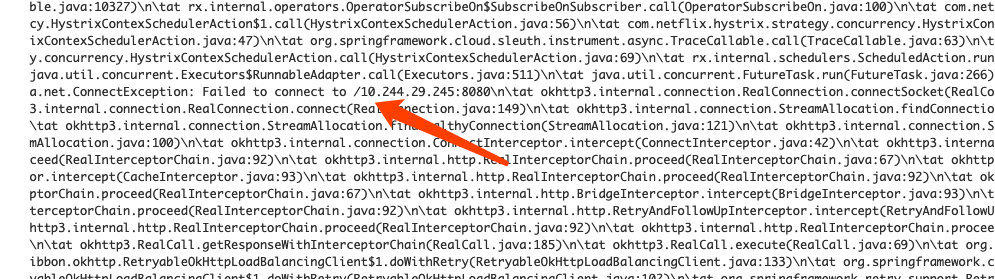
根据trace得到具体的堆栈异常,发现都是负载均衡同一个pod均显示连接异常:
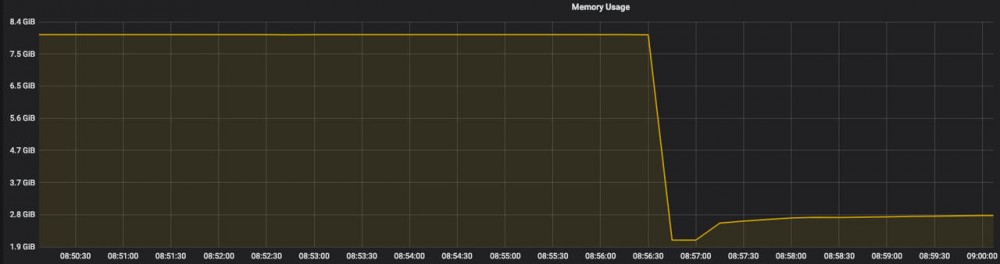
去grafana查看该pod运行情况,可以发现内存突然下降的情况,同时该pod已经达到内存上限(8G),当资源申请不到的情况下,该pod可能存在重启的情况:
查看ad服务的日志验证了当时确实发生了重启:
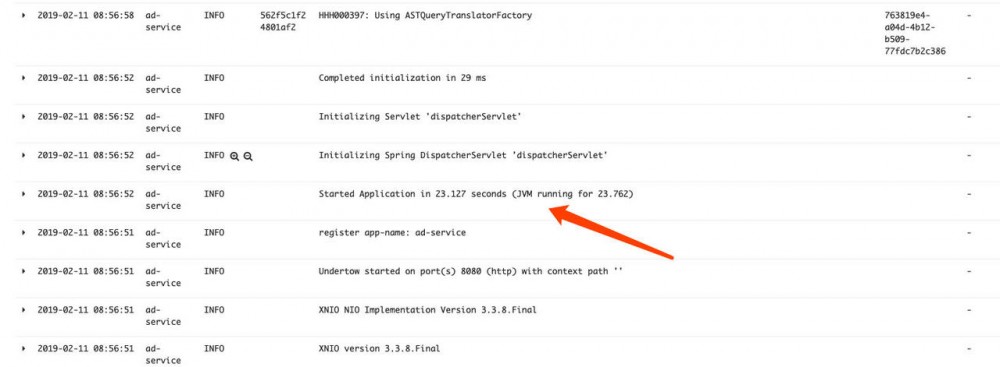
此时可以基本定位到因为内存问题使得服务重启,从而网关无法负载均衡到该服务实例导致网关报错,接下来需要明确是什么原因让该pod的内存占用如此之高。
二、内存问题定位
- 根据grafana的图表,可以看出堆内存比较正常,而非堆内存出现了异常(使用率超过100%):

