一次ThreadLocal源码解析之旅
本篇文章旨在将ThreadLocal的原理说清楚,讲明白。全文主要完成了以下四个部分的工作:
- 摸清了ThreadLocal是如何做到在不同线程set()、get()的值不被其它线程访问的;
- 介绍了弱引用在ThreadLocalMap中的应用;
- 探寻了ThreadLocalMap如何实现hash map功能;
- 列举了一个使用ThreadLocal而出现的内存泄漏问题并加以分析;
首先,让我们看看ThreadLocal能产生什么样的效果:
public class ThreadLocalDemo {
public static void main(String[] args) {
final ThreadLocal<Integer> local = new ThreadLocal<>();
local.set(100);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " local: " + local.get());
}
});
t.start();
System.out.println("Main local: " + local.get());
}
}
复制代码
打印结果如下:
Thread-0 local: null Main local: 100 复制代码
local在主线程set的值,可以在主线程调用get方法得到,但在线程t内调用get方法,结果结果为null。
本文接下来以local调用的set方法为入口,探究产生这一结果的原因。
set()基础
在ThreadLocal源码中set()是这样实现的:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
复制代码
首先获得当前执行local.set()语句所在的线程对象,也就是t,然后通过local的getMap()获得t内部持有的ThreadLocalMap对象,进入Thread类的源码查看,其中就包含名为threadLocals的字段:
ThreadLocal.ThreadLocalMap threadLocals = null; 复制代码
而查看getMap()的源码,返回的就是threadLocals:
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
复制代码
map != null
如果map != null,则执行map.set(this, value),这里的this就是local。
ThreadLocalMap的具体实现后面再展开,在这里姑且先简单的理解为按键值对存储数据的数据结构,那么我们很容易发现,local还是那个local,并没有在每个线程产生local副本,只不过调用set方法的时候,将它与传入的值以键值对的形式,存储于每个线程内部持有的ThreadLocalMap对象里。
map == null
如果map == null,则执行createMap(t, value),源码如下:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
复制代码
创建ThreadLocalMap对象赋给threadLocals。
至此,ThreadLocal的基本原理就已经很清晰了: 各线程对共享的ThreadLocal实例进行操作,实际上是以该实例为键对内部持有的ThreadLocalMap对象进行操作 。
除了set(),ThreadLocal还提供了get()、remove()等操作,实现比较简单,就不敷述了。
ThreadLocalMap结构
要想真正理解ThreadLocal,还需要知道ThreadLocalMap究竟是什么。