非堆就是JVM留给自己用的,方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法 的代码都在非堆内存中。
-
用JProfiler打开该文件(也可以用jVisualVM),找到Biggest Objects,然后发现在存活对象中存在大量的AdDto这个类的实例,大量这些对象整整占用了1G多:
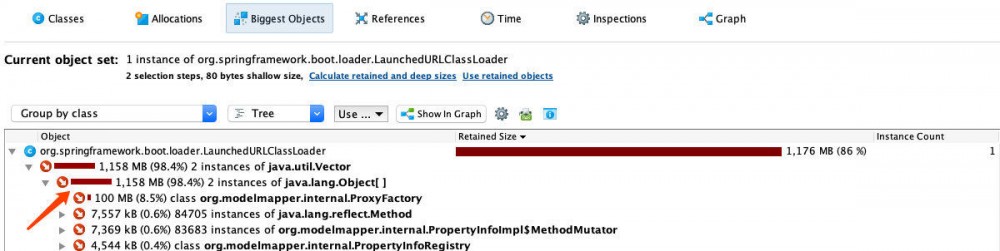
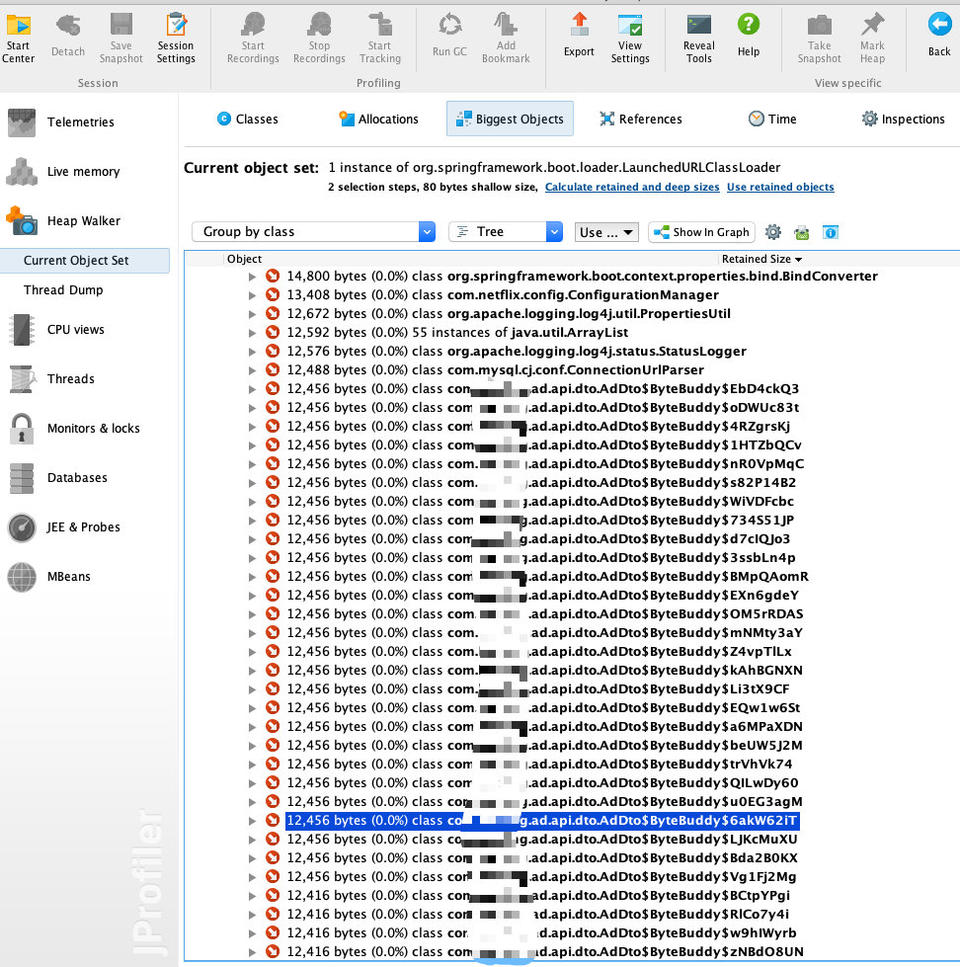
三、代码检查
回到代码中,检查AdDto的生成方式,发现用了如下的操作:
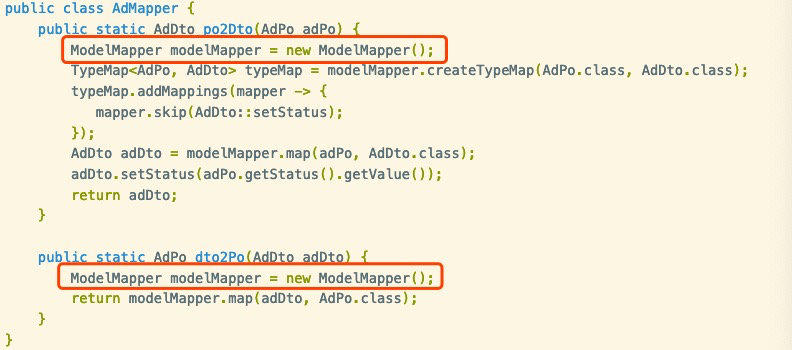
modelMapper每一次调用addMapping都将创建一份该类的结构(通过字节码然后由类加载器加载),查阅官网相关文档。如果转换类型确定,应该将ModelMapper设置成单例( modelmapper.org/user-manual…