注释中是这样介绍的:ThreadLocalMap is a customized hash map suitable only for maintaining thread local values.
ThreadLocalMap属于自定义的map,是一个带有hash功能的静态内部类,和java.util包下提供的Map类并没有关系。内部有一个静态的Entry类,下面具体分析Entry。
Entry实现原理
首先,这个类代码如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
复制代码
这里引用代码中给出的注释:The entries in this hash map extend WeakReference, using its main ref field as the key (which is always a ThreadLocal object). Note that null keys (i.e. entry.get() == null) mean that the key is no longer referenced。
第一句话实际上告诉了我们,entry继承自WeakReference,用main方法引用的字段作为entry中的key。
第二句的意思是,当entry.get() == null的时候,意味着键将不再被引用。
后续将解析这两句注释。
弱引用基础知识
在开始这一小结之前,需要先掌握两点:
- 什么是弱引用。《深入理解Java虚拟机》中这样写道:“被弱引用关联的对象只能生存到下一次垃圾收集发生之前,当垃圾收集器工作时,无论当前内存是否足够,都会回收掉,只被弱引用关联的对象。”
- 什么是参数的引用传递,这属于Java SE基础知识就不赘述了。
接下来,先阅读源代码,当构造器传入参数后,代表键的k会传入super()中,也就是它会首先执行父类的构造器:
public WeakReference(T referent) {
super(referent);
}
复制代码
WeakReference的构造器继续先调用父类的构造器:
Reference(T referent) {
this(referent, null);
}
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
复制代码
除此之外,我们在Reference类里面看不到任何native方法,但能看到一些实例方法,比如get(),后续我们还将谈到这个方法。
这个时候会疑惑弱引用的功能是怎么实现的,在注释中,有这样的字眼:“special treatment by the garbage collector.” 可见WeakReference的功能实现交给了垃圾回收器处理,那么这里就不展开了,感兴趣的可以参考文末的链接。在这里我们只需要了解WeakReference的使用方法。
弱引用和强引用的使用方法并不相同,下面是一个弱引用的示例:
public class WeakReferenceDemo {
public static void main(String[] args) {
WeakReference<Fruit> fruitWeakReference = new WeakReference<>(new Fruit());
// Fruit f = fruitWeakReference.get();
if (fruitWeakReference.get() != null) {
System.out.println("Before GC, this is the result");
}
System.gc();
if (fruitWeakReference.get() != null) {
System.out.println("After GC, fruitWeakReference.get() is not null");
} else {
System.out.println("After GC, fruitWeakReference.get() is null");
}
}
}
class Fruit {
}
复制代码
输出结果如下:
Before GC, this is the result After GC, fruitWeakReference.get() is null 复制代码
通过fruitWeakReference.get(),可以得到弱引用指向的对象,当执行System.gc()后,该对象被回收。
用一张图表示强弱引用彼此间的关系:
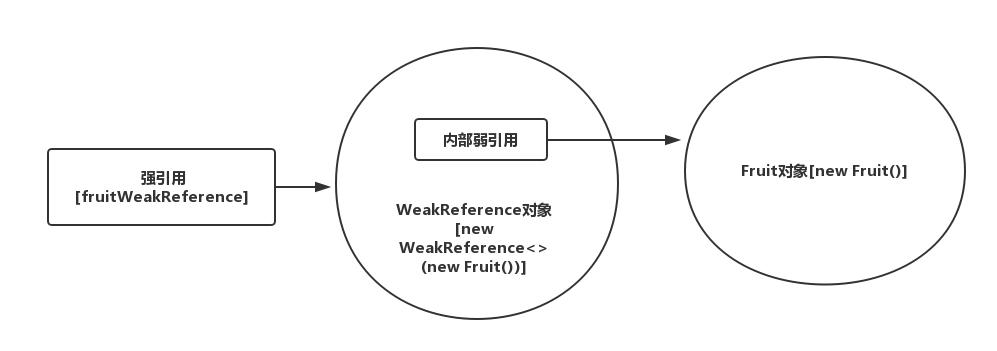
要明确的是,类似“Object obj = new Object()”这般产生的引用属于强引用,所以fruitWeakReference是强引用,此时它指向的是一个WeakReference对象,在new这个对象时,我们还传入了一个new出来的Fruit对象,整行代码的目的,就是要创造一个弱引用,指向这个Fruit对象。而这个弱引用,就在fruitWeakReference指向的对象里。
用个不严谨的比喻,弱引用就像一只薛定谔的猫,我们想知道它的状态,却不能通过普通的Java代码调用出它本身来观测它,如果将前文列出的WeakReferenceDemo内的双斜杠注释去掉,用一个变量f指向fruitWeakReference.get(),不过就是将一个强引用指向了原本由弱引用指向的对象而已,此时再运行程序,得到如下结果:
Before GC, this is the result After GC, fruitWeakReference.get() is not null Process finished with exit code 0 复制代码
由于对象被强引用,所以不会被垃圾回收。
弱引用Entry的键
有了前面的基础,很容易就能理解Entry的构造原理。为了方便说明,不妨假设我们能创建一个Entry对象,代码如下:
Entry entry = new Entry(local, 100); 复制代码
此时强弱引用彼此间的关系图如下:
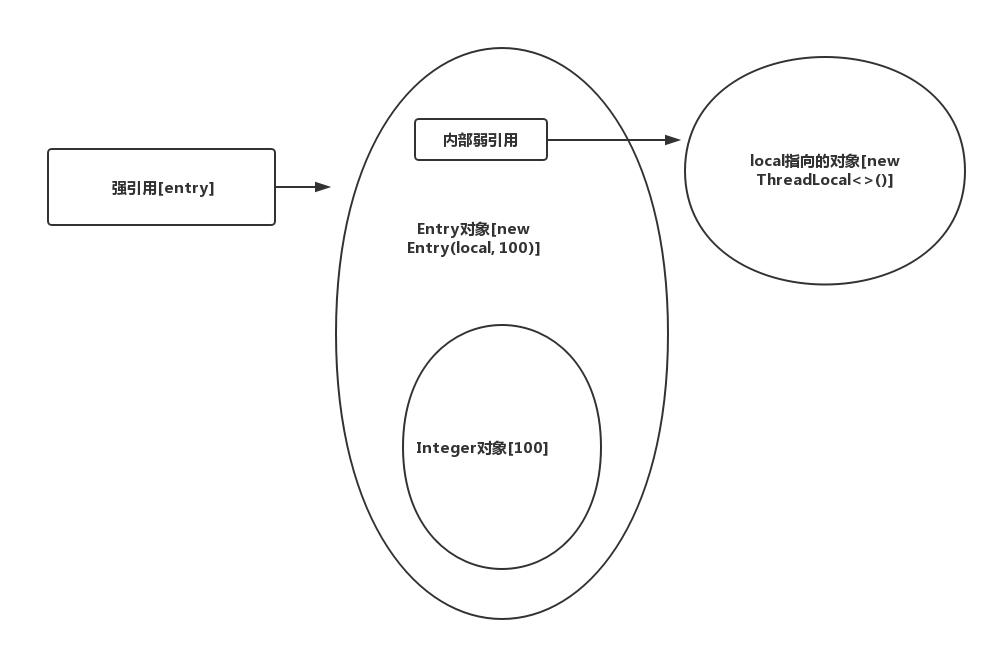
到这里,就能理解前面那两句注释了,entry继承自WeakReference,内部维护一个弱引用,指向main方法中local指向的对象;entry.get()返回的是弱引用指向的对象,如果entry.get() == null,自然表示的就是键将不再被引用了。
所以,和普通Map的Entry类不同,ThreadLocalMap的Entry实例被创建是时,键是弱引用,至此ThreadLocal内部ThreadLocalMap的基本结构也就清楚了。
set()进阶
再次贴出ThreadLocal中set()的源码:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
复制代码
注意第5行的语句,local调用set()时,一旦当前线程对象持有的ThreadLocalMap类型变量threadLocals不为null,则会执行map.set(this, value)这一行语句,上一节分析了ThreadLocalMap的结构,这一节将聚焦ThreadLocalMap的操作方法set()。
下面给出set()的源码:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 计算出hash表的位置i
int i = key.threadLocalHashCode & (len-1);
// 处理set方法关键逻辑