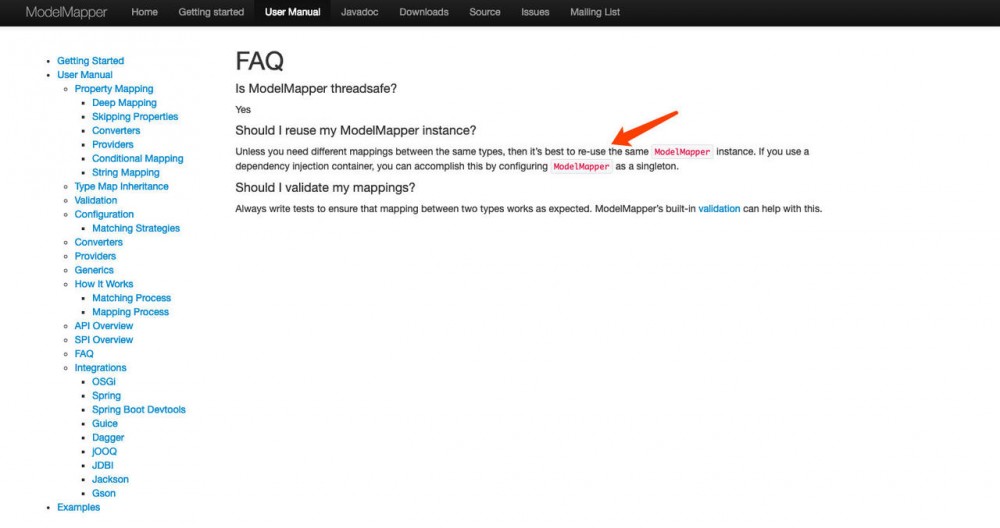
四、线下重现
在普通接口中用这段代码验证猜想,可以很明显看到非堆内存一路猛涨,并且加载类的数量也在一路上升,基本证实了问题:
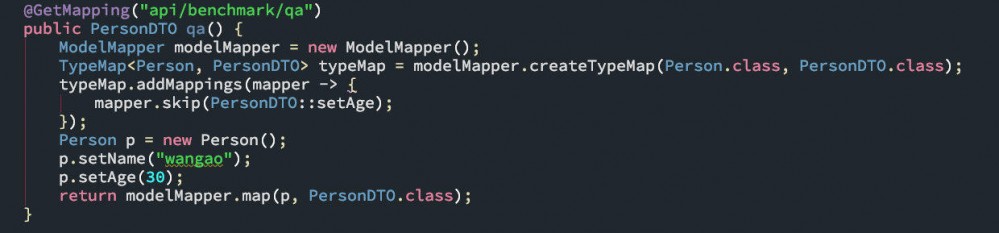
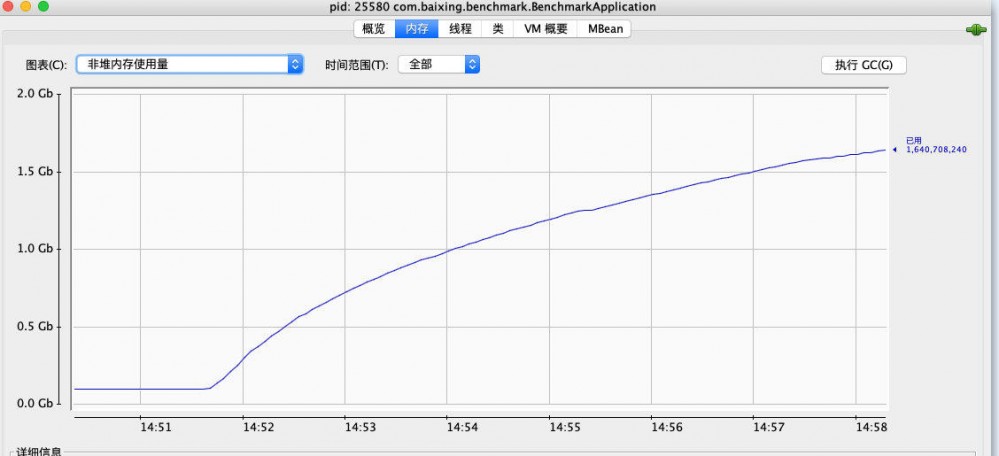
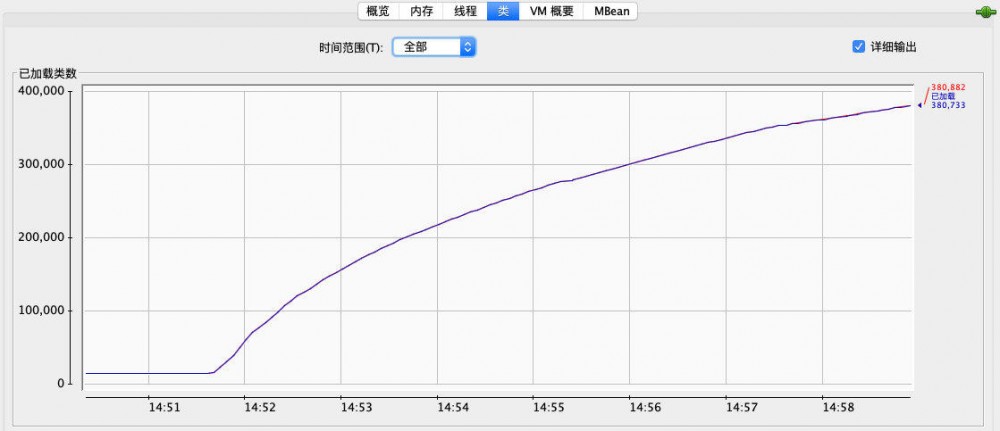
五、修复并验证
将代码改成如下形式并重新压测:
private static ModelMapper modelMapper;
static {
modelMapper = new ModelMapper();