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 在hash表中保存新生成的Entry对象
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
复制代码
代码中i是hash表(亦称hash桶)的索引,也就是存放新设置的entry的位置,当然在存放之前还要进行一番比较操作。threadLocalHashCode是如下方式得到的:
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
private final int threadLocalHashCode = nextHashCode();
复制代码
采用0x61c88647是为了实现更好的散列,每当有新的ThreadLocal对象调用threadLocalHashCode的时候,后者自增一个0x61c88647大小的值。至于为什么0x61c88647可以实现更好的散列,这涉及到Fibonacci Hashing算法(这个数的二进制形式取反加1就是一个Fibonacci Hashing常数),具体细节可跳转到文末参考链接。
当然,在计算i之前还要进行一个位运算,非常简单,比如在没扩展之前len是16(2的4次方),那么len - 1的二进制形式就是1111,按位与也就是取后四位。
为了防止碰撞冲突,这里采用的是线性探测法,并没有采用拉链法。探测的索引规则如下:
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
复制代码
for循环的执行逻辑是这样的:
- 首先获取hash表索引位置为i的Entry元素tab[i];
- 判断tab[i]为是否为null,如果tab[i]为null,说明这个位置之前还没有存在过Entry实例,跳出循环,在hash表中该位置保存新生成的Entry对象;
- 如果tab[i]不为null,要么存在指向相同对象的键,如果是这种情况,则修改value为需要设定的值;要么弱引用指向为null,如果是这种情况,执行replaceStaleEntry方法;
- 用nextIndex方法修改i值,跳到第二步继续判断;
在跳出循环并在hash表相应位置保存新生成的Entry对象后,size也会加1,在满足!cleanSomeSlots(i, sz) && sz >= threshold的条件下,还要重新进行rehash()处理。
replaceStaleEntry以及cleanSomeSlots的主要作用都是用来删除弱引用为null的entry,后者查找的时间是log2(n),限于篇幅就不展开了,而threshold和HashMap中定义的预置作用相似,主要是扩容用的,这里为len * 2 / 3。
内存清理
还是沿用最初的例子,如果将local置为null,那么new出来的ThreadLocal对象就只被线程中的ThreadLocalMap实例弱引用,此时只要调用System.gc(),对象将在下一次垃圾收集时被回收。如果要主动断掉弱引用呢?Java提供了如下方法:
clear() 复制代码
它是Reference抽象类提供的方法。
接下来用一个例子讨论ThreadLocal可能出现的内存泄漏问题。
内存泄漏实例
实例源码如下:
public class ThreadLocalTest throws InterruptedException{
public static void main(String[] args) {
MyThreadLocal<Create50MB> local = new MyThreadLocal<>();
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new LinkedBlockingQueue<Runnable>());