TypeMap<Person, PersonDTO> typeMap = modelMapper.createTypeMap(Person.class, PersonDTO.class);
typeMap.addMappings(mapper -> {
mapper.skip(PersonDTO::setAge);
});
}
@GetMapping("api/benchmark/qa")
public PersonDTO qa() {
Person p = new Person();
p.setName("wangao");
p.setAge(30);
return modelMapper.map(p, PersonDTO.class);
}
复制代码
发现非堆内存稳定,类加载数量稳定:

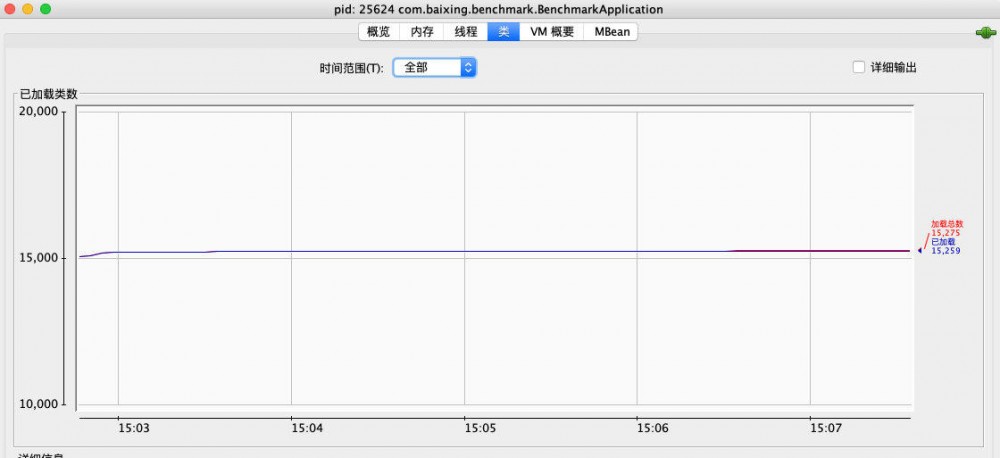
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