for (int i = 0; i < 5; i++) {
final int[] a = new int[1];
final ThreadLocal[] finallocal = new MyThreadLocal[1];
finallocal[0] = local;
a[0] = i;
poolExecutor.execute(new Runnable() {
@Override
public void run() {
finallocal[0].set(new Create50MB());
System.out.println("add i = " + a[0]);
}
});
}
Thread.sleep(50000);
local = null;
}
static class Create50MB {
private byte[] bytes = new byte[1024 * 1024 * 50];
}
static class MyThreadLocal<T> extends ThreadLocal {
private byte[] bytes = new byte[1024 * 1024 * 500];
}
}
复制代码
先说一说该小程序的设计思路:
该程序旨在构造出一种内存泄漏的情况:当线程池执行完当前任务处于等待状态的时候,将local置null,回收main方法一开始new出来的MyThreadLocal对象,线程池内单个线程的ThreadLocalMap实例虽然弱引用于这个MyThreadLocal对象,但内部持有的value却仍然被强引用着不能回收。
在该程序中,我们自定义了一个MyThreadLocal,目的是使new出来的MyThreadLocal对象的大小能达到500MB;Create50MB是创建出来的容量包,每个线程最后持有的value就是一个50MB大小的Create50MB对象;线程池也是自定义传参,做到更好的掌控,一次能同时工作5个线程;for循环中用到了两个临时变量,是为了规避匿名内部类引用外部变量必须要声明为final的语言限制。
启动程序,运行状态见下图:
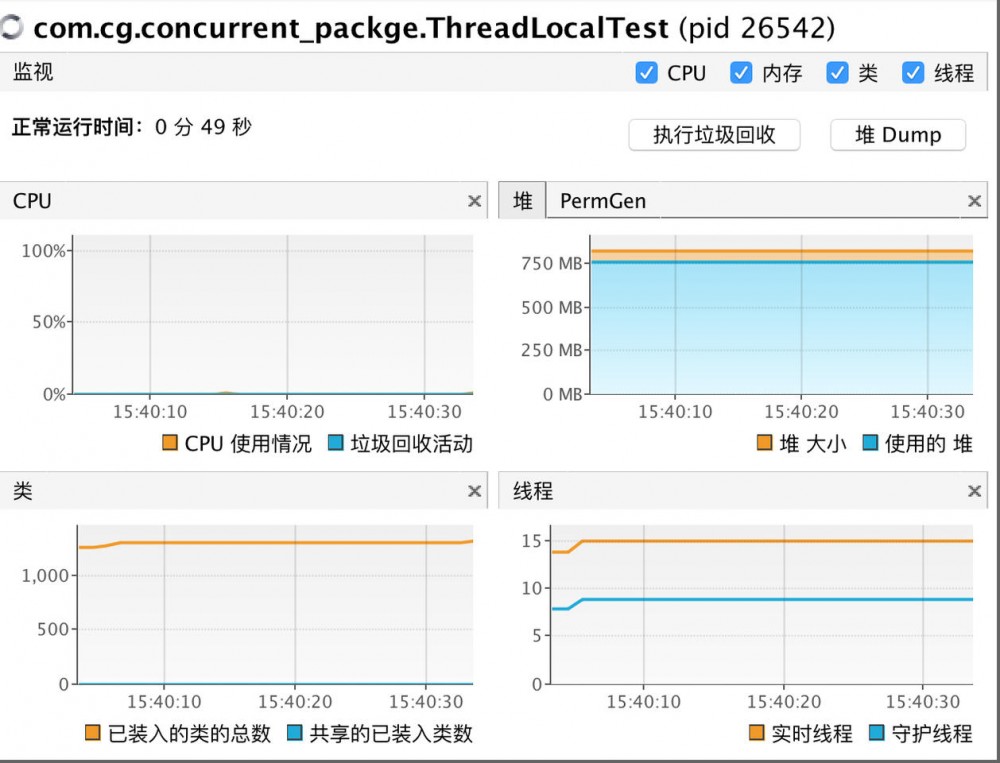
使用的堆的大小是750MB,这符合预期,new出来的MyThreadLocal对象500MB,有五个线程,每个线程50MB,加起来一共750MB。
50秒后,将local置null,这个时候不再有强引用指向new的MyThreadLocal对象,此时执行垃圾回收,结果如下:
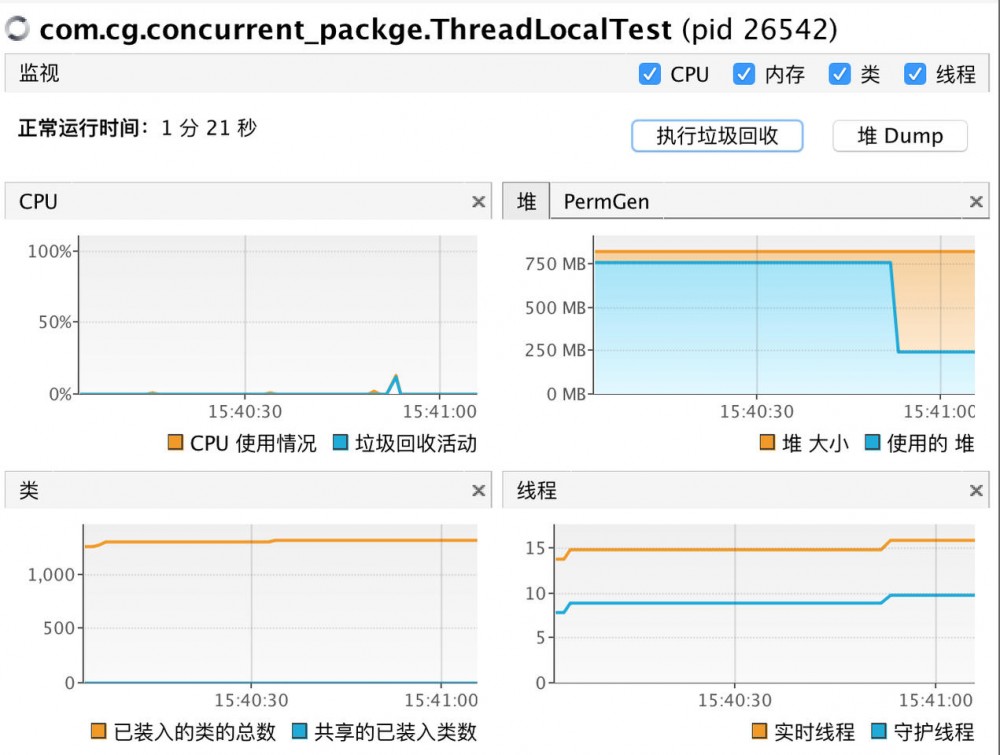
使用的堆大小变为250MB,单就这个结果还不能证明每个线程内对MyThreadLocal对象存在弱引用,但是一定不存在强引用。
之前本人曾研究过线程池的源码,线程池内的线程在执行完一个任务后,并没有销毁,在本例中,它们处于waiting状态,所以,本程序始终维持在250MB大小,得不到释放,一旦将程序中的条件改得足够大,就能出现明显的性能问题。解决的方法通常是在线程内调用ThreadLocal的remove方法,实际上,ThreadLocal提供的公有API并不多,但是这个方法足够解决问题。
小结
不得不说,通过对ThreadLocal的解析,本人收获很多。整篇文章写起来也是一气呵成(所以可能也包藏着错误),估摸着如果以后有对共享变量进行私有设置的需求时,也可以参考这种方法来写;之前对四种引用只是了解,这次算是弄明白怎么运用;用线性探测解决hash表的碰撞冲突,有别于HashMap,也是ThreadLocal的特点;最后列举的内存泄漏,算是对前面写的内容进行了一次实战。
cool.
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

